

 Technology peripheralsAIGoogle's new research on embodied intelligence: RT-H, which is better than RT-2, is here
Technology peripheralsAIGoogle's new research on embodied intelligence: RT-H, which is better than RT-2, is hereGoogle's new research on embodied intelligence: RT-H, which is better than RT-2, is here

As large language models such as GPT-4 are increasingly integrated with robotics, artificial intelligence is gradually moving into the real world. Therefore, research related to embodied intelligence has also attracted more and more attention. Among many research projects, Google's "RT" series of robots have always been at the forefront, and this trend has begun to accelerate recently (see "Large Models Are Reconstructing Robots, How Google Deepmind Defines Embodied Intelligence in the Future" for details).

In July last year, Google DeepMind launched RT-2, which is the world’s first robot capable of controlling vision-language-action (VLA). ) interaction model. Just by giving instructions in a conversational way, RT-2 can identify Swift in a large number of pictures and deliver a can of Coke to her.
Now, this robot has evolved again. The latest version of the RT robot is called "RT-H". It can improve the accuracy of task execution and learning efficiency by decomposing complex tasks into simple language instructions and then converting these instructions into robot actions. For example, given a task, such as "putting the lid on the pistachio jar" and a scene image, RT-H will use a visual language model (VLM) to predict language actions (motion), such as "move the arm forward" and "Rotate the arm to the right", and then predict the robot's action based on these verbal actions.

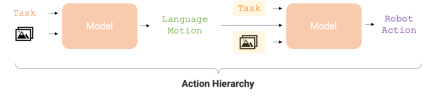
The action hierarchy is critical to optimizing the accuracy and learning efficiency of robot task execution. This hierarchical structure makes RT-H perform significantly better than RT-2 in various robot tasks, providing a more efficient execution path for the robot.

The following are the details of the paper.
Paper Overview

- ##Paper title: RT-H: Action Hierarchies Using Language
- Paper link: https://arxiv.org/pdf/2403.01823.pdf
- Project link: https://rt-hierarchy.github.io/
Language is the engine of human reasoning that allows us to break down complex concepts into simpler components, correct our misunderstandings, and generalize concepts in new contexts. In recent years, robots have also begun to use the efficient and combined structure of language to break down high-level concepts, provide language correction, or achieve generalization in new environments.
These studies usually follow a common paradigm: faced with a high-level task described in language (such as "pick up the Coke can"), they learn to combine observations with the task description in language Mapping policies to low-level robot actions, which requires large-scale multi-task datasets. The advantage of language in these scenarios is that it encodes shared structure between similar tasks (e.g., "pick up the Coke can" versus "pick up the apple"), thereby reducing the data required to learn mappings from tasks to actions. However, as tasks become more diverse, the language used to describe each task also becomes more diverse (e.g., “pick up a Coke can” versus “fill a glass of water”), making learning between different tasks solely through high-level language It becomes more difficult to share structures between
To learn diverse tasks, researchers aim to more accurately capture the similarities between these tasks.
They found that language can not only describe high-level tasks, but also explain in detail how to complete the tasks - this kind of representation is more delicate and closer to specific actions. For example, the task of "picking up a Coke can" can be broken down into a series of more detailed steps, namely "language motion": first "reaching the arm forward", then "grasping the can", and finally "raising the arm upward" ”. The core insight of the researchers is that by using verbal actions as an intermediate layer connecting high-level task descriptions and low-level actions, they can be used to build an action hierarchy formed by verbal actions.
There are several advantages to establishing this level of action:
- It enables better sharing of data at the language action level between different tasks, so that the combination of language actions and the generalization in multi-task data sets are enhanced. For example, although "pour a glass of water" and "pick up a Coke can" are semantically different, their verbal actions are exactly the same until they are executed to pick up the object.
- Language actions are not simply fixed primitives, but are learned through instructions and visual observation based on the specifics of the current task and scene. For example, "reach arms forward" does not specify the speed or direction of movement, which depends on the specific task and observation. The context-dependence and flexibility of learned verbal actions provide us with new capabilities: allowing people to make modifications to verbal actions when the strategy is not 100% successful (see orange area in Figure 1). Further, the robot can even learn from these human corrections. For example, when performing the task of "picking up a Coke can", if the robot closes the gripper in advance, we can instruct it to "keep the arm extended forward longer". This kind of fine-tuning in specific scenarios is not only easy for human guidance , and easier for robots to learn.

In view of the above advantages of language actions, researchers from Google DeepMind designed an end-to-end framework - RT-H ( Robot Transformer with Action Hierarchies, that is, a robot Transformer that uses action levels, focuses on learning this type of action level. RT-H understands how to perform a task at a detailed level by analyzing observations and high-level task descriptions to predict current verbal action instructions. Then, using these observations, tasks, and inferred verbal actions, RT-H predicts the corresponding actions for each step. The verbal actions provide additional context in the process to help predict specific actions more accurately (purple area in Figure 1) .
In addition, they developed an automated method to extract simplified language action sets from the robot's proprioception, building a rich database of more than 2,500 language actions without the need for manual Label.
RT-H’s model architecture draws on RT-2, which is a large-scale visual language model (VLM) jointly trained on Internet-scale visual and language data, aiming to Improve the effectiveness of strategy learning. RT-H uses a single model to handle both language actions and action queries, leveraging extensive Internet-scale knowledge to power every level of the action hierarchy.
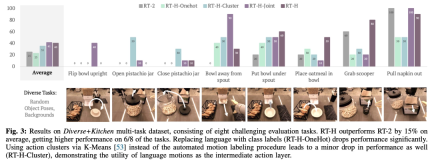
In experiments, researchers found that using the language action hierarchy can bring significant improvements in processing diverse multi-task data sets, compared to RT-2 on a range of tasks Performance improved by 15%. They also found that modifications to the speech movements resulted in near-perfect success rates on the same task, demonstrating the flexibility and situational adaptability of the learned speech movements. Furthermore, by fine-tuning the model for language action intervention, its performance exceeds SOTA interactive imitation learning methods (such as IWR) by 50%. Ultimately, they proved that language actions in RT-H can better adapt to scene and object changes, showing better generalization performance than RT-2.
RT-H architecture detailed explanation
#In order to effectively capture the shared structure across multi-task datasets (not represented by high-level task descriptions), RT-H aims to learn to explicitly exploit action-level strategies.
Specifically, the research team introduced the intermediate language action prediction layer into policy learning. Language actions that describe the fine-grained behavior of robots can capture useful information from multi-task datasets and can generate high-performance policies. Verbal actions can again come into play when the learned policy is difficult to execute: they provide an intuitive interface for online human correction relevant to a given scenario. Policies trained on speech actions can naturally follow low-level human corrections and successfully complete tasks given correction data. Furthermore, the strategy can even be trained on language-corrected data and further improve its performance.
As shown in Figure 2, RT-H has two key stages: first, predict language actions based on task descriptions and visual observations, and then predict language actions based on predicted language actions, specific tasks, and observation results. Infer precise actions.

RT-H uses a VLM backbone network and follows the training procedure of RT-2 for instantiation. Similar to RT-2, RT-H leverages extensive prior knowledge in natural language and image processing from Internet-scale data through collaborative training. To incorporate this prior knowledge into all levels of the action hierarchy, a single model learns both verbal actions and action queries simultaneously.
Experimental results
In order to comprehensively evaluate the performance of RT-H, the research team set four key experimental questions:
- Q1 (Performance): Can action hierarchies with language improve policy performance on multi-task datasets?
- Q2 (Situational): Are the language actions learned by RT-H related to the task and scene context?
- Q3 (Correction): Is training on speech movement correction better than teleoperated correction?
- Q4 (Summary): Can action hierarchies improve the robustness of out-of-distribution settings?
#In terms of data set, this study uses a large multi-task data set containing 100,000 demonstration samples with random object poses and backgrounds. This dataset combines the following datasets:
- Kitchen: The dataset used by RT-1 and RT-2, consisting of 6 semantic task categories from 70K samples.
- Diverse: A new dataset consisting of more complex tasks, with more than 24 semantic task categories, but only 30K samples.
The study called this combined dataset the Diverse Kitchen (D K) dataset and used an automated program to label it for verbal actions. To evaluate the performance of RT-H trained on the full Diverse Kitchen dataset, the study evaluated eight specific tasks, including:
1) Place the bowl upright on the counter Up
2) Open the pistachio jar
3) Close the pistachio jar
4 ) Move the bowl away from the cereal dispenser
5) Place the bowl under the cereal dispenser
6) Place the oatmeal in the bowl Medium
7) Take the spoon from the basket
8) Pull the napkin from the dispenser
These eight tasks were chosen because they require complex action sequences and high precision.
The following table gives the RT-H, RT-H-Joint and RT- 2 Minimum MSE of training checkpoint. The MSE of RT-H is about 20% lower than that of RT-2, and the MSE of RTH-Joint is 5-10% lower than RT-2, indicating that action hierarchy can help improve offline action prediction in large multi-task datasets. RT-H (GT) uses the ground truth MSE metric and achieves a 40% gap from end-to-end MSE, indicating that correctly labeled language actions have high informational value for predicting actions.

Figure 4 shows several examples of contextual actions taken from the RT-H online evaluation. As can be seen, the same verbal action often results in subtle changes in actions to accomplish the task, while still respecting the higher-level verbal action.

As shown in Figure 5, the research team demonstrated the flexibility of RT-H by intervening online with language movements in RT-H.

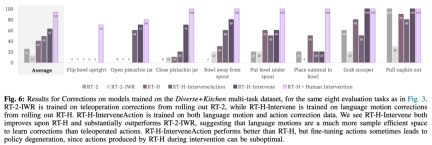
This study also used comparative experiments to analyze the effect of correction. The results are shown in Figure 6 below:
As shown in Figure 7, RT-H and RT-H-Joint are significantly more robust to scene changes:

In fact, there is some shared structure between seemingly different tasks. For example, each of these tasks requires some picking behaviors to start the task, and by learning the shared structure of language actions across different tasks, RT -H completes the pickup phase without any corrections.

Even when RT-H is no longer able to generalize its speech action predictions, speech action corrections can usually generalize, so just do A few fixes will do the job successfully. This demonstrates the potential of verbal actions to expand data collection on new tasks.
Interested readers can read the original text of the paper to learn more about the research content.
The above is the detailed content of Google's new research on embodied intelligence: RT-H, which is better than RT-2, is here. For more information, please follow other related articles on the PHP Chinese website!

 Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AM
Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AMThis article explores the growing concern of "AI agency decay"—the gradual decline in our ability to think and decide independently. This is especially crucial for business leaders navigating the increasingly automated world while retainin
 How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AM
How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AMEver wondered how AI agents like Siri and Alexa work? These intelligent systems are becoming more important in our daily lives. This article introduces the ReAct pattern, a method that enhances AI agents by combining reasoning an
 Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM
Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM"I think AI tools are changing the learning opportunities for college students. We believe in developing students in core courses, but more and more people also want to get a perspective of computational and statistical thinking," said University of Chicago President Paul Alivisatos in an interview with Deloitte Nitin Mittal at the Davos Forum in January. He believes that people will have to become creators and co-creators of AI, which means that learning and other aspects need to adapt to some major changes. Digital intelligence and critical thinking Professor Alexa Joubin of George Washington University described artificial intelligence as a “heuristic tool” in the humanities and explores how it changes
 Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AM
Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AMLangChain is a powerful toolkit for building sophisticated AI applications. Its agent architecture is particularly noteworthy, allowing developers to create intelligent systems capable of independent reasoning, decision-making, and action. This expl
 What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AM
What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AMRadial Basis Function Neural Networks (RBFNNs): A Comprehensive Guide Radial Basis Function Neural Networks (RBFNNs) are a powerful type of neural network architecture that leverages radial basis functions for activation. Their unique structure make
 The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AM
The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AMBrain-computer interfaces (BCIs) directly link the brain to external devices, translating brain impulses into actions without physical movement. This technology utilizes implanted sensors to capture brain signals, converting them into digital comman
 Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AM
Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AMThis "Leading with Data" episode features Ines Montani, co-founder and CEO of Explosion AI, and co-developer of spaCy and Prodigy. Ines offers expert insights into the evolution of these tools, Explosion's unique business model, and the tr
 A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AM
A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AMThis article explores Retrieval Augmented Generation (RAG) systems and how AI agents can enhance their capabilities. Traditional RAG systems, while useful for leveraging custom enterprise data, suffer from limitations such as a lack of real-time dat


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

WebStorm Mac version
Useful JavaScript development tools

Atom editor mac version download
The most popular open source editor

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

