


Alibaba 7B multi-modal document understanding large model wins new SOTA

Multimodal document understandingAbility New SOTA!
The Alibaba mPLUG team released the latest open source workmPLUG-DocOwl 1.5, which proposed a solution for the four major challenges of high-resolution image text recognition, general document structure understanding, instruction compliance, and external knowledge introduction. series of solutions.
Without further ado, let’s look at the effects first.
One-click recognition and conversion of charts with complex structures into Markdown format:

Charts of different styles are available:

More detailed text recognition and positioning can also be easily accomplished:

It can also provide detailed explanations for document understanding:

You must know that "document understanding" is currently an important scenario for the implementation of large language models. There are many products on the market to assist document reading, and some mainly use OCR systems for text recognition and cooperate with LLM for text recognition. Comprehension can achieve good document understanding ability.
However, due to the diverse categories of document pictures, rich text, and complex layout, it is difficult to achieve universal understanding of pictures with complex structures such as charts, infographics, and web pages.
The currently popular multi-modal large models QwenVL-Max, Gemini, Claude3, and GPT4V all have strong document image understanding capabilities. However, open source models have made slow progress in this direction.
Alibaba’s new research mPLUG-DocOwl 1.5 won SOTA on 10 document understanding benchmarks, improved by more than 10 points on 5 data sets, and surpassed Wisdom’s 17.3B CogAgent on some data sets. In DocVQA Achieving an effect of 82.2.

In addition to the ability to answer simple questions on the baseline, DocOwl 1.5-Chat can also have the ability to fine-tune the data with a small amount of "detailed explanation" (reasoning) The ability to explain in detail in the field of multimodal documents has great application potential.
Alibaba’s mPLUG team began to invest in research on multi-modal document understanding in July 2023, and successively released mPLUG-DocOwl, UReader, mPLUG-PaperOwl, mPLUG-DocOwl 1.5, and open sourced a series of large document understanding models. and training data.
This article starts from the latest work mPLUG-DocOwl 1.5, analyzing the key challenges and effective solutions in the field of "multimodal document understanding".
Challenge 1: High-resolution image text recognition
Different from ordinary images, document images are characterized by diverse shapes and sizes, which can include A4-sized document images and short and wide tables. Pictures, long and narrow screenshots of mobile phone web pages, casually shot scene pictures, etc., the resolution distribution is very wide.
When mainstream multi-modal large models encode images, they often directly scale the image size. For example, mPLUG-Owl2 and QwenVL scale to 448x448, and LLaVA 1.5 scales to 336x336.
Simply scaling the document image will cause the text in the image to be blurred and deformed, making it unreadable.
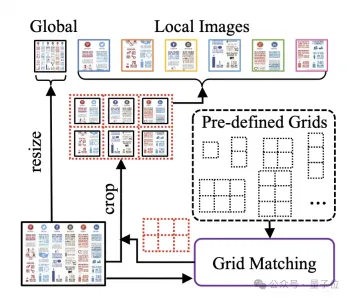
In order to process document images, mPLUG-DocOwl 1.5 continues the cutting method of its pre-process UReader. The model structure is shown in Figure 1:

△Figure 1: DocOwl 1.5 model structure diagram
UReader first proposed based on the existing multi-modal large model, adapting the shape cutting module without parameters(Shape -adaptive Cropping Module) Obtain a series of sub-pictures, each sub-picture is encoded through a low-resolution encoder, and finally the direct semantics of the sub-pictures are associated through a language model.
This graph cutting strategy can make maximum use of the ability of existing general-purpose visual encoders (such as CLIP ViT-14/L) for document understanding, greatly reducing the need to retrain high-resolution Rate visual encoder cost. The shape-adapted cutting module is shown in Figure 2:
△Figure 2: Shape-adaptive cutting module.
Challenge 2: General document structure understanding
For document understanding that does not rely on OCR systems, text recognition is a basic ability. It is very important to achieve semantic understanding and structural understanding of document content, such as To understand the content of the table, you need to understand the correspondence between table headers and rows and columns; to understand charts, you need to understand diverse structures such as line graphs, bar graphs, and pie charts; to understand contracts, you need to understand diverse key-value pairs such as date signatures.
mPLUG-DocOwl 1.5 focuses on solving general document and other structural understanding capabilities. Through the optimization of the model structure and the enhancement of training tasks, it has achieved significantly stronger general document understanding capabilities.
In terms of structure, as shown in Figure 1, mPLUG-DocOwl 1.5 abandons the visual language connection module of Abstractor in mPLUG-Owl/mPLUG-Owl2, adopts H based on "convolutional fully connected layer" -Reducer performs feature aggregation and feature alignment.
Compared with Abstractor based on learnable queries, H-Reducer retains the relative positional relationship between visual features and better transfers document structure information to the language model.
Compared with MLP that retains the length of the visual sequence, H-Reducer greatly reduces the number of visual features through convolution, allowing LLM to understand high-resolution document images more efficiently.
Considering that the text in most document images is arranged horizontally first, and the text semantics in the horizontal direction are coherent, the convolution shape and step size of 1x4 are used in H-Reducer. In the paper, the author proved through sufficient comparative experiments the superiority of H-Reducer in structural understanding and that 1x4 is a more general aggregate shape.
In terms of training tasks, mPLUG-DocOwl 1.5 designs a unified structure learning (Unified Structure Learning) task for all types of pictures, as shown in Figure 3.
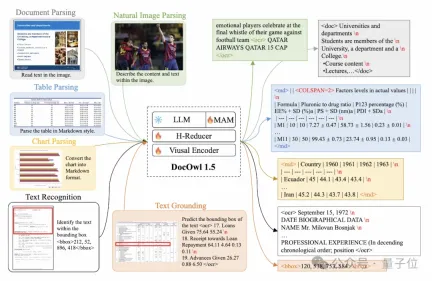
△Figure 3: Unified Structure Learning
Unified Structure Learning includes not only global picture text analysis, but also multi-granularity text recognition and positioning .
In the global image text parsing task, for document images and web page images, spaces and line breaks can be used to most commonly represent the structure of text; for tables, the author introduces multi-line representation based on Markdown syntax. Special characters in multiple columns take into account the simplicity and versatility of table representation; for charts, considering that charts are visual presentations of tabular data, the author also uses tables in the form of Markdown as the analysis target of charts; for natural diagrams, semantic description and Scene text is equally important, so the form of picture description spliced with scene text is used as the analysis target.
In the "Text Recognition and Positioning" task, in order to better fit the understanding of document images, the author designed text recognition and positioning at four granularities of word, phrase, line, and block. The bounding box uses discretized integers. Numerical representation, range 0-999.
In order to support unified structure learning, the author constructed a comprehensive training setDocStruct4M, covering different types of images such as documents/web pages, tables, charts, and natural images.
After unified structure learning, DocOwl 1.5 has the ability to structurally analyze and text position document images in multiple fields.

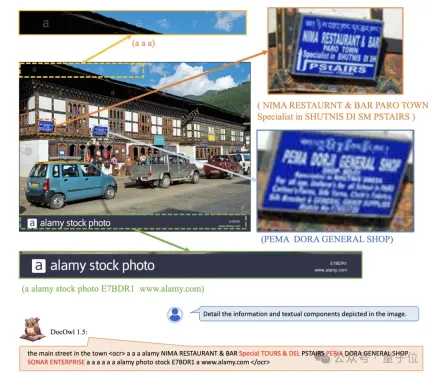
△Figure 4: Structured text analysis
As shown in Figure 4 and Figure 5:
△Figure 5: Multi-granularity text recognition and positioning
Challenge 3: Instruction Following
"Instruction Following"(Instruction Following) Requires the model to be based on basic document understanding capabilities and perform different tasks according to user instructions, such as information extraction, question and answer, picture description, etc.
Continuing the practice of mPLUG-DocOwl, DocOwl 1.5 unifies multiple downstream tasks into the form of command question and answer. After unified structure learning, a document is obtained through multi-task joint training Domain general model(generalist).
In addition, in order to make the model have the ability to explain in detail, mPLUG-DocOwl has tried to introduce plain text instructions to fine-tune data for joint training, which has certain effects but is not ideal.
In DocOwl 1.5, the author built a small amount of detailed explanation data through GPT3.5 and GPT4V based on the problems of downstream tasks (DocReason25K) .
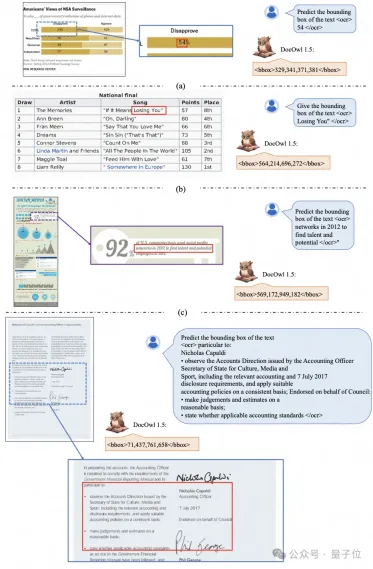
By combining document downstream tasks and DocReason25K for training, DocOwl 1.5-Chat can achieve better results on the benchmark:
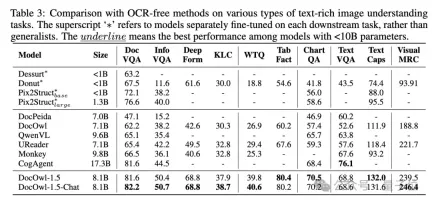
△Figure 6: Document Understanding Benchmark The evaluation
can also give a detailed explanation:

△Figure 7: Detailed explanation of document understanding
Challenge 4: Introduction of external knowledge
Due to the richness of information in document pictures, additional knowledge is often required for understanding, such as professional terms and their meanings in special fields, etc.
In order to study how to introduce external knowledge for better document understanding, the mPLUG team started in the paper field and proposed mPLUG-PaperOwl, building a high-quality paper chart analysis data set M-Paper, involving 447k high-definition papers. chart.
This data provides context for the charts in the paper as an external source of knowledge, and designs "key points" (outline) as control signals for chart analysis to help the model better grasp User intent.
Based on UReader, the author fine-tuned mPLUG-PaperOwl on M-Paper, which demonstrated preliminary paper chart analysis capabilities, as shown in Figure 8.
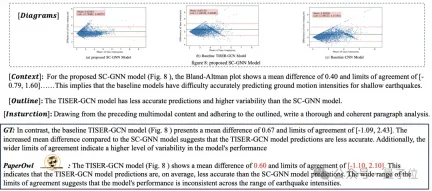
△Figure 8: Paper chart analysis
mPLUG-PaperOwl is currently only an initial attempt to introduce external knowledge into document understanding, and still faces domain limitations, Problems such as a single source of knowledge need to be further resolved.
In general, this article starts from the recently released 7B most powerful multi-modal document understanding large model mPLUG-DocOwl 1.5, and summarizes the four key points for multi-modal document understanding without relying on OCR. Key challenges ("High-resolution image text recognition", "Universal document structure understanding", "Instruction following", "External knowledge introduction") and the solutions provided by Alibaba mPLUG team.
Although mPLUG-DocOwl 1.5 has greatly improved the document understanding performance of the open source model, there is still a large gap between it and the closed source large model and real needs, in terms of text recognition, mathematical calculation, general purpose, etc. in natural scenes. There is still room for improvement.
The mPLUG team will further optimize the performance of DocOwl and open source it. Everyone is welcome to continue to pay attention and have friendly discussions!
GitHub link: https://github.com/X-PLUG/mPLUG-DocOwl
Paper link: https://arxiv.org/abs/2403.12895
The above is the detailed content of Alibaba 7B multi-modal document understanding large model wins new SOTA. For more information, please follow other related articles on the PHP Chinese website!

 Most Used 10 Power BI Charts - Analytics VidhyaApr 16, 2025 pm 12:05 PM
Most Used 10 Power BI Charts - Analytics VidhyaApr 16, 2025 pm 12:05 PMHarnessing the Power of Data Visualization with Microsoft Power BI Charts In today's data-driven world, effectively communicating complex information to non-technical audiences is crucial. Data visualization bridges this gap, transforming raw data i
 Expert Systems in AIApr 16, 2025 pm 12:00 PM
Expert Systems in AIApr 16, 2025 pm 12:00 PMExpert Systems: A Deep Dive into AI's Decision-Making Power Imagine having access to expert advice on anything, from medical diagnoses to financial planning. That's the power of expert systems in artificial intelligence. These systems mimic the pro
 Three Of The Best Vibe Coders Break Down This AI Revolution In CodeApr 16, 2025 am 11:58 AM
Three Of The Best Vibe Coders Break Down This AI Revolution In CodeApr 16, 2025 am 11:58 AMFirst of all, it’s apparent that this is happening quickly. Various companies are talking about the proportions of their code that are currently written by AI, and these are increasing at a rapid clip. There’s a lot of job displacement already around
 Runway AI's Gen-4: How Can AI Montage Go Beyond AbsurdityApr 16, 2025 am 11:45 AM
Runway AI's Gen-4: How Can AI Montage Go Beyond AbsurdityApr 16, 2025 am 11:45 AMThe film industry, alongside all creative sectors, from digital marketing to social media, stands at a technological crossroad. As artificial intelligence begins to reshape every aspect of visual storytelling and change the landscape of entertainment
 How to Enroll for 5 Days ISRO AI Free Courses? - Analytics VidhyaApr 16, 2025 am 11:43 AM
How to Enroll for 5 Days ISRO AI Free Courses? - Analytics VidhyaApr 16, 2025 am 11:43 AMISRO's Free AI/ML Online Course: A Gateway to Geospatial Technology Innovation The Indian Space Research Organisation (ISRO), through its Indian Institute of Remote Sensing (IIRS), is offering a fantastic opportunity for students and professionals to
 Local Search Algorithms in AIApr 16, 2025 am 11:40 AM
Local Search Algorithms in AIApr 16, 2025 am 11:40 AMLocal Search Algorithms: A Comprehensive Guide Planning a large-scale event requires efficient workload distribution. When traditional approaches fail, local search algorithms offer a powerful solution. This article explores hill climbing and simul
 OpenAI Shifts Focus With GPT-4.1, Prioritizes Coding And Cost EfficiencyApr 16, 2025 am 11:37 AM
OpenAI Shifts Focus With GPT-4.1, Prioritizes Coding And Cost EfficiencyApr 16, 2025 am 11:37 AMThe release includes three distinct models, GPT-4.1, GPT-4.1 mini and GPT-4.1 nano, signaling a move toward task-specific optimizations within the large language model landscape. These models are not immediately replacing user-facing interfaces like
 The Prompt: ChatGPT Generates Fake PassportsApr 16, 2025 am 11:35 AM
The Prompt: ChatGPT Generates Fake PassportsApr 16, 2025 am 11:35 AMChip giant Nvidia said on Monday it will start manufacturing AI supercomputers— machines that can process copious amounts of data and run complex algorithms— entirely within the U.S. for the first time. The announcement comes after President Trump si


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

WebStorm Mac version
Useful JavaScript development tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver Mac version
Visual web development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

