La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Email de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
L'équipe de recherche du Laboratoire d'intelligence artificielle générative (GAIR Lab) de l'Université Jiao Tong de Shanghai Les principales orientations de recherche sont : la formation, l'alignement et l'alignement de grands modèles. évaluation. Page d'accueil de l'équipe : https://plms.ai/
Dans les 20 prochaines années, l'IA devrait dépasser l'intelligence humaine. Hinton, lauréat du prix Turing, a mentionné dans son interview que « dans les 20 prochaines années, l'IA devrait dépasser le niveau de l'intelligence humaine » et a suggéré que les grandes entreprises technologiques se préparent très tôt à évaluer « l'efficacité » des grands modèles (y compris les modèles multimodaux). grands modèles) Le "niveau d'intelligence" est un prérequis nécessaire à cette préparation.
Un benchmark d'évaluation de la capacité de raisonnement cognitif avec un ensemble de problèmes interdisciplinaires capable d'évaluer rigoureusement l'IA à partir de plusieurs dimensions est devenu très urgent.
1. Les grands modèles continuent d'occuper les hauteurs de l'intelligence humaine : des questions des tests d'école primaire aux examens d'entrée à l'université
L'essor de la technologie de l'intelligence artificielle générative avec de grands modèles comme noyau a permis aux humains de ne pas n'ayant que des textes et des images interactifs, les outils de génération vidéo interactive donnent également aux humains la possibilité de former un modèle doté de capacités « intelligentes ». Il peut être considéré comme un cerveau humain étendu, résolvant indépendamment des problèmes dans différentes disciplines et devenant un modèle capable. accélérer la découverte scientifique au cours des 10 prochaines années, l’outil le plus puissant de (c’est-à-dire AI4Science). Au cours des deux dernières années, nous avons assisté à l'évolution rapide de ce type d'intelligence à base de silicium représentée par de grands modèles. Dès le début, elle ne pouvait être utilisée que pour résoudre des problèmes dans les écoles primaires. al. [1] a pris la première place. Pour la première fois, AI a été amenée à la salle d'examen « College Entry Examination » et a obtenu un score de 134 points au National Paper II English. Cependant, à cette époque, AI était encore. un étudiant en matière partielle qui n'avait pas une bonne compréhension de la logique mathématique. Jusqu'à cette année, l'examen d'entrée à l'université 2024 vient de se terminer. Alors que d'innombrables étudiants travaillent dur lors de cet examen annuel, montrant leurs acquis d'apprentissage au fil des ans, de grands modèles ont également été amenés dans la salle d'examen pour la première fois. toutes les disciplines, et Faire de grands progrès en mathématiques et en sciences. Ici, nous ne pouvons nous empêcher de penser : où est le plafond de l’évolution de l’intelligence artificielle ? Les humains n’ont pas encore résolu le problème le plus difficile. Est-ce que ce sera le plafond de l’IA ?

2. Le plus haut palais de la compétition intellectuelle : de l'examen d'entrée à l'université d'IA aux Jeux olympiques de l'IALes Jeux olympiques quadriennaux arriveront également bientôt. Ce n'est pas seulement l'événement suprême de la compétition sportive. également un symbole de la poursuite et de la percée continues des êtres humains. L'Olympiade thématique est une combinaison parfaite de la profondeur des connaissances et des limites de l'intelligence. Il s'agit non seulement d'une évaluation rigoureuse des résultats académiques, mais aussi d'un défi extrême pour l'agilité de pensée et la capacité d'innovation. Ici, la rigueur de la science et la passion des Jeux Olympiques se rencontrent, façonnant conjointement un esprit de poursuite de l'excellence et de courage pour explorer.
L'Olympiade en question constitue le meilleur lieu pour la confrontation maximale entre l'intelligence humaine et l'intelligence artificielle. Indépendamment de la possibilité de réaliser l'AGI à l'avenir, la participation de l'IA aux Olympiades deviendra une étape nécessaire sur le chemin de l'AGI, car celles-ci examinent les capacités de raisonnement cognitif extrêmement importantes du modèle, et ces capacités se reflètent progressivement dans divers mondes réels complexes. Dans certains scénarios, par exemple, les agents d’IA sont utilisés pour le développement de logiciels, gèrent en coopération des processus décisionnels complexes et font même la promotion du domaine de la recherche scientifique (AI4Science).
 3. Construire une arène olympique orientée vers l'IADans ce contexte, l'équipe de recherche du laboratoire d'intelligence artificielle générative de l'université Jiao Tong de Shanghai (GAIR Lab) a déplacé le grand modèle de la salle d'examen d'entrée à l'université vers un plus stimulant " "Olympic Arena", a lancé un nouveau modèle de référence d'évaluation de la capacité de raisonnement cognitif (y compris un grand modèle multimodal) - OlympicArena. Ce benchmark utilise des questions difficiles de l'Olympiade internationale sur des sujets pour tester de manière exhaustive les capacités de raisonnement cognitif de l'intelligence artificielle dans des domaines interdisciplinaires. OlympicArena couvre les sept matières principales que sont les mathématiques, la physique, la chimie, la biologie, la géographie, l'astronomie et l'informatique, y compris 11 163 questions bilingues en chinois et en anglais provenant de 62 Olympiades internationales (telles que l'OMI, l'IPhO, l'IChO, l'IBO, l'ICPC, etc. .), offrant aux chercheurs Nous fournissons une plate-forme idéale pour une évaluation complète des modèles d’IA. Dans le même temps, à plus long terme, Olympic Arena jouera un rôle incontournable pour que l'IA puisse exercer ses puissantes capacités dans les domaines de la science (AI4Science) et de l'ingénierie (AI4Engineering) à l'avenir, et même promouvoir l’IA pour inspirer la superintelligence au-delà des niveaux humains.
3. Construire une arène olympique orientée vers l'IADans ce contexte, l'équipe de recherche du laboratoire d'intelligence artificielle générative de l'université Jiao Tong de Shanghai (GAIR Lab) a déplacé le grand modèle de la salle d'examen d'entrée à l'université vers un plus stimulant " "Olympic Arena", a lancé un nouveau modèle de référence d'évaluation de la capacité de raisonnement cognitif (y compris un grand modèle multimodal) - OlympicArena. Ce benchmark utilise des questions difficiles de l'Olympiade internationale sur des sujets pour tester de manière exhaustive les capacités de raisonnement cognitif de l'intelligence artificielle dans des domaines interdisciplinaires. OlympicArena couvre les sept matières principales que sont les mathématiques, la physique, la chimie, la biologie, la géographie, l'astronomie et l'informatique, y compris 11 163 questions bilingues en chinois et en anglais provenant de 62 Olympiades internationales (telles que l'OMI, l'IPhO, l'IChO, l'IBO, l'ICPC, etc. .), offrant aux chercheurs Nous fournissons une plate-forme idéale pour une évaluation complète des modèles d’IA. Dans le même temps, à plus long terme, Olympic Arena jouera un rôle incontournable pour que l'IA puisse exercer ses puissantes capacités dans les domaines de la science (AI4Science) et de l'ingénierie (AI4Engineering) à l'avenir, et même promouvoir l’IA pour inspirer la superintelligence au-delà des niveaux humains.

L'équipe de recherche a découvert que tous les grands modèles actuels ne peuvent pas fournir de bonnes réponses dans les Olympiades en question. Même le GPT-4o n'a qu'une précision de 39 % et le GPT-4V n'en a que 33 %, ce qui est loin d'être le meilleur. La ligne de passe (taux de réussite de 60%) est encore assez loin. Les performances de la plupart des grands modèles open source sont encore plus insatisfaisantes. Par exemple, les grands modèles multimodaux puissants actuels tels que LLaVa-NeXT-34B, InternVL-Chat-V1.5, etc., n'ont pas atteint le taux de précision de 20 %. . De plus, la plupart des grands modèles multimodaux ne sont pas capables d'utiliser pleinement les informations visuelles pour résoudre des tâches de raisonnement complexes. C'est également la différence la plus significative entre les grands modèles et les humains (les humains ont tendance à donner la priorité au traitement des informations visuelles). ). Par conséquent, les résultats des tests sur OlympicArena montrent que le modèle est toujours à la traîne par rapport aux humains dans la résolution de problèmes scientifiques et que ses capacités de raisonnement inhérentes doivent encore être continuellement améliorées pour mieux aider la recherche scientifique humaine. 
- Adresse papier : https://arxiv.org/pdf/2406.12753
- Adresse du projet : https://gair-nlp.github.io/OlympicArena/
- Adresse code : https ://github.com/GAIR-NLP/OlympicArena
Caractéristiques d'OlympicArena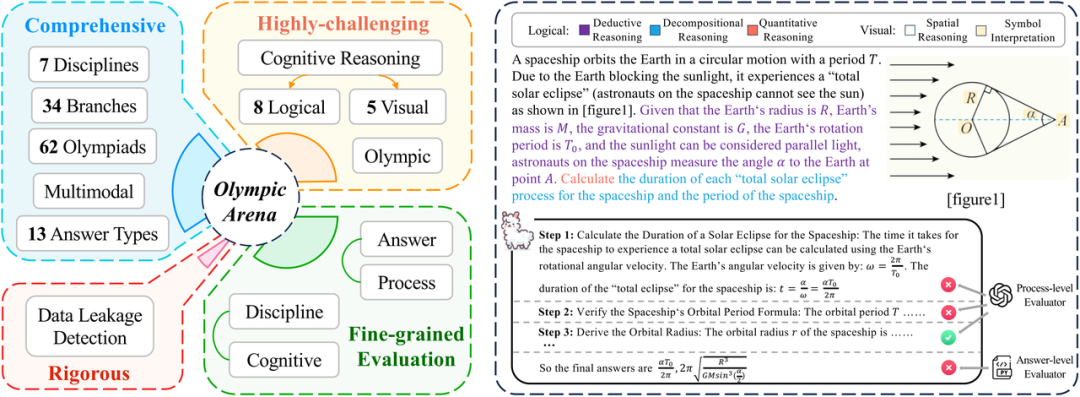
Les caractéristiques d'OlympicArena décrivent son support multimodal, ses multiples examens de capacités cognitives et son évaluation fine ( considérant à la fois l’évaluation du bien et du mal et l’évaluation de chaque étape du raisonnement).
- Complet : OlympicArena comprend un total de 11 163 questions issues de 62 compétitions olympiques différentes, couvrant sept matières principales : mathématiques, physique, chimie, biologie, géographie, astronomie et informatique, impliquant 34 branches professionnelles. Dans le même temps, contrairement aux tests précédents qui se concentraient principalement sur des questions objectives telles que les questions à choix multiples, OlympicArena prend en charge une variété de types de questions, notamment des expressions, des équations, des intervalles, l'écriture d'équations chimiques et même des questions de programmation. De plus, OlympicArena prend en charge la multimodalité (près de la moitié des questions contiennent des images) et adopte un format de saisie (texte-image entrelacé) le plus cohérent avec la réalité, testant pleinement l'utilisation d'informations visuelles pour aider les grands modèles à accomplir leurs tâches. .La capacité de raisonner.
- Extrêmement stimulant : contrairement aux tests de référence précédents qui se concentraient soit sur des questions de lycée (examen d'entrée à l'université), soit sur des questions d'université, OlympicArena se concentre davantage sur l'examen pur des capacités de raisonnement complexes plutôt que sur la connaissance massive de grands modèles de points de mémoire. , capacité de rappel ou capacité d'application simple. Par conséquent, toutes les questions d’OlympicArena sont du niveau de difficulté Olympiade. De plus, afin d'évaluer finement les performances des grands modèles dans différents types de capacités de raisonnement, l'équipe de recherche a également résumé 8 types de capacités de raisonnement logique et 5 types de capacités de raisonnement visuel. Par la suite, ils ont spécifiquement analysé les performances des grands modèles existants. modèles dans différents types de capacités de raisonnement. Différences de performance dans les capacités de raisonnement.
- Rigueur : guider le développement sain des grands modèles est le rôle que le monde universitaire devrait jouer. Actuellement, dans les benchmarks publics, de nombreux grands modèles populaires auront des problèmes de fuite de données (c'est-à-dire que les données de test du benchmark sont divulguées dans le grand modèle) dans les données d'entraînement). Par conséquent, l’équipe de recherche a spécifiquement testé les fuites de données d’OlympicArena sur certains grands modèles populaires afin de vérifier plus rigoureusement l’efficacité du benchmark.
- Évaluation fine : les benchmarks précédents évaluent souvent uniquement si la réponse finale donnée par un grand modèle est cohérente avec la réponse correcte. Ceci est unilatéral dans l'évaluation de problèmes de raisonnement très complexes et ne peut pas bien refléter le modèle actuel. . Des capacités de raisonnement plus réalistes. Par conséquent, en plus d’évaluer les réponses, l’équipe de recherche a également évalué l’exactitude du processus de question (étapes). Dans le même temps, l’équipe de recherche a également analysé différents résultats provenant de plusieurs dimensions différentes, telles que l’analyse des différences de performances des modèles dans différentes disciplines, différentes modalités et différentes capacités de raisonnement.
Comparaison avec des benchmarks associés 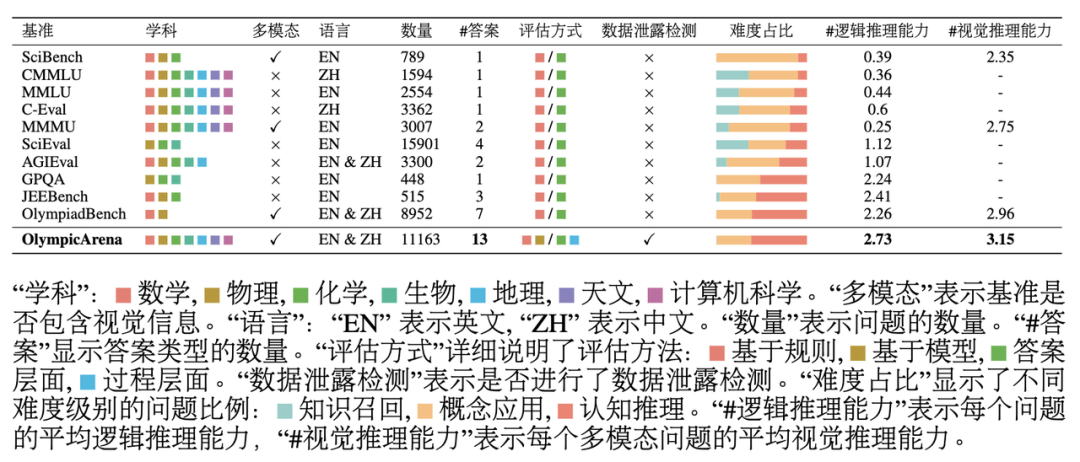
Comme le montre le tableau ci-dessus : OlympicArena a un grand impact sur la capacité de raisonnement en termes de couverture des sujets, des langues et des modalités, ainsi que sur la diversité des types de questions. La profondeur de l’investigation et l’exhaustivité de la méthode d’évaluation sont très différentes des autres références existantes axées sur l’évaluation des questions scientifiques. L'équipe de recherche a testé plusieurs grands modèles multimodaux (LMM) et de grands modèles en texte brut (LLM) sur OlympicArena. . Pour le grand modèle multimodal, la forme de saisie texte-image entrelacée a été utilisée ; pour le grand modèle de texte brut, les tests ont été effectués sous deux paramètres, à savoir la saisie de texte brut sans aucune information d'image (LLM texte uniquement) et simple. saisie de texte contenant des informations de description de l'image (légende de l'image + LLM). Le but de l'ajout de tests sur grands modèles en texte brut n'est pas seulement d'élargir le champ d'application de ce benchmark (afin que tous les LLM puissent participer au classement), mais également de mieux comprendre et analyser les performances des grands modèles multimodaux existants dans leur correspondant Par rapport aux grands modèles de texte pur, s'il peut utiliser pleinement les informations d'image pour améliorer sa capacité de résolution de problèmes. Toutes les expériences ont utilisé des invites CoT sans tir, que l'équipe de recherche a personnalisées pour chaque type de réponse et a spécifié le format de sortie pour faciliter l'extraction des réponses et la correspondance basée sur des règles. La précision de différents modèles dans différents sujets d'OlympicArena Les questions de programmation CS utilisent l'indice pass@k impartial, et les autres utilisent l'indice de précision. Les résultats expérimentaux présentés dans le tableau montrent que tous les grands modèles actuellement sur le marché n'ont pas réussi à afficher un niveau élevé. Même le grand modèle le plus avancé, le GPT-4o, a une précision globale de seulement 39,97 %, tandis que les autres. La précision globale du modèle open source est difficile à atteindre 20 %. Cette différence évidente met en évidence le défi de ce benchmark et prouve qu’il a joué un grand rôle en repoussant la limite supérieure des capacités de raisonnement actuelles de l’IA. De plus, l'équipe de recherche a observé que les mathématiques et la physique restent les deux matières les plus difficiles, car elles reposent davantage sur des capacités de raisonnement complexes et flexibles, comportent plus d'étapes de raisonnement et nécessitent des compétences de réflexion plus complètes et appliquées. Divers. Dans des matières telles que la biologie et la géographie, le taux d'exactitude est relativement élevé, car ces matières accordent davantage d'attention à la capacité d'utiliser de riches connaissances scientifiques pour résoudre et analyser des problèmes pratiques, en se concentrant sur l'examen des capacités d'abduction et de raisonnement causal, par rapport aux matières complexes. induction, raisonnement déductif, les grands modèles sont plus aptes à analyser de tels sujets à l'aide des riches connaissances acquises au cours de leur propre étape de formation. Les concours de programmation informatique se sont également révélés très difficiles, certains modèles open source n'étant même pas capables de résoudre aucun des problèmes qu'ils contiennent (précision 0), ce qui montre à quel point les modèles actuels sont capables de concevoir des algorithmes efficaces pour résoudre problèmes complexes par programmation Il y a encore beaucoup de place à l'amélioration. Il convient de mentionner que l'intention initiale d'OlympicArena n'était pas de poursuivre aveuglément la difficulté des questions, mais d'exploiter pleinement la capacité des grands modèles à traverser les disciplines et à utiliser de multiples capacités de raisonnement pour résoudre des problèmes scientifiques pratiques. La capacité de réflexion mentionnée ci-dessus utilisant un raisonnement complexe, la capacité d'utiliser de riches connaissances scientifiques pour résoudre et analyser des problèmes pratiques et la capacité d'écrire des programmes efficaces et précis pour résoudre des problèmes sont toutes indispensables dans le domaine de la recherche scientifique et ont toujours été la référence pour ce benchmark Focused. Analyse expérimentale à grain finAfin de parvenir à une analyse plus fine des résultats expérimentaux, l'équipe de recherche a mené une évaluation plus approfondie basée sur différentes modalités et capacités de raisonnement. En outre, l'équipe de recherche a également procédé à une évaluation et à une analyse du processus de raisonnement du modèle sur les questions. Les principales conclusions sont les suivantes : Les modèles fonctionnent différemment dans différentes capacités de raisonnement logique et de raisonnement visuel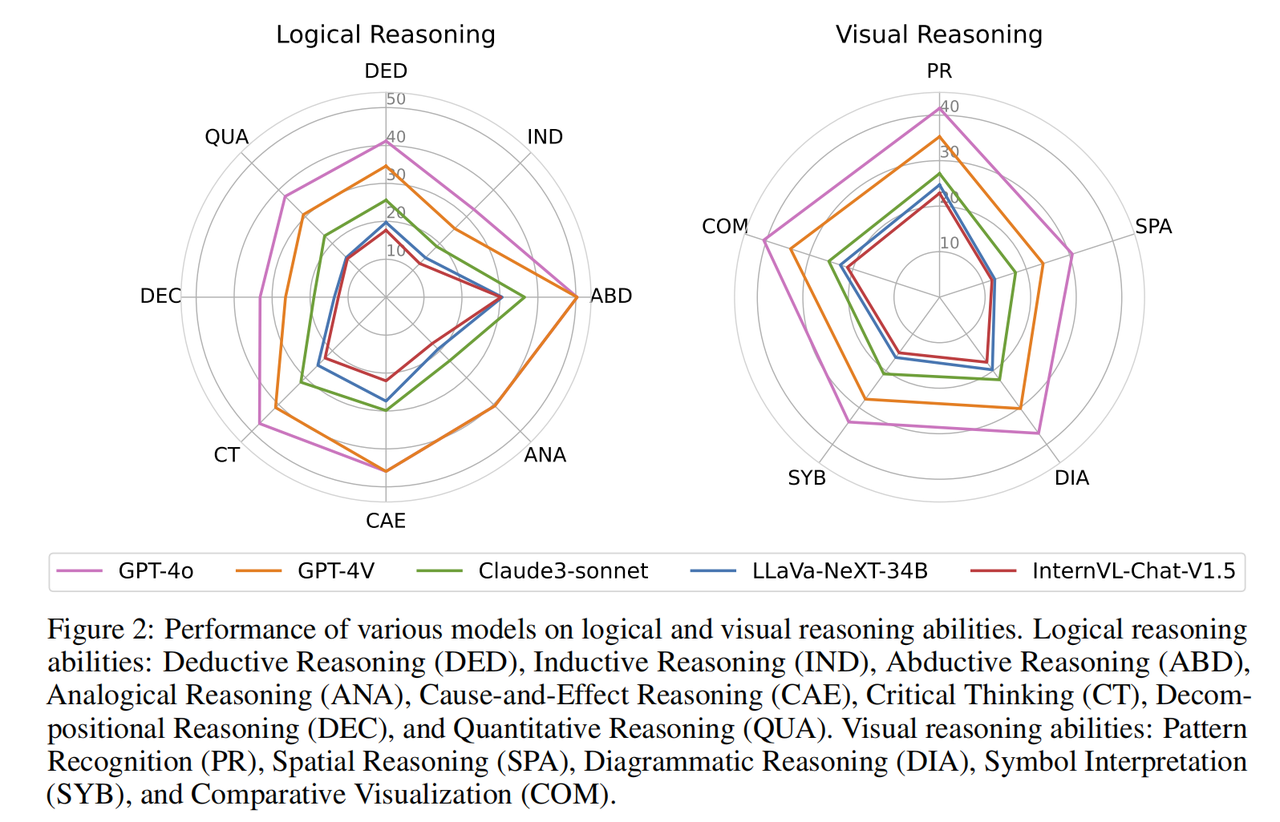
La performance de chaque modèle en matière de raisonnement logique et de capacités de raisonnement visuel. Les capacités de raisonnement logique comprennent : le raisonnement déductif (DED), le raisonnement inductif (IND), le raisonnement abductif (ABD), le raisonnement analogique (ANA), le raisonnement causal (CAE), la pensée critique (CT), le raisonnement de décomposition (DEC) et le raisonnement quantitatif ( EN TANT QUE). Les capacités de raisonnement visuel comprennent : la reconnaissance de formes (PR), le raisonnement spatial (SPA), le raisonnement schématique (DIA), l'interprétation symbolique (SYB) et la comparaison visuelle (COM).
Presque tous les modèles ont des tendances de performances similaires dans différentes capacités de raisonnement logique. Ils excellent dans le raisonnement abductif et causal et sont capables d'identifier les relations de cause à effet à partir des informations fournies. En revanche, le modèle fonctionne mal en raisonnement inductif et en raisonnement par décomposition. Cela est dû à la variété et à la nature non conventionnelle des problèmes de niveau olympique, qui nécessitent la capacité de diviser des problèmes complexes en sous-problèmes plus petits, ce qui s'appuie sur le modèle pour résoudre avec succès chaque sous-problème et combiner les sous-problèmes pour résoudre le problème. problème plus important. En termes de capacités de raisonnement visuel, le modèle a obtenu de meilleurs résultats en matière de reconnaissance de formes et de comparaison visuelle. Cependant, ils ont des difficultés à effectuer des tâches impliquant un raisonnement spatial et géométrique et des tâches qui nécessitent la compréhension de symboles abstraits. D'après l'analyse fine des différentes capacités de raisonnement, les capacités qui manquent aux grands modèles (telles que la décomposition de problèmes complexes, le raisonnement visuel de figures géométriques, etc.) sont des capacités indispensables et cruciales dans la recherche scientifique, ce qui indique qu'il y a encore un long chemin à parcourir. Il reste beaucoup de chemin à parcourir avant que l’IA puisse véritablement aider les humains dans la recherche scientifique sous tous ses aspects. 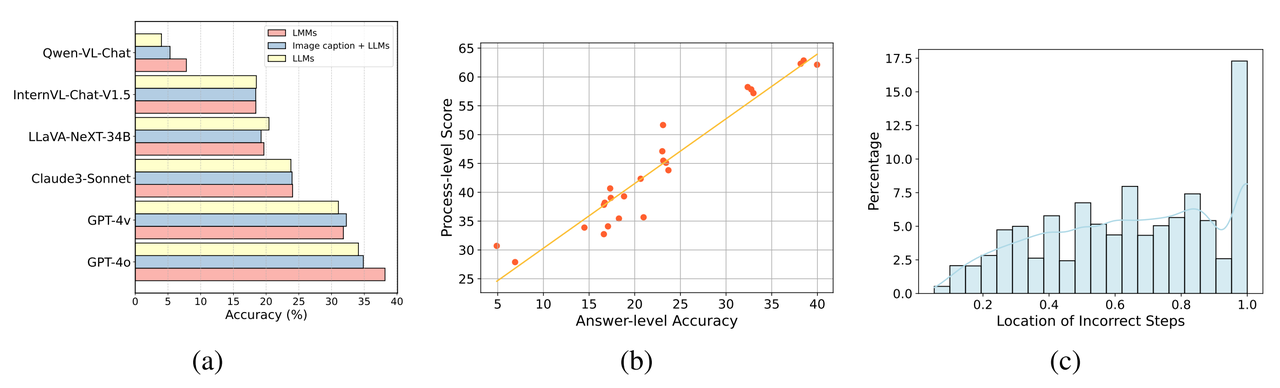
Comparaison de différents modèles multimodaux (LMM) et de leurs modèles textuels uniquement (LLM) correspondants dans trois contextes expérimentaux différents.
La plupart des modèles multimodaux (LMM) ne sont toujours pas efficaces dans l'utilisation d'informations visuelles pour aider au raisonnementComme le montre (a) ci-dessus, il n'existe que quelques grands modèles multimodaux (tels que GPT -4o et Qwen-VL -Chat) montre des améliorations significatives des performances par rapport à son homologue texte uniquement lors de la saisie d'une image. De nombreux grands modèles multimodaux ne montrent pas d’amélioration des performances lors de la saisie d’images, ni même une dégradation des performances lors du traitement des images. Les raisons possibles incluent :
- Lorsque le texte et les images sont saisis ensemble, les LMM peuvent accorder plus d'attention au texte et ignorer les informations contenues dans l'image.
- Certains LMM peuvent perdre certaines de leurs capacités linguistiques inhérentes (par exemple, leurs capacités de raisonnement) lors de la formation de capacités visuelles basées sur leurs modèles de texte, ce qui est particulièrement évident dans les scénarios complexes de ce projet.
- Cette question de référence utilise un format d'entrée complexe d'habillage texte-image. Certains modèles ne prennent pas bien en charge ce format, ce qui entraîne leur incapacité à traiter et à comprendre les informations de position de l'image intégrées dans le texte.
Dans la recherche scientifique, elle est souvent accompagnée d'une très grande quantité d'informations visuelles telles que des graphiques, des figures géométriques et des données visuelles. Ce n'est que lorsque l'IA peut utiliser habilement ses capacités visuelles pour aider au raisonnement qu'elle peut contribuer à promouvoir. L’efficacité et l’innovation de la recherche scientifique sont devenues des outils puissants pour résoudre des problèmes scientifiques complexes. 
Image de gauche : La corrélation entre l'exactitude des réponses et l'exactitude du processus pour tous les modèles dans toutes les questions où le processus d'inférence est évalué. À droite : répartition des emplacements des étapes de processus erronées.
Analyse des résultats de l'évaluation de l'étape d'inférenceEn effectuant une évaluation fine de l'exactitude de l'étape d'inférence du modèle, l'équipe de recherche a découvert :
- Comme le montre (b ) ci-dessus, évaluation par étapes Il existe généralement un degré élevé de concordance entre les résultats et les évaluations qui reposent uniquement sur les réponses. Lorsqu’un modèle génère des réponses correctes, la qualité de son processus d’inférence est généralement meilleure.
- La précision du processus de raisonnement est généralement supérieure à la précision du simple examen des réponses. Cela montre que même pour des problèmes très complexes, le modèle peut exécuter correctement certaines étapes intermédiaires. Par conséquent, les modèles peuvent avoir un potentiel important en matière de raisonnement cognitif, ce qui ouvre de nouvelles directions de recherche aux chercheurs. L’équipe de recherche a également constaté que dans certaines disciplines, certains modèles qui fonctionnaient bien lorsqu’ils étaient évalués uniquement sur la base des réponses donnaient de mauvais résultats lors du processus d’inférence. L'équipe de recherche suppose que cela est dû au fait que les modèles ignorent parfois la plausibilité des étapes intermédiaires lors de la génération de réponses, même si ces étapes ne sont pas essentielles au résultat final.
- De plus, l'équipe de recherche a mené une analyse statistique de la distribution de localisation des étapes d'erreur (voir Figure c) et a constaté qu'une proportion plus élevée d'erreurs se produisaient dans les étapes de raisonnement ultérieures d'une question. Cela montre qu'à mesure que le processus de raisonnement s'accumule, le modèle est plus sujet aux erreurs et produit une accumulation d'erreurs, ce qui montre que le modèle a encore beaucoup de marge d'amélioration lorsqu'il s'agit d'un raisonnement logique à longue chaîne.
L'équipe appelle également tous les chercheurs à accorder plus d'attention à la supervision et à l'évaluation du processus d'inférence de modèle dans les tâches d'inférence d'IA. Cela peut non seulement améliorer la crédibilité et la transparence du système d'IA et aider à mieux comprendre le chemin de raisonnement du modèle, mais également identifier les maillons faibles du modèle dans un raisonnement complexe, guidant ainsi l'amélioration de la structure du modèle et des méthodes de formation. Grâce à une supervision minutieuse du processus, le potentiel de l’IA peut être exploré davantage et son utilisation généralisée dans la recherche scientifique et les applications pratiques peut être encouragée. Analyse des types d'erreurs de modèle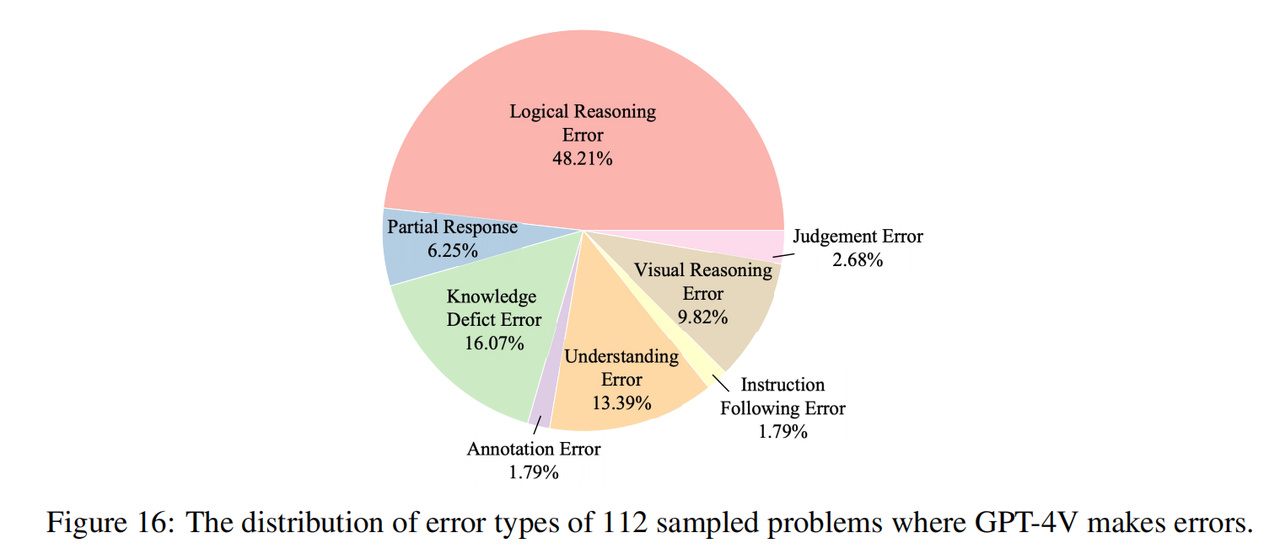
L'équipe de recherche a échantillonné 112 questions avec de mauvaises réponses dans GPT-4V (16 questions dans chaque sujet, dont 8 sont des questions en texte pur et dont 8 sont des questions multimodales), et a marqué manuellement les raisons de ces erreurs. Comme le montre la figure ci-dessus, les erreurs de raisonnement (y compris les erreurs de raisonnement logique et les erreurs de raisonnement visuel) constituent la principale cause d'erreurs, ce qui montre que notre benchmark met effectivement en évidence les lacunes des modèles actuels en termes de capacités de raisonnement cognitif, ce qui est cohérent avec l'intention initiale. de l'équipe de recherche de. De plus, une part considérable des erreurs proviennent également du manque de connaissances (même si les questions de l'Olympiade ne sont basées que sur les connaissances du lycée), ce qui montre que le modèle actuel manque de connaissances dans le domaine et est plus incapable d'utiliser ces connaissances pour aider au raisonnement. Une autre cause fréquente d’erreurs est le biais de compréhension, qui peut être attribué à la mauvaise compréhension du contexte par le modèle et à la difficulté à intégrer des structures linguistiques complexes et des informations multimodales. 
Un exemple de GPT-4V faisant des erreurs sur une question de l'Olympiade mathématique
Détection de fuite de données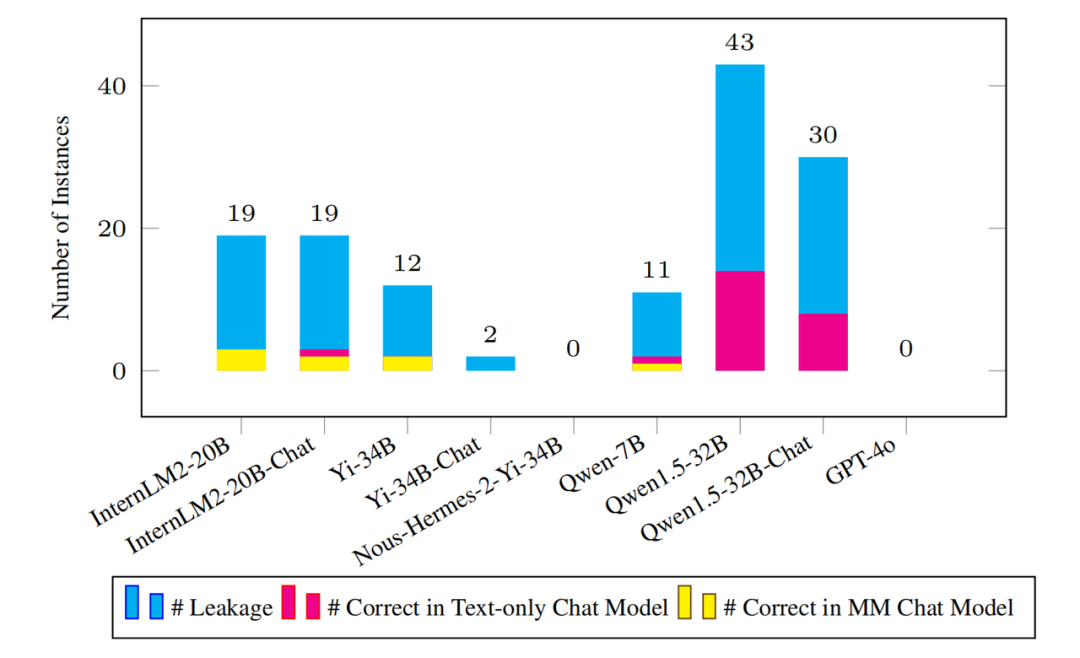
Le nombre d'échantillons divulgués détectés et le texte brut et les modèles multimodaux correspondants sur ces exemples de questions Faites le bon montant.
Alors que l'ampleur du corpus de pré-formation continue de s'étendre, il est crucial de détecter les fuites potentielles de données sur le benchmark. L’opacité du processus de pré-formation rend souvent cette tâche difficile. À cette fin, l’équipe de recherche a adopté une nouvelle mesure de détection des fuites au niveau de l’instance, appelée « précision de prédiction des N-grammes ». Cette métrique échantillonne uniformément plusieurs points de départ de chaque instance, prédit le prochain N-gramme pour chaque point de départ et vérifie si tous les N-grammes prédits sont corrects pour déterminer si le modèle a pu le rencontrer pendant la phase de formation de cette instance. L'équipe de recherche a appliqué cette métrique à tous les modèles de base disponibles. Comme le montre la figure ci-dessus, le modèle grand public ne présente pas de problèmes de fuite de données significatifs sur Olympic Arena. Même s'il y a une fuite, le montant est insignifiant par rapport à l'ensemble complet de données de référence. Par exemple, le modèle Qwen1.5-32B présentant le plus grand nombre de fuites n'a détecté que 43 cas de fuite suspectée. Cela soulève naturellement la question : le modèle peut-il répondre correctement à ces questions d'instance divulguées ? Sur cette question, l'équipe de recherche a été surprise de constater que même pour les questions divulguées, le modèle correspondant pouvait répondre correctement à très peu de questions. Ces résultats indiquent que l'indice de référence n'a subi pratiquement aucun impact en raison de violations de données et qu'il reste assez difficile de maintenir son efficacité pendant une longue période. 
Bien qu'OlympicArena ait une très grande valeur, l'équipe de recherche a déclaré qu'il reste encore beaucoup de travail à faire à l'avenir. Tout d'abord, le benchmark OlympicArena introduira inévitablement des données bruyantes, et l'auteur utilisera activement les commentaires de la communauté pour l'améliorer et l'améliorer continuellement. En outre, l’équipe de recherche prévoit de publier chaque année de nouvelles versions de l’indice de référence afin d’atténuer davantage les problèmes liés aux violations de données. De plus, à plus long terme, les benchmarks actuels se limitent à évaluer la capacité d'un modèle à résoudre des problèmes complexes. À l'avenir, tout le monde espère que l'intelligence artificielle pourra aider à accomplir des tâches complexes et complètes et démontrer sa valeur dans des applications pratiques, telles que AI4Science et AI4Engineering, qui seront le but et le but de la future conception de référence. Malgré cela, Olympic Arena joue toujours un rôle important de catalyseur dans la promotion de l’IA vers la superintelligence. 
Vision : Un moment glorieux de progrès conjoint entre les humains et l'IA
À l'avenir, nous avons des raisons de croire qu'à mesure que la technologie de l'IA continue de mûrir et que les scénarios d'application continuent de se développer, OlympicArena sera plus qu'un simple lieu pour évaluer les capacités de l'IA, deviendra une étape pour démontrer le potentiel d'application de l'IA dans divers domaines. Que ce soit dans la recherche scientifique, la conception technique ou dans des domaines plus larges tels que la compétition sportive, l’IA contribuera à sa manière au développement de la société humaine. Enfin, l'équipe de recherche a également déclaré que le sujet des Jeux olympiques ne serait que le début de l'OlympicArena et que davantage de capacités de l'IA méritent une exploration continue. Par exemple, l'arène sportive olympique deviendra une arène d'intelligence incarnée. à l'avenir. [1] Pré-formation restructurée, arXiv 2022, Weizhe Yuan, Pengfei LiuCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


