

 Technology peripheralsAIStreamingT2V, a long video generator of two minutes and 1200 frames, is here, and the code will be open source
Technology peripheralsAIStreamingT2V, a long video generator of two minutes and 1200 frames, is here, and the code will be open sourceStreamingT2V, a long video generator of two minutes and 1200 frames, is here, and the code will be open source

Wide shot of battlefield, stormtroopers running...

prompt: Wide shot of battlefield, stormtroopers running...
This 2-minute video with 1,200 frames was generated by a text-to-video model. Although the traces of AI are still obvious, the characters and scenes show quite good consistency.
How is this done? You should know that although the generation quality and text alignment quality of Vincent video technology have been quite good in recent years, most existing methods focus on generating short videos (usually 16 or 24 frames in length). However, existing methods that work for short videos often fail to work with long videos (≥ 64 frames).
Even generating short sequences often requires expensive training, such as training steps exceeding 260K and batch sizes exceeding 4500. If you do not train on longer videos and use a short video generator to produce long videos, the resulting long videos are often of poor quality. The existing autoregressive method (generating a new short video by using the last few frames of the short video, and then synthesizing the long video) also has some problems such as inconsistent scene switching.
In order to make up for the shortcomings of existing methods, Picsart AI Research and other institutions jointly proposed a new Vincent video method: StreamingT2V. This method uses autoregressive technology and combines it with a long short-term memory module, which enables it to generate long videos with strong temporal coherence.

- Paper title: StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
- Paper address: https://arxiv.org/abs/2403.14773
- Project address: https://streamingt2v.github.io/
The following is a 600-frame 1-minute video generation result. You can see that bees and flowers have excellent consistency:
Therefore, the team put forward the conditions Attention Module (CAM). CAM uses its attention mechanism to effectively integrate information from previous frames to generate new frames, and can freely handle motion in new frames without being restricted by the structure or shape of previous frames.
In order to solve the problem of appearance changes of people and objects in the generated video, the team also proposed the Appearance Preservation Module (APM): it can start from an initial image (anchor frame) Extract appearance information of objects or global scenes and use this information to regulate the video generation process for all video patches.
To further improve the quality and resolution of long video generation, the team improved a video enhancement model for the autoregressive generation task. To do this, the team selected a high-resolution Vincent video model and used the SDEdit method to improve the quality of 24 consecutive video blocks (with 8 overlapping frames).
To smooth the video block enhancement transition, they also designed a random blending method that blends overlapping enhanced video blocks in a seamless manner.
Method
First, generate a 5 second long 256 × 256 resolution video (16fps), then enhance it to higher resolution (720 × 720). Figure 2 shows its complete workflow.

The long video generation part consists of the Initialization Stage and the Streaming T2V Stage.
Among them, the initialization stage is to use a pre-trained Vincent video model (for example, you can use Modelscope) to generate the first 16-frame video block; while the streaming Vincent video stage is Generate new content for subsequent frames in an autoregressive manner.
For the autoregressive process (see Figure 3), the team’s newly proposed CAM can utilize the short-term information of the last 8 frames of the previous video block to achieve seamless switching between blocks. In addition, they will also use the newly proposed APM module to extract long-term information of a fixed anchor frame, so that the autoregressive process can robustly cope with changes in things and scene details during the generation process.

After generating long videos (80, 240, 600, 1200 or more frames), they then improve them through the Streaming Refinement Stage Video quality. This process uses a high-resolution Vison short video model (e.g., MS-Vid2Vid-XL) in an autoregressive manner, coupled with a newly proposed stochastic mixing method for seamless video block processing. Furthermore, the latter step does not require additional training, which makes this method less computationally expensive.
Conditional attention module
First, use the pre-trained text ( Short) video model is denoted as Video-LDM. The attention module (CAM) consists of a feature extractor and a feature injector injected into Video-LDM UNet.
The feature extractor uses a frame-by-frame image encoder, followed by the same encoder layer used by Video-LDM UNet until the middle layer (and initialized by the weight of UNet ).
For feature injection, the design here is to let each long-range jump connection in UNet focus on the corresponding features generated by CAM through cross attention.
Appearance Preservation Module
The APM module can fix the information in the anchor frame by using to integrate long-term memory into the video generation process. This helps maintain scene and object characteristics during video patch generation.
In order to allow APM to balance the processing of guidance information given by anchor frames and text instructions, the team has made two improvements: (1) Combine the CLIP image token of the anchor frame with the text The CLIP text tokens of the instructions are mixed; (2) A weight is introduced for each cross-attention layer to use cross-attention.
Autoregressive Video Enhancement
To autoregressively enhance the generated video block of 24 frames, here we use High-resolution (1280x720) Vincent (short) video model (Refiner Video-LDM, see Figure 3). This process is done by first adding a large amount of noise to the input video block, and then using this Vincent video diffusion model to perform denoising processing.
However, this method is not enough to solve the problem of transition mismatch between video blocks.
To this end, the team’s solution is a random hybrid approach. Please refer to the original paper for specific details.
Experiment
In the experiment, the evaluation metrics used by the team include: SCuts score for evaluating temporal consistency, Motion-aware twist error (MAWE) for amount of motion and twist error, CLIP text-image similarity score (CLIP) for evaluating text alignment quality, aesthetic score (AE).
Ablation Study
To evaluate the effectiveness of various new components, the team Ablation studies were performed on 75 prompts randomly sampled from the validation set.
CAM for conditional processing: CAM helps the model generate more consistent videos, with SCuts scores 88% lower than other baseline models in comparison.
Long-term memory: Figure 6 shows that long-term memory can greatly help maintain the stability of the characteristics of objects and scenes during the autoregressive generation process.

On a quantitative evaluation metric (person re-identification score), APM achieved a 20% improvement.
Random mixing for video enhancement: Compared with the other two benchmarks, random mixing can bring significant quality improvements, which can also be seen from Figure 4: StreamingT2V can get Smoother transitions.

##StreamingT2V compared to the baseline model
The The team compared the integration of the above-mentioned improved StreamingT2V with multiple models through quantitative and qualitative evaluations, including the image-to-video method I2VGen-XL, SVD, DynamiCrafter-XL, SEINE using the autoregressive method, the video-to-video method SparseControl, and the text-to-long video MethodFreeNoise.
Quantitative evaluation: As can be seen from Table 8, quantitative evaluation on the test set shows that StreamingT2V performs best in terms of seamless video block transition and motion consistency. The MAWE score of the new method is also significantly better than all other methods - even more than 50% lower than the second-best SEINE. Similar behavior is seen in SCuts scores.

In addition, StreamingT2V is only slightly inferior to SparseCtrl in terms of the single-frame quality of the generated video. This shows that this new method is able to generate high-quality long videos with better temporal consistency and motion dynamics than other comparison methods.
Qualitative evaluation: The following figure shows the comparison of the effects of StreamingT2V with other methods. It can be seen that the new method can maintain better consistency while ensuring the dynamic effect of the video.

For more research details, please refer to the original paper.
The above is the detailed content of StreamingT2V, a long video generator of two minutes and 1200 frames, is here, and the code will be open source. For more information, please follow other related articles on the PHP Chinese website!

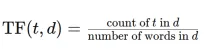 Convert Text Documents to a TF-IDF Matrix with tfidfvectorizerApr 18, 2025 am 10:26 AM
Convert Text Documents to a TF-IDF Matrix with tfidfvectorizerApr 18, 2025 am 10:26 AMThis article explains the Term Frequency-Inverse Document Frequency (TF-IDF) technique, a crucial tool in Natural Language Processing (NLP) for analyzing textual data. TF-IDF surpasses the limitations of basic bag-of-words approaches by weighting te
 Building Smart AI Agents with LangChain: A Practical GuideApr 18, 2025 am 10:18 AM
Building Smart AI Agents with LangChain: A Practical GuideApr 18, 2025 am 10:18 AMUnleash the Power of AI Agents with LangChain: A Beginner's Guide Imagine showing your grandmother the wonders of artificial intelligence by letting her chat with ChatGPT – the excitement on her face as the AI effortlessly engages in conversation! Th
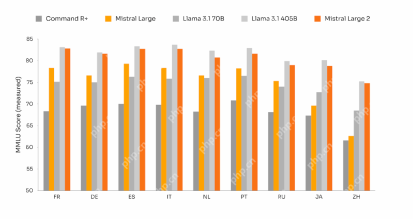 Mistral Large 2: Powerful Enough to Challenge Llama 3.1 405B?Apr 18, 2025 am 10:16 AM
Mistral Large 2: Powerful Enough to Challenge Llama 3.1 405B?Apr 18, 2025 am 10:16 AMMistral Large 2: A Deep Dive into Mistral AI's Powerful Open-Source LLM Meta AI's recent release of the Llama 3.1 family of models was quickly followed by Mistral AI's unveiling of its largest model to date: Mistral Large 2. This 123-billion paramet
 What is Noise Schedules in Stable Diffusion? - Analytics VidhyaApr 18, 2025 am 10:15 AM
What is Noise Schedules in Stable Diffusion? - Analytics VidhyaApr 18, 2025 am 10:15 AMUnderstanding Noise Schedules in Diffusion Models: A Comprehensive Guide Have you ever been captivated by the stunning visuals of digital art generated by AI and wondered about the underlying mechanics? A key element is the "noise schedule,&quo
 How to Build a Conversational Chatbot with GPT-4o? - Analytics VidhyaApr 18, 2025 am 10:06 AM
How to Build a Conversational Chatbot with GPT-4o? - Analytics VidhyaApr 18, 2025 am 10:06 AMBuilding a Contextual Chatbot with GPT-4o: A Comprehensive Guide In the rapidly evolving landscape of AI and NLP, chatbots have become indispensable tools for developers and organizations. A key aspect of creating truly engaging and intelligent chat
 Top 7 Frameworks for Building AI Agents in 2025Apr 18, 2025 am 10:00 AM
Top 7 Frameworks for Building AI Agents in 2025Apr 18, 2025 am 10:00 AMThis article explores seven leading frameworks for building AI agents – autonomous software entities that perceive, decide, and act to achieve goals. These agents, surpassing traditional reinforcement learning, leverage advanced planning and reasoni
 What's the Difference Between Type I and Type II Errors ? - Analytics VidhyaApr 18, 2025 am 09:48 AM
What's the Difference Between Type I and Type II Errors ? - Analytics VidhyaApr 18, 2025 am 09:48 AMUnderstanding Type I and Type II Errors in Statistical Hypothesis Testing Imagine a clinical trial testing a new blood pressure medication. The trial concludes the drug significantly lowers blood pressure, but in reality, it doesn't. This is a Type
 Automated Text Summarization with Sumy LibraryApr 18, 2025 am 09:37 AM
Automated Text Summarization with Sumy LibraryApr 18, 2025 am 09:37 AMSumy: Your AI-Powered Summarization Assistant Tired of sifting through endless documents? Sumy, a powerful Python library, offers a streamlined solution for automatic text summarization. This article explores Sumy's capabilities, guiding you throug


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 English version
Recommended: Win version, supports code prompts!

SublimeText3 Chinese version
Chinese version, very easy to use

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

