

 Computer TutorialsComputer KnowledgeTen Discussions on Linux High-Performance Network Programming
Computer TutorialsComputer KnowledgeTen Discussions on Linux High-Performance Network ProgrammingTen Discussions on Linux High-Performance Network Programming

"Ten Talks on Linux High-Performance Network Programming" has been written for a few months. The ten technical blogs have been written. I thought I would write a summary to review my work in the past few years. In other words, the two experiences in Goose Factory add up. It has been almost 8 years. Although I spend a lot of time working on screws, I still learned a lot from my experience in the evolution of high-performance architecture, from participation, optimization to final design of the architecture.

1. Design in advance or business evolution?
Everyone should have experienced the process of a project from 0 to 1. I would like to ask a question: In many cases, is the architecture evolving with the business or is it designed in advance?
Someone may have studied related architecture books. Most of these books believe that architecture evolves with business development. However, there are also many architects who insist that architecture should be designed in advance. Here, I will not draw conclusions for the time being, but explore the evolution of the architecture through my own experience.
2. From PHP to C
2.1 Simple PHP architecture
PHP, as a simple and convenient language, should be present in all departments of large factories. At that time, I used two languages for work: C and PHP. Using PHP to develop functions is very fast, and there are many mature libraries, so It forms the classic nginx
php-fpm memcache architecture.
 php architecture
php architecture
Under the current architecture, it is not a big problem for a single 8c8g machine to support 1000qps, so for the business, it is currently less than 1wqps. Obviously, a few more machines can support it. Regarding the design of the cache layer, when redis was not yet well developed, memcache was the mainstream cache component at that time, and it was simple for business and docking with PHP. However, with the development of business, according to the calculation curve at that time, it may reach 5wqps within a year. Is it reasonable to use nginx
php-fpm memcache architecture? After discussion, the goal is high performance on the server side, so we started high-performance A journey of discovery.
2.2 Multi-process framework
At that time, in order to implement a high-performance server-side framework, people tried some solutions. One of them was to use the PHP plug-in function to integrate Server functions into the scripting language. This approach achieves the goal of high performance to a certain extent. For example, PHP's swoole is now a development result of this method.
 php-server
php-server
However, there will be some problems that need to be solved here:
- Be familiar with the usage scenarios of PHP extensions and avoid pitfalls
- Memory leak problem in the use of PHP itself
- The cost of troubleshooting when a problem occurs. For example, once a problem occurs, we sometimes need to understand the PHP source code, but when facing hundreds of thousands of lines of code, this cost is quite high
- PHP is simple to use. This is actually relatively true. With the rise of Docker, the stand-alone era will inevitably pass. Can the PHP ecosystem support it?
- …
Based on the above thinking and analysis of business development, it is actually more reasonable for us to implement a server ourselves or use the existing C framework to implement a set of business layer servers. Therefore, after consideration, we adopted the SPP framework within the company. Its architecture is as follows :
 SPP Framework Architecture
SPP Framework Architecture
It can be seen that SPP is a multi-process architecture. Its architecture is similar to Nginx and is divided into Proxy process and Worker process, among which:
- The proxy process uses handle_init to perform initialization, handle_route is forwarded to the worker processing process specified for execution, and handle_input handles the incoming packet of the request
- The worker process uses handle_init to perform initialization, handle_process processes the package and business logic and returns
After using the C architecture, the single-machine performance is directly improved to 6kqps, which basically meets the performance requirements. It can support more businesses on the same machine. It seems that the architecture can be stabilized.
2.3 Introducing coroutines
Using C has met the performance requirements, but there are many problems in development efficiency, such as accessing redis. In order to maintain the high performance of the service, the code logic uses asynchronous callbacks, similar to the following:
... int ret = redis->GetString(k, getValueCallback) ...
GetValueCallback is the callback function. If there are many io operations, the callback here will be very troublesome. Even if it is encapsulated in a similar synchronization method, it will be very troublesome to handle. At that time, std::future and std::async were not introduced.
On the other hand, based on the subsequent qps that may reach 10~20w level, coroutines will also have more advantages in the performance of multi-IO service processing, so we started to transform the coroutine method, replacing all io places with Coroutine calling, for business development, the code becomes like this:
... int ret = redis->GetString(k, value) ...
The value is the return value that can be used directly. Once there is io in the code, the bottom layer will replace io with the API of the coroutine, so that all blocked io operations become synchronization primitives, and the code structure is Development efficiency has been greatly improved (for specific coroutine implementation, please refer to the series of articles "Ten Talks on Linux High-Performance Network Programming | Coroutines").
 Coroutine
Coroutine
There are still not many changes in the architecture. The multi-process coroutine method has supported business development for several years. Although there is no exponential growth in performance, it has gained more experience in high-performance exploration and precipitation.
3. Cloud native
Business continues to develop, and engineers are always pursuing the most cutting-edge concepts. Cloud native, as a popular technology point in recent years, will naturally not be ignored. However, before entering cloud native, if your team does not have a DevOps development concept , this will be a painful process that requires repaying technical debt on architectural design and framework selection.
3.1 Implement DevOps concept
I used to consider high performance when doing architecture. As I understood the architecture, I discovered that high performance is only a small area of architecture design. If you want to build a good architecture, you need more agile processes and service governance concepts. Specific considerations. Summarized as follows:
- Continuous Integration: Developers integrate code into a shared repository multiple times a day, and every isolated change to the code is immediately tested to detect and prevent integration issues
- Continuous Delivery: Continuous Delivery (CD) ensures that each version of code tested in the CI repository can be released at any time
- Continuous deployment: This includes grayscale deployment, blue-green release, etc. The purpose is to quickly iterate. After relatively complete integration testing, grayscale verification can be performed
- Service discovery: Turn services into microservices and simplify calls between services
- RPC framework: The server framework that pursues high performance also needs to consider the support of basic components such as current limiting and circuit breakers
- Monitoring system: Integrate Promethues, OpenTracing and other functions to quickly discover online problems in the agile development process
- Containerization: In order to unify the environment and consider cloud native scenarios in advance, containerization is essential in the development process
- …
 DevOps
DevOps
At this point, you will find that a simple high-performance server has become the goal of the architecture, so it is necessary to re-investigate and design the architecture to successfully implement the DevOps concept.
3.2 Multi-threading
Based on DevOps, combined with the above C Server framework, it is found that multi-process can no longer meet the needs of the architecture. The reasons are as follows:
- Multiple processes are not consistent with the single-process concept of Docker containers
- Working processes have uneven load, how to make better use of multi-cores
- Effective connection with monitoring system
- Business configuration is loaded repeatedly and the configuration center needs to be re-adapted
- It is not very reasonable to use multiple processes to provide stateful services
- …
The business has also grown to one million QPS. In order to better service management and service call costs, we have to consider another architecture:
(1)Research gRPC
 gRPC
gRPC
gRPC is a multi-threaded RPC
Server. It has a mature ecosystem, various middleware, supports multiple languages, etc. It is a good choice for business development from 0 to 1, but it faces challenges for business migration. For example, developing your own middleware adaptation service discovery, configuration center, etc., transforming the protocol according to custom encoding and decoding, how to combine coroutines, etc. Therefore, it can be satisfied for some businesses, but it still needs to be better integrated with the RPC
of components within the company. Server.
(2)Use tRPC
It happened that tRPC was being developed in the company. After research, we found that it basically met the needs, so we tried to adapt the C version of tRPC to our system in the early stages of development. After a series of transformations, the high-performance RPC framework was migrated to the business system. and used the tRPC architecture:
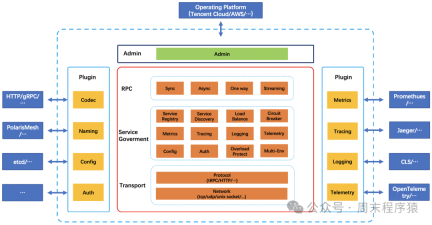
https://trpc.group/zh/docs/what-is-trpc/archtecture_design/
Based on the above considerations and business development, we began to try to unify the RPC Server framework based on high performance to adapt to subsequent RPC diversified scenarios, so we implemented a set of RPC that adapts to our business system
Server’s basic framework:
 New Architecture
New Architecture
3.3, towards k8s
After going through the above selection and transformation, our services can be connected step by step during the migration to k8s. The service can run on its platform without too many transformations, and the connected platforms can also be completed. support.
It seems that we can just pursue newer technologies and wait for the next trend? In fact, there are more challenges at this time. Due to the convenience of the cloud and the disorderly expansion of the migration service architecture, business services and logical levels have become more and more complex. At the same time, the downstream links that a service relies on are getting longer and longer. Although our framework supports link tracking, the longer the link, the controllability and stability of the service will become worse and worse, and it will lead to more waste. A lot of manpower supports daily ops.
what to do?…
Should we merge the business logic and simplify the architecture? The problem here is that when the business logic is complex, the cycle often takes a long time, and the cost is relatively high, and the benefits are not very large
Is it to re-develop a new architecture, keep the decayed ones as they are or discard them, and use a new architecture to adapt to the next development?
The above is the detailed content of Ten Discussions on Linux High-Performance Network Programming. For more information, please follow other related articles on the PHP Chinese website!

 Fixes for ExpressVPN Not Connecting on Windows PC/Mac/iPhone - MiniToolMay 01, 2025 am 12:51 AM
Fixes for ExpressVPN Not Connecting on Windows PC/Mac/iPhone - MiniToolMay 01, 2025 am 12:51 AMIs ExpressVPN not connecting on iPhone, Android phone, Mac, or Windows PC? What should you do if ExpressVPN won’t connect or work? Take it easy and go to find solutions from this post. Here, php.cn collects multiple ways to solve this internet issue.
 Targeted Solutions for 100% GPU Usage on Windows 10/11May 01, 2025 am 12:50 AM
Targeted Solutions for 100% GPU Usage on Windows 10/11May 01, 2025 am 12:50 AMIs 100% GPU usage bad? How to fix 100% GPU usage in Windows 10? Don’t fret. php.cn Website provides you with this article to work out high GPU issues. Those methods are worth a try if you are undergoing 100% GPU usage.
 How to Download/Install/Add/Remove/Disable Add-ins in Word - MiniToolMay 01, 2025 am 12:49 AM
How to Download/Install/Add/Remove/Disable Add-ins in Word - MiniToolMay 01, 2025 am 12:49 AMYou can use add-ins in Microsoft Word to get more features. This post introduces how to download, install, add or remove add-ins in Microsoft Word. A free file recovery method is also provided to help you recover deleted/lost Word or any other files.
 Fix the System Backup Error Codes 0x807800A1 & 0X800423F3 - MiniToolMay 01, 2025 am 12:48 AM
Fix the System Backup Error Codes 0x807800A1 & 0X800423F3 - MiniToolMay 01, 2025 am 12:48 AMSome people find the system backup error codes 0x807800A1 & 0X800423F3 when they attempt to create a system backup. These codes will prevent you from doing any backup tasks. Don’t worry! This article on php.cn Website will teach you how to fix th
 Windows 10 Enterprise ISO Download/Install, Easy Guide to LearnMay 01, 2025 am 12:47 AM
Windows 10 Enterprise ISO Download/Install, Easy Guide to LearnMay 01, 2025 am 12:47 AMWant to get an ISO file of Windows 10 Enterprise to install it for business usage? Windows 10 Enterprise ISO download & install are easy and php.cn will show you how to download Windows 10 Enterprise ISO 20H2, 21H1, or 21H2 via some direct downlo
 NordVPN Not Working on Windows 11: Here Are Easy Fixes - MiniToolMay 01, 2025 am 12:46 AM
NordVPN Not Working on Windows 11: Here Are Easy Fixes - MiniToolMay 01, 2025 am 12:46 AMNordVPN not connecting or working on your Windows 11 computer? Do you know the reasons for this issue? If you want to solve this problem, do you know what you should do? If you have no idea, you come to the right place. In this post, php.cn Software
 Is Twitter Down? How to Check It? How to Fix It? Read This Post! - MiniToolMay 01, 2025 am 12:45 AM
Is Twitter Down? How to Check It? How to Fix It? Read This Post! - MiniToolMay 01, 2025 am 12:45 AMNowadays, Twitter becomes more and more popular all over the world. However, sometimes you may find it is not working properly. Is Twitter down? How to check it? How to fix it? This post from php.cn provides details for you.
 Redfall Release Date, Trailers, Pre-Order, and Latest News - MiniToolMay 01, 2025 am 12:44 AM
Redfall Release Date, Trailers, Pre-Order, and Latest News - MiniToolMay 01, 2025 am 12:44 AMWhen does Redfall come to market? Redfall fans can’t wait to try this game. fortunately, the release date has been clarified and more information we know about Redfall will be all disclosed in this article on php.cn Website, so if you are interested,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

Atom editor mac version download
The most popular open source editor

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 English version
Recommended: Win version, supports code prompts!

