
Home >Technology peripherals >AI >Designed for training Llama 3, Meta 49,000 H100 cluster details announced
Designed for training Llama 3, Meta 49,000 H100 cluster details announced

- PHPzforward
- 2024-03-15 11:30:111296browse
Generative large models have caused major changes in the field of artificial intelligence. Although people's hopes for achieving general artificial intelligence (AGI) are growing, the computing power required to train and deploy large models is also becoming more and more important. The hair is huge.
Just now, Meta announced the launch of two 24k GPU clusters (a total of 49152 H100s), marking Meta’s major investment in the future of artificial intelligence.
This is part of Meta’s ambitious infrastructure plan. By the end of 2024, Meta plans to expand its infrastructure to include 350,000 NVIDIA H100 GPUs, which will give it the computing power equivalent to nearly 600,000 H100s. Meta is committed to continuously expanding its infrastructure to meet future needs.
Meta emphasized: "We firmly support open computing and open source technology. We have built these computing clusters on the basis of Grand Teton, OpenRack and PyTorch and will continue to promote the entire industry Open innovation. We will use these computing resource clusters to train Llama 3."
Yann LeCun, Turing Award winner and Meta chief scientist, also tweeted to emphasize this point.
Meta shared details on the hardware, network, storage, design, performance and software of the new cluster, which is designed to provide high throughput and high reliability for a variety of artificial intelligence workloads sex.
Cluster Overview
Meta’s long-term vision is to build open and responsible general artificial intelligence so that it can be widely used and used by everyone. Benefited from.
In 2022, Meta shared for the first time details of an AI Research Super Cluster (RSC) equipped with 16,000 NVIDIA A100 GPUs. RSC played an important role in the development of Llama and Llama 2, as well as in the development of advanced artificial intelligence models in computer vision, NLP, speech recognition, image generation, encoding, and more.
Meta’s latest AI cluster is built on the successes and lessons learned from the previous phase. Meta emphasizes its commitment to building a comprehensive artificial intelligence system and focuses on improving the experience and work efficiency of researchers and developers.
The high-performance network fabric used in the two new clusters, combined with critical storage decisions and 24,576 NVIDIA Tensor Core H100 GPUs in each cluster, allows the two clusters to support Larger and more complex model than RSC cluster.
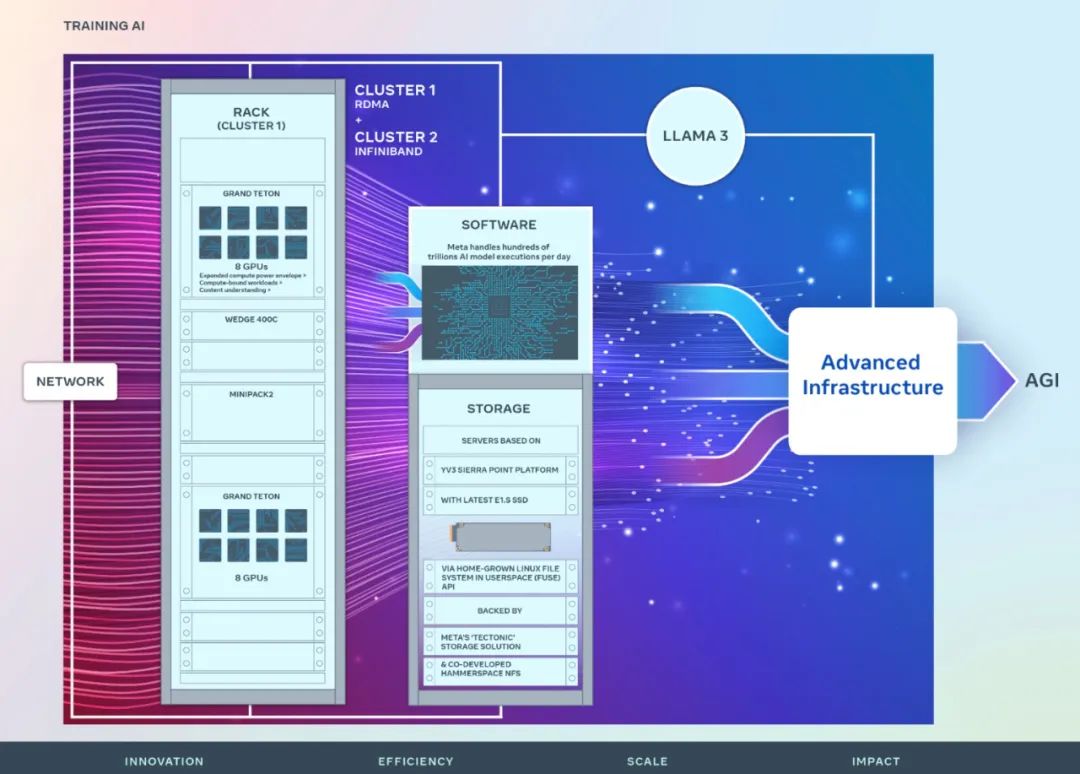
Network
Meta processes hundreds of trillions of artificial intelligence every day Run the model. Serving AI models at scale requires highly advanced and flexible infrastructure.
To optimize the end-to-end experience for artificial intelligence researchers while ensuring that Meta’s data center operates efficiently, Meta built a RoCE-based RoCE based on the Arista 7800 and Wedge400 and Minipack2 OCP rack switches. protocol, a cluster network communication protocol that implements remote direct memory access (RDMA) over Ethernet. The other cluster uses an NVIDIA Quantum2 InfiniBand fabric. Both solutions interconnect 400 Gbps endpoints.
These two new clusters can be used to evaluate the suitability and scalability of different types of interconnections for large-scale training, helping Meta understand how to design and build larger-scale clusters in the future. Through careful co-design of network, software, and model architecture, Meta successfully leveraged RoCE and InfiniBand clusters for large GenAI workloads without any network bottlenecks.
Computing
Both clusters were built using Grand Teton, which was designed in-house by Meta Open GPU hardware platform.
Grand Teton is based on multi-generation artificial intelligence systems and integrates power, control, compute and fabric interfaces into a single chassis for better overall performance, signal integrity and Thermal performance. It provides rapid scalability and flexibility in a simplified design, allowing it to be quickly deployed into data center fleets and easily maintained and expanded.
Storage
Storage plays an important role in artificial intelligence training, but is the least talked about aspect one.
Over time, GenAI training efforts have become more multimodal, consuming large amounts of image, video, and text data, and the demand for data storage has grown rapidly.
Meta's storage deployment of the new cluster meets the data and checkpoint needs of the AI cluster through the local Linux file system (FUSE) API in user space, which is powered by Meta's "Tectonic" Distributed storage solutions provide support. This solution enables thousands of GPUs to save and load checkpoints in a synchronous manner, while also providing the flexible and high-throughput exabyte-scale storage required for data loading.
Meta is also working with Hammerspace to develop and implement parallel Network File System (NFS) deployments. Hammerspace enables engineers to perform interactive debugging of jobs using thousands of GPUs.
Performance
Meta One of the principles for building large-scale artificial intelligence clusters is to simultaneously maximize performance and Ease of use. This is an important principle for creating best-in-class AI models.
Meta When pushing the limits of artificial intelligence systems, the best way to test the ability to scale your designs is to simply build a system, then optimize it and actually test it (while simulators are helpful, so are It can only go so far).
In this design, Meta compared the performance of small clusters and large clusters to understand where the bottlenecks are. The following shows the collective AllGather performance (expressed as normalized bandwidth on a scale of 0-100) when a large number of GPUs communicate with each other at the communication size with the highest expected performance.
Out-of-the-box performance of large clusters is initially poor and inconsistent compared to optimized small cluster performance. To address this issue, Meta made some changes to the way the internal job scheduler is tuned with network topology awareness, which brings latency benefits and minimizes traffic to the upper layers of the network.
Meta also optimizes network routing policies in conjunction with NVIDIA Collective Communications Library (NCCL) changes for optimal network utilization. This helps drive large clusters to achieve the same expected performance as smaller clusters.
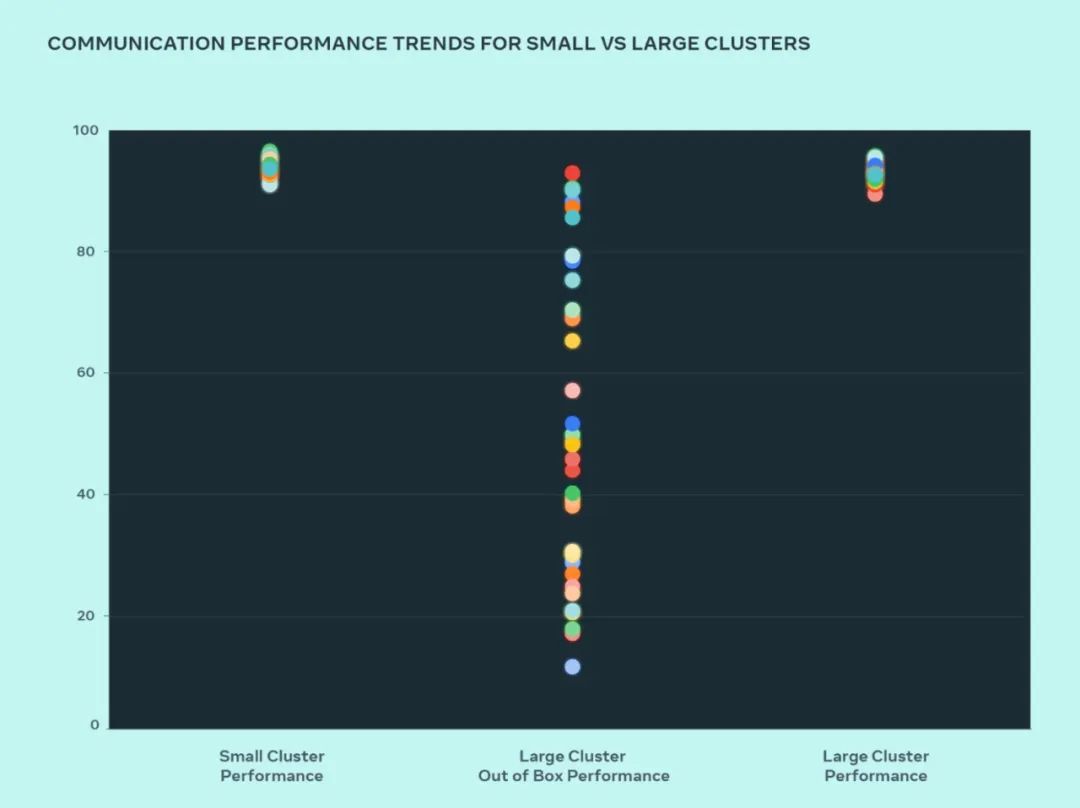
We can see from the figure that the small cluster performance (overall communication bandwidth and utilization) reaches 90% out of the box, but the unoptimized large cluster performance utilization is very low, from 10% to 90% % varies. After optimizing the entire system (software, network, etc.) we saw large cluster performance return to the ideal 90% range.
In addition to software changes to internal infrastructure, Meta works closely with the teams that write training frameworks and models to adapt to evolving infrastructure. For example, the NVIDIA H100 GPU opens up the possibility of training with new data types such as 8-bit floating point (FP8). Taking full advantage of larger clusters requires investments in additional parallelization techniques and new storage solutions, which provides the opportunity to highly optimize checkpoints at thousands of levels to run in hundreds of milliseconds.
Meta also recognizes that debuggability is one of the main challenges of training at scale. Identifying errant GPUs that stall the entire training is difficult at scale. Meta is building tools like asynchronous debugging or distributed collective flight recorders to expose the details of distributed training and help identify problems as they arise in a faster and easier way.
The above is the detailed content of Designed for training Llama 3, Meta 49,000 H100 cluster details announced. For more information, please follow other related articles on the PHP Chinese website!