
 Technology peripheralsAI7262 papers were submitted, ICLR 2024 became a hit, and two domestic papers were nominated for outstanding papers.
Technology peripheralsAI7262 papers were submitted, ICLR 2024 became a hit, and two domestic papers were nominated for outstanding papers.7262 papers were submitted, ICLR 2024 became a hit, and two domestic papers were nominated for outstanding papers.

A total of 5 outstanding paper awards and 11 honorable mentions were selected this year.
ICLR stands for International Conference on Learning Representations. This year is the 12th conference, held in Vienna, Austria, from May 7th to 11th.
In the machine learning community, ICLR is a relatively "young" top academic conference. It is hosted by deep learning giants and Turing Award winners Yoshua Bengio and Yann LeCun. It just held its first session in 2013. However, ICLR quickly gained wide recognition from academic researchers and is considered the top academic conference on deep learning.
This conference received a total of 7262 submitted papers and accepted 2260 papers. The overall acceptance rate was about 31%, which was the same as last year (31.8%). In addition, the proportion of Spotlights papers is 5% and the proportion of Oral papers is 1.2%.


Compared with previous years, whether it is the number of participants or the number of paper submissions, the popularity of ICLR can be said to have greatly improved. .

## Previous ICLR paper data chart
Among the award-winning papers announced recently, the conference selected 5 Outstanding Paper Awards and 11 Honorable Mention Awards.5 Outstanding Paper Awards
Outstanding Paper winners
Paper: Generalization in diffusion models arises from geometry -adaptive harmonic representations

- Paper address: https://openreview.net/pdf?id=ANvmVS2Yr0
- Institution: New York University, Collège de France
- Author: Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, Stéphane Mallat
Thesis: Learning Interactive Real-World Simulators

- Thesis address: https://openreview. net/forum?id=sFyTZEqmUY
- Institutions: UC Berkeley, Google DeepMind, MIT, University of Alberta
- Author: Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, Pieter Abbeel
As shown in Figure 3 below, UniSim can simulate a series of rich actions, such as washing hands, taking bowls, cutting carrots, and drying hands in a kitchen scene; the upper right of Figure 3 shows pressing different switches; the bottom of Figure 3 are two navigation scenarios.

## to correspond to the navigation scene in the lower right corner of Figure 3

## The navigation scenario below 3 right
Thesis: Never Train from Scratch: Fair Comparison of Long-sequence Models Requires Data-Driven Priors

- Paper address: https://openreview.net/forum?id=PdaPky8MUn
- Institution: Tel Aviv University, IBM
- Authors: Ido Amos, Jonathan Berant, Ankit Gupta
Paper: Protein Discovery with Discrete Walk-Jump Sampling

- Paper address: https:// openreview.net/forum?id=zMPHKOmQNb
- Institution: Genentech, New York University
- Author: Nathan C. Frey, Dan Berenberg, Karina Zadorozhny, Joseph Kleinhenz, Julien Lafrance-Vanasse, Isidro Hotzel, Yan Wu, Stephen Ra, Richard Bonneau, Kyunghyun Cho, Andreas Loukas, Vladimir Gligorijevic, Saeed Saremi
Paper: Vision Transformers Need Registers

- ##Paper address: https://openreview.net/ forum?id=2dnO3LLiJ1
- Institution: Meta et al
- Author: Timothée Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski
- This paper identifies artifacts in the feature map of a vision transformer network, which are characterized by high-norm tokens in low-information background regions.
The authors propose key assumptions for why this phenomenon occurs and provide a simple yet elegant solution using additional register tokens to account for these traces, thereby enhancing the model's performance on a variety of tasks. Insights gained from this work could also impact other application areas.
This paper is well written and provides a good example of conducting research: "Identify the problem, understand why it occurs, and then propose a solution."
11 Honorable MentionsIn addition to 5 outstanding papers, ICLR 2024 also selected 11 honorable mentions.
Paper: Amortizing intractable inference in large language models
- Institution: University of Montreal, University of Oxford
- Authors: Edward J Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, Nikolay Malkin
- Paper address: https://openreview.net/forum? id=Ouj6p4ca60
- This paper proposes a promising alternative to autoregressive decoding in large language models from a Bayesian inference perspective, which may inspire subsequent research .
##Institution: DeepMind
- Authors: Ian Gemp, Luke Marris, Georgios Piliouras
- Paper address: https://openreview.net/forum?id=cc8h3I3V4E
- This is a very clearly written paper that contributes significantly to solving the important problem of developing efficient and scalable Nash solvers.
- ##Institution: Peking University, Beijing Zhiyuan Artificial Intelligence Research Institute
- Author: Zhang Bohang Gai Jingchu Du Yiheng Ye Qiwei Hedi Wang Liwei ## Paper address: https://openreview.net/forum?id=HSKaGOi7Ar
- The expressiveness of GNNs is an important topic, and current solutions still have significant limitations. The author proposes a new expressivity theory based on homomorphic counting.
- Author: Ricky T. Q. Chen, Yaron Lipman
- Paper address: https://openreview.net/forum?id=g7ohDlTITL
- This paper discusses the application of general geometry This is a challenging but important problem of generative modeling on manifolds, and a practical and efficient algorithm is proposed. The paper is excellently presented and fully experimentally validated on a wide range of tasks.
- Authors: Shashanka Venkataramanan, Mamshad Nayeem Rizve, Joao Carreira, Yuki M Asano, Yannis Avrithis
- Paper address: https: //openreview.net/forum?id=Yen1lGns2o
- This paper proposes a novel self-supervised image pre-training method by learning from continuous videos. This paper contributes both a new type of data and a method for learning from new data.
- Authors: Yichen Wu, Long-Kai Huang, Renzhen Wang, Deyu Meng, Wei Ying (Ying Wei)
- Paper address: https://openreview.net/forum?id=TpD2aG1h0D
- The author proposes a new meta-continuous learning variance reduction method. The method performs well and not only has practical impact but is also supported by regret analysis.
- Authors: Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao
- Paper address: https:/ /openreview.net/forum?id=uNrFpDPMyo
- This article aims at the KV cache compression problem (this problem has a great impact on Transformer-based LLM) and uses a simple idea to reduce memory. And it can be deployed without extensive resource-intensive fine-tuning or retraining. This method is very simple and has proven to be very effective.
Authors: Yonatan Oren, Nicole Meister, Niladri S. Chatterji, Faisal Ladhak, Tatsunori Hashimoto
Paper address: https://openreview.net/forum?id= KS8mIvetg2
This paper uses a simple and elegant method for testing whether a supervised learning dataset has been included in the training of a large language model.
Author: Jonathan Richens, Tom Everitt
Paper address: https://openreview.net/forum?id=pOoKI3ouv1
This paper was laid down Considerable progress has been made in the theoretical foundations for understanding the role of causal reasoning in an agent's ability to generalize to new domains, with implications for a range of related fields.
Author: Gautam Reddy
Paper address: https://openreview.net/forum?id=aN4Jf6Cx69
This is a timely and extremely systematic study that explores the mechanisms between in-context learning and in-weight learning as we begin to understand these phenomena.
Authors: Germain Kolossov, Andrea Montanari, Pulkit Tandon
Paper address: https://openreview.net/forum?id=HhfcNgQn6p
This paper establishes a statistical foundation for data subset selection and identifies the shortcomings of popular data selection methods.
Paper: Beyond Weisfeiler-Lehman: A Quantitative Framework for GNN Expressiveness
- Institution: Meta
- Institution: University of Central Florida, Google DeepMind, University of Amsterdam, etc.
- Institutions: City University of Hong Kong, Tencent AI Laboratory, Xi'an Jiaotong University, etc.
##Institution: University of Illinois at Urbana-Champaign, Microsoft
Paper: Proving Test Set Contamination in Black-Box Language Models
##Institution: Stanford University, Columbia University
Institution: Google DeepMind
Institution: Princeton University, Harvard University, etc.
Institution: Granica Computing
Reference link: https://blog.iclr.cc/2024/05/06/iclr-2024-outstanding-paper-awards/
The above is the detailed content of 7262 papers were submitted, ICLR 2024 became a hit, and two domestic papers were nominated for outstanding papers.. For more information, please follow other related articles on the PHP Chinese website!

 All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AM
All About Open AI's Latest GPT 4.1 Family - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI unveils the powerful GPT-4.1 series: a family of three advanced language models designed for real-world applications. This significant leap forward offers faster response times, enhanced comprehension, and drastically reduced costs compared t
 What are LLM Benchmarks?Apr 26, 2025 am 10:13 AM
What are LLM Benchmarks?Apr 26, 2025 am 10:13 AMLarge Language Models (LLMs) have become integral to modern AI applications, but evaluating their capabilities remains a challenge. Traditional benchmarks have long been the standard for measuring LLM performance, but with the ra
 7 Tasks Gemini 2.5 Pro Does Better Than Any Other Chatbot!Apr 26, 2025 am 10:00 AM
7 Tasks Gemini 2.5 Pro Does Better Than Any Other Chatbot!Apr 26, 2025 am 10:00 AMAI chatbots are becoming smarter and increasingly sophisticated by the day. Google DeepMind’s latest experimental model, Gemini 2.5 Pro, represents a significant leap forward in AI chatbot capabilities. With improved contex
 6 o3 Prompts You Must Try Today - Analytics VidhyaApr 26, 2025 am 09:56 AM
6 o3 Prompts You Must Try Today - Analytics VidhyaApr 26, 2025 am 09:56 AMOpenAI's o3: A Leap Forward in Reasoning and Multimodal Capabilities OpenAI's o3 model represents a significant advancement in AI reasoning capabilities. Designed for complex problem-solving, analytical tasks, and autonomous tool usage, o3 surpasses
 I Tried Canva Code and Here's How it Went..Apr 26, 2025 am 09:53 AM
I Tried Canva Code and Here's How it Went..Apr 26, 2025 am 09:53 AMCanva Create 2025: Revolutionizing Design with Canva Code and AI Canva's Create 2025 event unveiled significant advancements, expanding its platform into AI-powered tools, enterprise solutions, and, notably, developer tools. Key updates included enh
 AI Chatbot for Tasks: How AI Agents Are Quietly Replacing AppsApr 26, 2025 am 09:50 AM
AI Chatbot for Tasks: How AI Agents Are Quietly Replacing AppsApr 26, 2025 am 09:50 AMThe era of app-hopping for simple tasks is ending. Imagine booking a vacation with a single conversation, or having your bills negotiated automatically. This is the power of AI agents – your new digital assistants who anticipate your needs, not jus
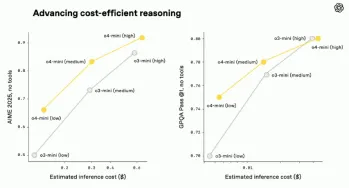 o3 and o4-mini: OpenAI's Most Advanced Reasoning ModelsApr 26, 2025 am 09:46 AM
o3 and o4-mini: OpenAI's Most Advanced Reasoning ModelsApr 26, 2025 am 09:46 AMOpenAI's groundbreaking o3 and o4-mini reasoning models: A giant leap towards AGI Hot on the heels of the GPT 4.1 family launch, OpenAI has unveiled its latest advancements in AI: the o3 and o4-mini reasoning models. These aren't just AI models; the
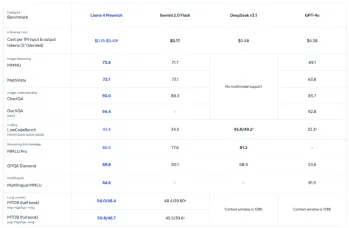 Building an AI Agent with Llama 4 and AutoGenApr 26, 2025 am 09:44 AM
Building an AI Agent with Llama 4 and AutoGenApr 26, 2025 am 09:44 AMHarnessing the Power of Llama 4 and AutoGen to Build Intelligent AI Agents Meta's Llama 4 family of models is transforming the AI landscape, offering native multimodal capabilities to revolutionize intelligent system development. This article explor


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Zend Studio 13.0.1
Powerful PHP integrated development environment

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Notepad++7.3.1
Easy-to-use and free code editor

