
Maison >Périphériques technologiques >IA >Surpassant la méthode CVPR 2024, DynRefer réalise plusieurs SOTA dans des tâches de reconnaissance multimodale au niveau régional
Surpassant la méthode CVPR 2024, DynRefer réalise plusieurs SOTA dans des tâches de reconnaissance multimodale au niveau régional

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-20 20:31:51750parcourir
Afin d'obtenir une compréhension multimodale de haute précision au niveau régional, cet article propose un schéma de résolution dynamique pour simuler le système cognitif visuel humain.
L'auteur de cet article est du laboratoire LAMP de l'Université de l'Académie chinoise des sciences. Le premier auteur Zhao Yuzhong est doctorant à l'Université de l'Académie chinoise des sciences en 2023, et le co-auteur Liu. Feng est doctorant direct à l'Université de l'Académie chinoise des sciences en 2020. Leurs principaux axes de recherche sont les modèles de langage visuel et la perception visuelle des objets.

Titre de l'article : DynRefer : Plonger dans les tâches multimodales au niveau régional via la résolution dynamique Lien de l'article : https://arxiv.org/abs/2405.16071 Code de l'article : https ://github.com/callsys/DynRefer


Méthode
1. Simuler une image à résolution dynamique (construction multi-vues).
 représente la taille de l'image entière et t représente le coefficient d'interpolation. Pendant la formation, nous sélectionnons au hasard n vues parmi les vues candidates pour simuler les images générées par le regard et les mouvements oculaires rapides. Ces n vues correspondent au coefficient d'interpolation t, qui est
représente la taille de l'image entière et t représente le coefficient d'interpolation. Pendant la formation, nous sélectionnons au hasard n vues parmi les vues candidates pour simuler les images générées par le regard et les mouvements oculaires rapides. Ces n vues correspondent au coefficient d'interpolation t, qui est  . Nous conservons fixement la vue contenant uniquement la région de référence (c'est-à-dire
. Nous conservons fixement la vue contenant uniquement la région de référence (c'est-à-dire  ). Il a été prouvé expérimentalement que cette vision aide à préserver les détails régionaux, ce qui est crucial pour toutes les tâches multimodales régionales.
). Il a été prouvé expérimentalement que cette vision aide à préserver les détails régionaux, ce qui est crucial pour toutes les tâches multimodales régionales. 


 . Ceci est illustré sur le côté gauche de la figure 3. Ces incorporations de régions ne sont pas alignées spatialement en raison d'erreurs spatiales introduites par le recadrage, le redimensionnement et RoI-Align. Inspiré par l'opération de convolution déformable, nous proposons un module d'alignement pour réduire le biais en alignant
. Ceci est illustré sur le côté gauche de la figure 3. Ces incorporations de régions ne sont pas alignées spatialement en raison d'erreurs spatiales introduites par le recadrage, le redimensionnement et RoI-Align. Inspiré par l'opération de convolution déformable, nous proposons un module d'alignement pour réduire le biais en alignant 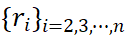 sur
sur  , où
, où  est la région intégrant l'encodage de vue contenant uniquement la région de référence. Pour chaque région intégrant
est la région intégrant l'encodage de vue contenant uniquement la région de référence. Pour chaque région intégrant  , elle est d'abord concaténée avec
, elle est d'abord concaténée avec  puis une carte de décalage 2D est calculée via une couche convolutive. Les caractéristiques spatiales de
puis une carte de décalage 2D est calculée via une couche convolutive. Les caractéristiques spatiales de  sont ensuite rééchantillonnées en fonction du décalage 2D. Enfin, les intégrations de régions alignées sont concaténées le long de la dimension du canal et fusionnées à travers des couches linéaires. La sortie est ensuite compressée via un module de rééchantillonnage visuel, c'est-à-dire Q-former, extrayant ainsi une représentation régionale de la région de référence
sont ensuite rééchantillonnées en fonction du décalage 2D. Enfin, les intégrations de régions alignées sont concaténées le long de la dimension du canal et fusionnées à travers des couches linéaires. La sortie est ensuite compressée via un module de rééchantillonnage visuel, c'est-à-dire Q-former, extrayant ainsi une représentation régionale de la région de référence  de l'image originale x (
de l'image originale x ( sur la figure 3).
sur la figure 3). 
 i ) Étiquette de région d'image génération. Nous utilisons un décodeur de reconnaissance léger basé sur des requêtes pour la génération d'étiquettes de région. Le décodeur
i ) Étiquette de région d'image génération. Nous utilisons un décodeur de reconnaissance léger basé sur des requêtes pour la génération d'étiquettes de région. Le décodeur  est représenté sur la figure 3 (à droite). Le processus de marquage est complété par le calcul de la confiance d'une balise prédéfinie en utilisant la balise comme requête,
est représenté sur la figure 3 (à droite). Le processus de marquage est complété par le calcul de la confiance d'une balise prédéfinie en utilisant la balise comme requête, en une description linguistique.

 . La première vue est corrigée (
. La première vue est corrigée ( ), la vue deux est sélectionnée ou corrigée au hasard.
), la vue deux est sélectionnée ou corrigée au hasard.  des n vues échantillonnées, nous pouvons obtenir une représentation régionale avec des caractéristiques de résolution dynamique. Pour évaluer les propriétés à différentes résolutions dynamiques, nous avons formé un modèle DynRefer à double vue (n = 2) et l'avons évalué sur quatre tâches multimodales. Comme le montre la courbe de la figure 4, la détection d'attributs donne de meilleurs résultats pour les vues sans informations contextuelles (
des n vues échantillonnées, nous pouvons obtenir une représentation régionale avec des caractéristiques de résolution dynamique. Pour évaluer les propriétés à différentes résolutions dynamiques, nous avons formé un modèle DynRefer à double vue (n = 2) et l'avons évalué sur quatre tâches multimodales. Comme le montre la courbe de la figure 4, la détection d'attributs donne de meilleurs résultats pour les vues sans informations contextuelles ( ). Cela peut s'expliquer par le fait que de telles tâches nécessitent souvent des informations régionales détaillées. Pour les tâches de sous-titrage au niveau régional et de sous-titrage dense, une vue riche en contexte (
). Cela peut s'expliquer par le fait que de telles tâches nécessitent souvent des informations régionales détaillées. Pour les tâches de sous-titrage au niveau régional et de sous-titrage dense, une vue riche en contexte ( ) est requise pour bien comprendre la région de référence. Il est important de noter que les vues avec trop de contexte (
) est requise pour bien comprendre la région de référence. Il est important de noter que les vues avec trop de contexte ( ) dégradent les performances de toutes les tâches car elles introduisent trop d'informations non pertinentes pour la région. Lorsque le type de tâche est connu, nous pouvons échantillonner les vues appropriées en fonction des caractéristiques de la tâche. Lorsque le type de tâche est inconnu, nous construisons d'abord un ensemble de vues candidates sous différents coefficients d'interpolation t,
) dégradent les performances de toutes les tâches car elles introduisent trop d'informations non pertinentes pour la région. Lorsque le type de tâche est connu, nous pouvons échantillonner les vues appropriées en fonction des caractéristiques de la tâche. Lorsque le type de tâche est inconnu, nous construisons d'abord un ensemble de vues candidates sous différents coefficients d'interpolation t,  . À partir de l’ensemble candidat, n vues sont échantillonnées via un algorithme de recherche glouton. La fonction objectif de la recherche est définie comme :
. À partir de l’ensemble candidat, n vues sont échantillonnées via un algorithme de recherche glouton. La fonction objectif de la recherche est définie comme :  où
où  représente le coefficient d'interpolation de la i-ème vue,
représente le coefficient d'interpolation de la i-ème vue,  représente la i-ème vue, pHASH (・) représente la fonction de hachage perceptuelle de l'image et
représente la i-ème vue, pHASH (・) représente la fonction de hachage perceptuelle de l'image et  représente le XOR opération. Afin de comparer les informations des vues dans une perspective globale, nous utilisons la fonction "pHASH (・)" pour convertir les vues du domaine spatial vers le domaine fréquentiel, puis les encoder en codes de hachage. Pour cet élément
représente le XOR opération. Afin de comparer les informations des vues dans une perspective globale, nous utilisons la fonction "pHASH (・)" pour convertir les vues du domaine spatial vers le domaine fréquentiel, puis les encoder en codes de hachage. Pour cet élément  , nous réduisons le poids des vues riches en contexte pour éviter d'introduire trop d'informations redondantes.
, nous réduisons le poids des vues riches en contexte pour éviter d'introduire trop d'informations redondantes.





Ligne 1-6 : Une vue multiple dynamique aléatoire est meilleure qu'une vue fixe. Ligne 6-10 : La sélection des vues en maximisant les informations est préférable à la sélection aléatoire des vues. Ligne 10-13 : Des formations multitâches permettent d'apprendre de meilleures représentations régionales.


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- En prenant l'« Exhibition Express », le parc industriel d'intelligence artificielle de Qingdao explore de nouvelles façons d'attirer les investissements
- Article vedette|La demande de puissance de calcul explose sous le boom des grands modèles d'IA : Lingang veut construire une industrie de plusieurs dizaines de milliards, et SenseTime sera le « maître de la chaîne »
- Un robot humanoïde domestique à usage général sera lancé et l'industrie accélérera les percées
- Liu Qiang : Construire la prochaine génération d'écosystème de contenu industriel du métaverse du tourisme culturel sur Internet
- Le développement rapide du système d'exploitation Hongmeng sur divers appareils ouvrira une nouvelle industrie valant des milliards