
Home >Technology peripherals >AI >Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models
Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models

- PHPzforward
- 2024-04-11 09:43:20948browse
The potential of large language models is stimulated -
High-precision time series prediction can be achieved without training large language models, surpassing all traditional time series models.
Monash University, Ant and IBM Research jointly developed a general framework that successfully promoted the ability of large language models to process sequence data across modalities. The framework has become an important technological innovation.

Time series prediction is beneficial to decision-making in typical complex systems such as cities, energy, transportation, and remote sensing.
Since then, large models are expected to completely change the way of time series/spatiotemporal data mining.
General large language model reprogramming framework
The research team proposed a general framework to easily use large language models for general time series prediction without any training.
Mainly proposes two key technologies: timing input reprogramming; prompt prefixing.
Time-LLM first uses text prototypes (Text Prototypes) to reprogram the input time data, uses natural language representation to represent the semantic information of the time data, and then aligns two different data modalities so that A large language model can understand the information behind another data modality without any modification. At the same time, the large language model does not require any specific training data set to understand the information behind different data modalities. This method not only improves the accuracy of the model, but also simplifies the data preprocessing process.
In order to better handle the analysis of input time series data and corresponding tasks, the author proposed the Prompt-as-Prefix (PaP) paradigm. This paradigm fully activates the processing capabilities of LLM on temporal tasks by adding additional contextual information and task instructions before the representation of temporal data. This method can achieve more refined analysis on timing tasks, and fully activate the processing capabilities of LLM on timing tasks by adding additional contextual information and task instructions in front of the timing data table.
Main contributions include:
- Proposed a new concept of reprogramming large language models for timing analysis without any modification to the backbone language model.
- Propose a general language model reprogramming framework Time-LLM, which involves reprogramming input temporal data into a more natural textual prototype representation, and through declarative prompts (such as domain expert knowledge and task instructions ) to enhance the input context to guide LLM for effective cross-domain reasoning.

- The performance in mainstream prediction tasks consistently exceeds the performance of the best existing models, especially in few-sample and zero-sample scenarios. Furthermore, Time-LLM is able to achieve higher performance while maintaining excellent model reprogramming efficiency. Greatly unlock the untapped potential of LLM for time series and other sequential data.
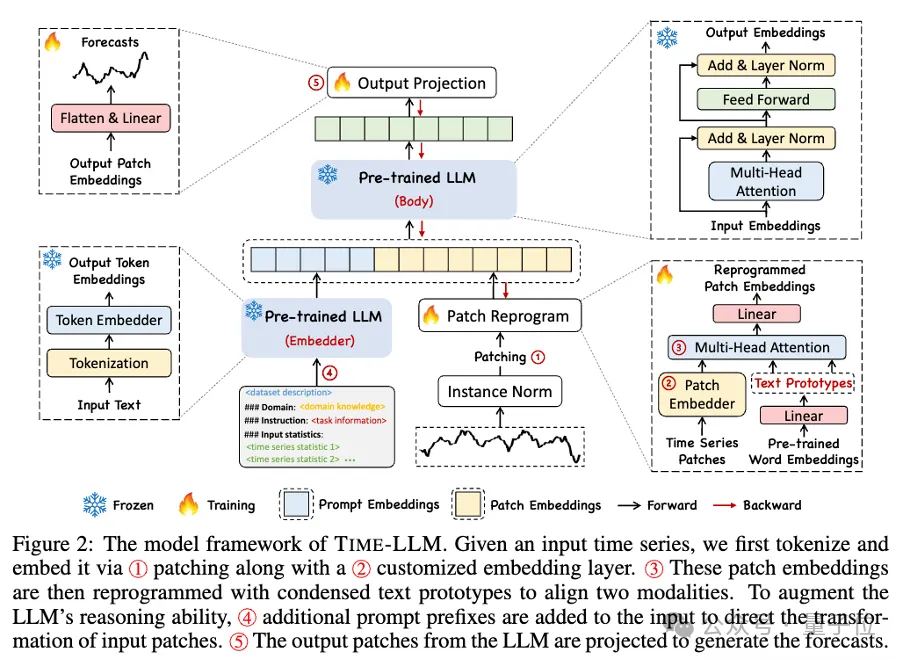
Looking specifically at this framework, first, the input time series data is first normalized by RevIN, and then divided into different patches and mapped to the latent space.
There are significant differences in expression methods between time series data and text data, and they belong to different modalities.
Time series can neither be edited directly nor described losslessly in natural language. Therefore, we need to align temporal input features to the natural language text domain.

A common way to align different modalities is cross-attention, but the inherent vocabulary of LLM is very large, so it is impossible to effectively directly align temporal features to all words. , and not all words have aligned semantic relationships with time series.
In order to solve this problem, this work performs a linear combination of vocabularies to obtain text prototypes. The number of text prototypes is much smaller than the original vocabulary size. The combination can be used to represent the changing characteristics of time series data.
In order to fully activate the ability of LLM in specifying timing tasks, this work proposes a prompt prefix paradigm.
To put it in layman's terms, it means feeding some prior information of the time series data set in a natural language as a prefix prompt, and splicing it with the aligned time series features to LLM. Can it improve the prediction effect?
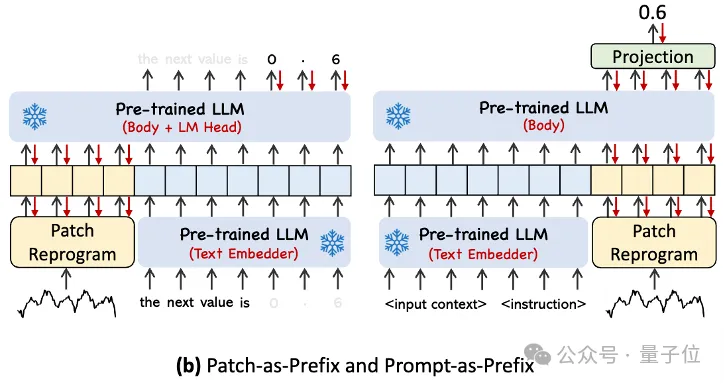
In practice, the authors identified three key components for building effective prompts:
Dataset context; (2) Task instructions to make LLM suitable Equipped with different downstream tasks; (3) Statistical descriptions, such as trends, delays, etc., allow LLM to better understand the characteristics of time series data.

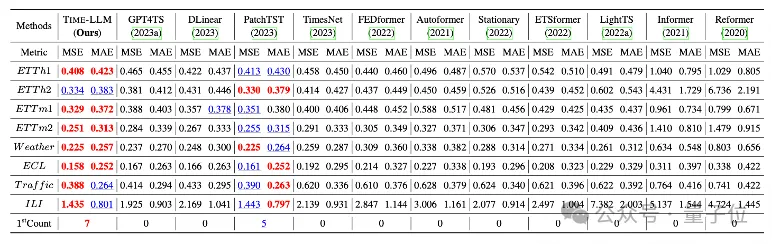
The team conducted comprehensive tests on eight classic public data sets for long-range prediction.
Results Time-LLM significantly exceeded the previous best results in the field in the benchmark comparison. For example, compared with GPT4TS that directly uses GPT-2, Time-LLM has a significant improvement, indicating the effectiveness of this method.
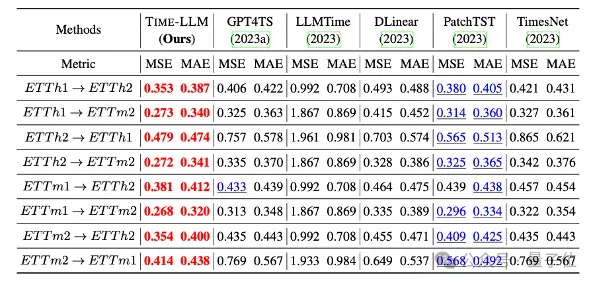
#In addition, it also shows strong prediction ability in zero-shot scenarios.
This project is supported by NextEvo, the AI innovation R&D department of Ant Group’s Intelligent Engine Division.
Interested friends can click on the link below to learn more about the paper~
Paper linkhttps://arxiv.org/abs/2310.01728.
The above is the detailed content of Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- What is artificial intelligence algorithm
- What are the development trends of artificial intelligence?
- C language cannot find identifier when calling function in main
- The impact of artificial intelligence on our lives
- Benchmarking Bing Chat: Baidu Search's small-scale public beta 'conversation” function, based on the Wenxin Yiyan language model