
Home >Technology peripherals >AI >Is Mamba comparable to Transformer effective on time series?
Is Mamba comparable to Transformer effective on time series?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-04-02 11:31:191752browse
Mamba is one of the most popular models recently, and is considered by the industry to have the potential to replace Transformer. The article introduced today explores whether the Mamba model is effective in time series forecasting tasks. This article first introduces the basic principles of Mamba, and then combines this article to explore whether Mamba is effective in time series forecasting scenarios. The Mamba model is a deep learning-based model that uses an autoregressive architecture to capture long-term dependencies in time series data. Compared with traditional models, the Mamba model performs well on time series forecasting tasks. Through experiments and comparative analysis, this paper finds that the Mamba model has good results in time series forecasting tasks. It can accurately predict future time series values and perform better at capturing long-term dependencies. Summary

Paper title: Is Mamba Effective for Time Series Forecasting?
Download address:https://www.php.cn/link /f06d497659096949ed7c01894ba38694
1. Basic principles of Mamba
Mamba is a structure based on State Space Model, but is very similar to RNN. Compared with Transformer, Mamba has a time complexity that increases linearly with the sequence length in both the training phase and the inference phase, and the computing efficiency depends on the structure of Transformer.
The core of Mamba can be divided into the following 4 parts:
State Space Model (SSM) is a method used to describe the impact of a state on the current state, and the impact of the current state on the output mathematical model. In the State Space Model, it is assumed that the input of the previous state and the current moment will affect the next state, and the impact of the current state on the output. SSM can be expressed in the following form, where matrices A, B, C, and D are hyperparameters. Matrix A represents the impact of the previous state on the current state; Matrix B indicates that the input at the current moment will affect the next state; Matrix C represents the impact of the current state on the output; Matrix D represents the direct impact of input on output. By observing the current output and the input at the current moment, the value of the next state can be inferred. It is determined based on the current observation results and the state at that time. SSM can be used in fields such as dynamic system modeling, state estimation, and control applications.
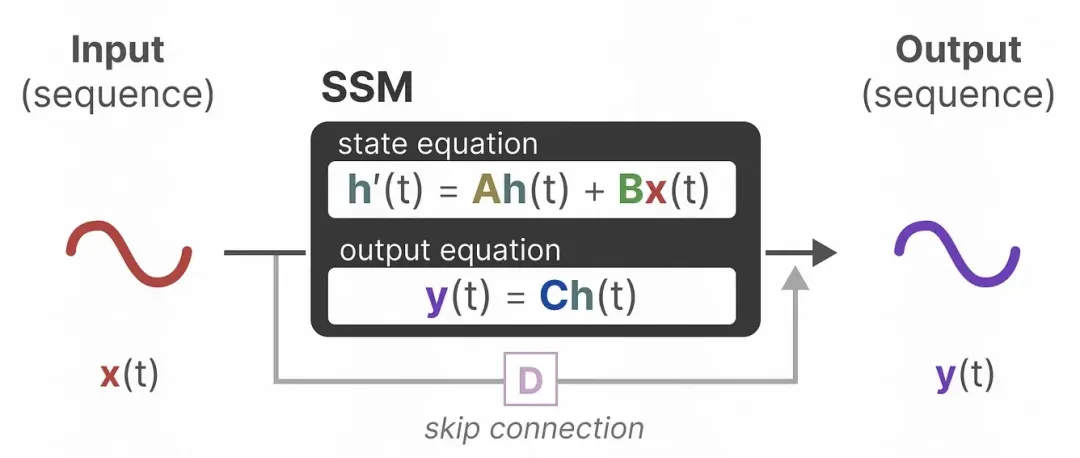 Picture
Picture
Convolution expression: Use convolution to represent SSM to realize concurrent calculation in the training phase. By converting the calculation output formula in SSM according to Time expansion, by designing the corresponding convolution kernel to a certain form, can use convolution to express the output of each moment as a function of the output of the previous three moments:
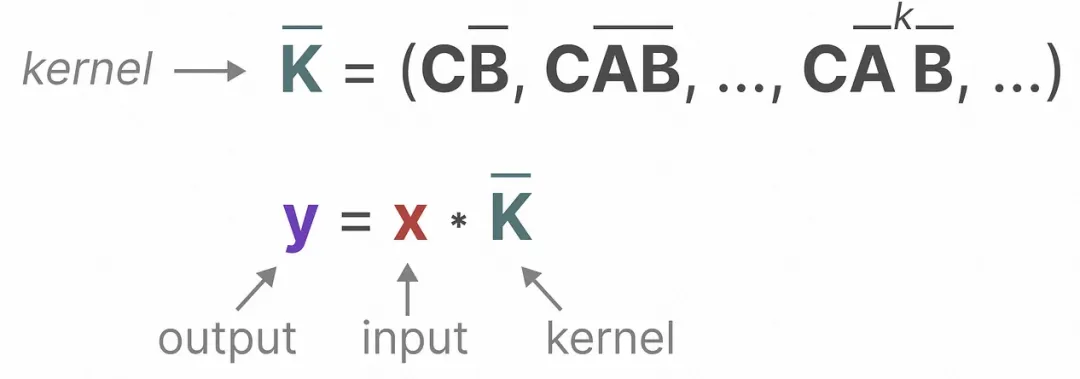 Picture
Picture
Hippo Matrix: For parameter A, Hippo Matrix is introduced to realize attenuation fusion of historical information;
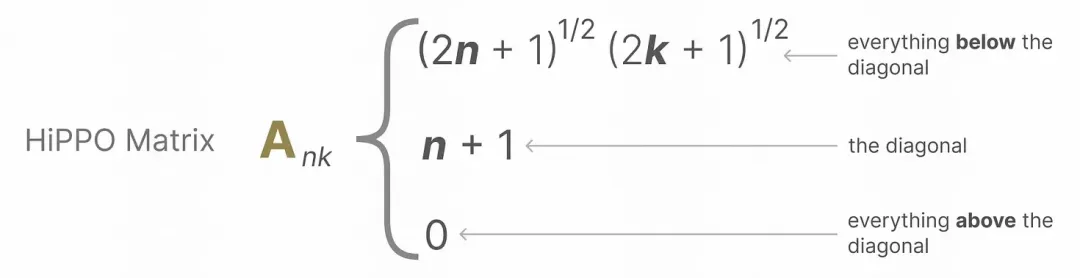 Picture
Picture
Selective module: For the personalized matrix of parameter B and parameter C, the personalized selection of historical information is realized. The parameter matrix at each moment is converted into a function about the input to realize the personalized parameters at each moment.
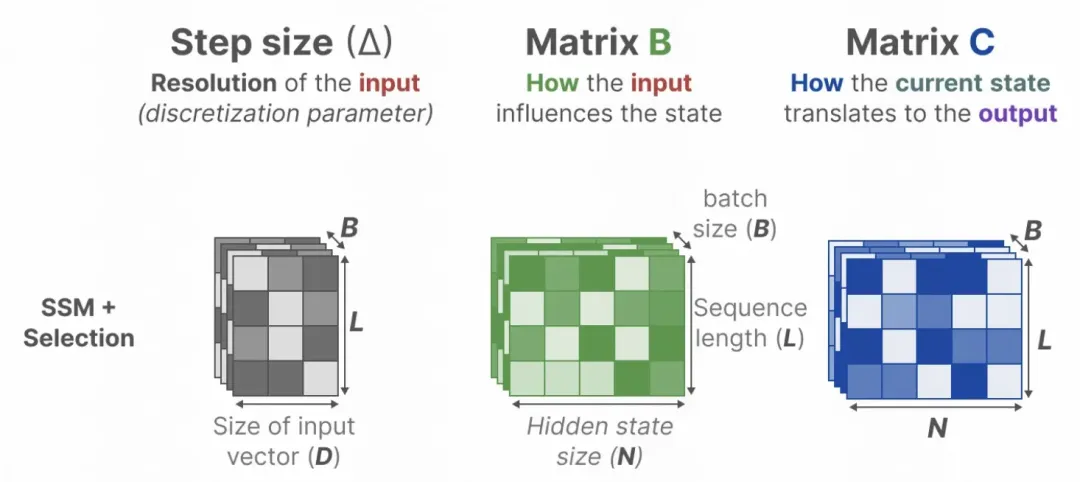 Picture
Picture
More detailed model analysis about Mamba, as well as subsequent Mamba related work, have also been updated to Knowledge Planet. Interested students can Further in-depth learning in the planet.
2. Mamba time series model
The following introduces the Mamba time series prediction framework proposed in this article, which is based on Mamba to adapt time series data. The whole is divided into three parts: Embedding, S/D-Mamba layer, and Norm-FFN-Norm Layer.
Embedding: Similar to the iTransformer processing method, each variable is mapped separately, the embedding of each variable is generated, and then the embedding of each variable is input into the subsequent Mamba. Therefore, this article can also be regarded as a transformation of the iTransformer model structure, changing it to a Mamba structure;
S/D-Mamba layer: The input dimension of Embedding is [batch_size, variable_number, dim], and Input into Mamba. The article explores two Mamba layers, S and D, which respectively indicate whether to use one mamba or two mambas for each layer. The two mambas will add the output of the two to obtain the output result of each layer;
Norm-FFN-Norm Layer: In the output layer, use the normalization layer and FFN layer to normalize and map Mamba's output representation, and combine it with the residual network to improve model convergence and stability.
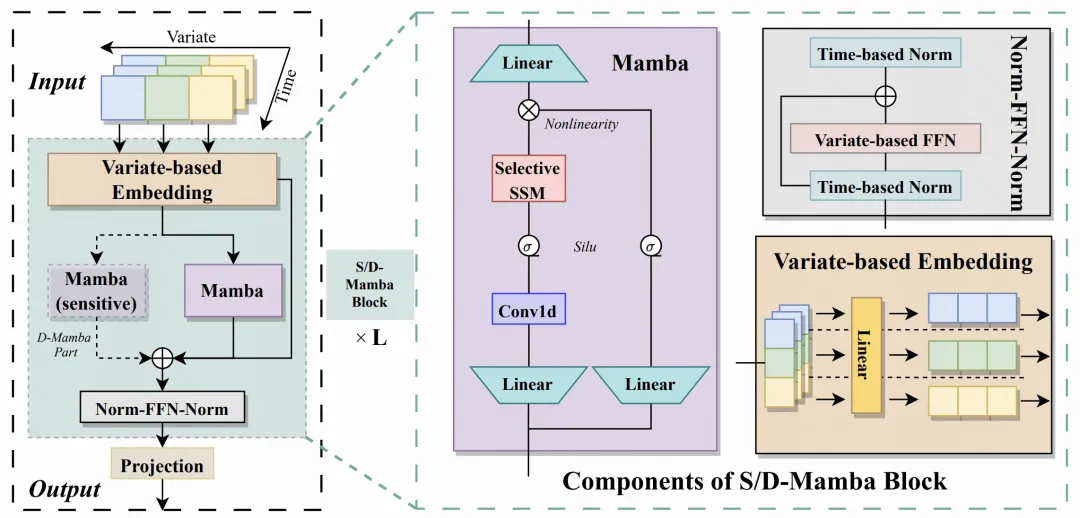 Picture
Picture
3. Experimental results
The following picture is the core experimental result in the article, comparing Mamba with iTransformer, PatchTST and other mainstream time series in the industry model effect. The paper also conducts experimental comparisons on different prediction windows, generalization properties, etc. Experiments show that Mamba not only has advantages in computing resources, but also can compete with Transformer-related models in terms of model effect, and is also promising in long-term modeling.
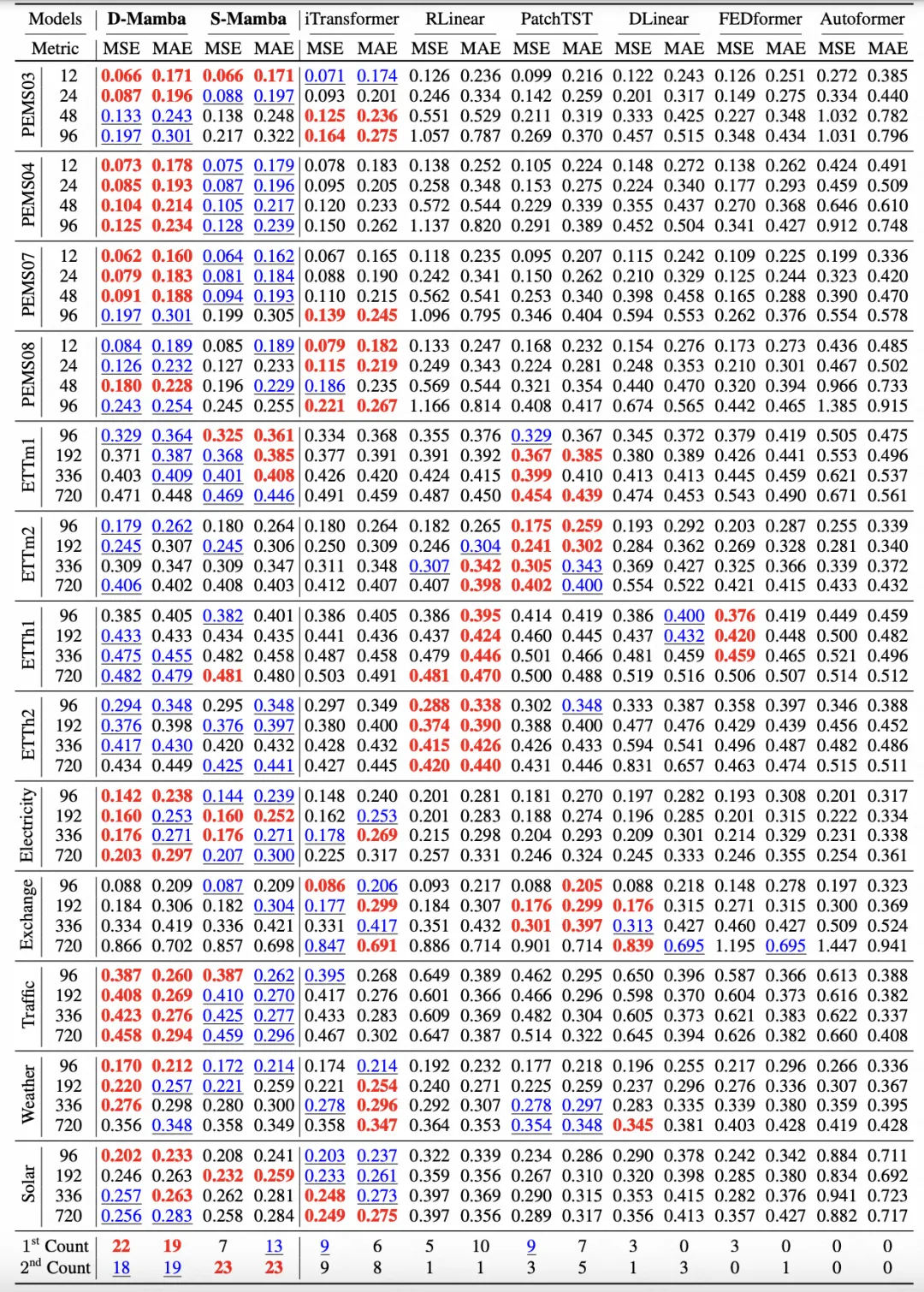 picture
picture
The above is the detailed content of Is Mamba comparable to Transformer effective on time series?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- MoE and Mamba collaborate to scale state-space models to billions of parameters
- Why didn't ICLR accept Mamba's paper? The AI community has sparked a big discussion
- Without dividing it into tokens, learn directly from bytes efficiently. Mamba can also be used in this way.
- RNN model challenges Transformer hegemony! 1% cost and performance comparable to Mistral-7B, supporting 100+ languages, the most in the world