
 Technology peripheralsAIWhat is the speculative decoding that GPT-4 might also be using? An article summarizing the past, present and application situations
Technology peripheralsAIWhat is the speculative decoding that GPT-4 might also be using? An article summarizing the past, present and application situationsWhat is the speculative decoding that GPT-4 might also be using? An article summarizing the past, present and application situations

As we all know, the inference of large language models (LLM) usually requires the use of autoregressive sampling, and this inference process is quite slow. In order to solve this problem, speculative decoding has become a new sampling method for LLM inference. In each sampling step, this method will first predict several possible tokens and then verify whether they are accurate in parallel. Unlike autoregressive decoding, speculative decoding can decode multiple tokens in a single step, thus speeding up inference.
Although speculative decoding shows great potential in many aspects, it also raises some key issues that require in-depth research. First, we need to think about how to select or design an appropriate approximate model to strike a balance between the accuracy of conjecture and the efficiency of generation. Second, it is important to ensure that assessment criteria maintain both the diversity and quality of the results generated. Finally, the alignment of the inference process between the approximate model and the target large model must be carefully considered to improve the accuracy of the inference.
Researchers from Hong Kong Polytechnic University, Peking University, MSRA and Alibaba have conducted a comprehensive investigation on speculative decoding, and Machine Heart has made a comprehensive summary of this.

- ##Paper title: Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
- Paper address: https://arxiv.org/pdf/2401.07851.pdf
The evolution of speculative decoding
The article first introduces the early research status of speculative decoding technology in detail, and shows its development process through a timetable (see Figure 2) .
Blockwise Decoding is a method of integrating additional feedforward neural (FFN) heads on the Transformer decoder, which can generate multiple tokens in a single step.
In order to further fully exploit the potential of the block sampling algorithm, a speculative decoding solution is proposed. This algorithm covers an independent approximate model, usually using a specialized non-autoregressive Transformer, capable of performing generation tasks efficiently and accurately.
After the emergence of speculative decoding, some scholars then proposed the "Speculative Sampling Algorithm", which added lossless accelerated kernel sampling to speculative decoding.
Overall, these innovative attempts at speculative decoding have begun to strengthen the Draftthen-Verify paradigm and demonstrate great potential in LLM acceleration.

This section begins with a brief overview of the standard We return to the content of decoding, and then provide an in-depth explanation of speculative decoding algorithms, including a comprehensive description of the formal definition, methodology, and detailed elaboration of the algorithm.
This article proposes an organizational framework to classify related research, as shown in Figure 3 below.

The speculative decoding algorithm is a decoding mode that generates first and then verifies. At each decoding step, it first needs to be able to generate multiple possible tokens, and then use the target large language model to evaluate all these tokens in parallel to speed up Reasoning speed. Algorithm Table 2 is a detailed speculative decoding process.

Generate
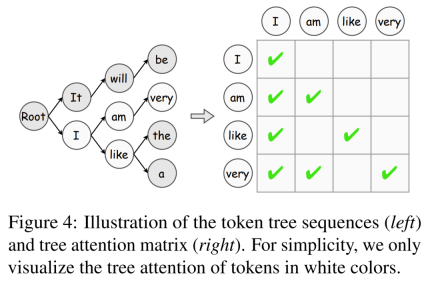
At each decoding step, the speculative decoding algorithm first generates Multiple possible tokens serve as speculations on the output content of the target large language model.This article divides the generated content into two categories: independent drafting and self-drafting, and summarizes its formulas in Table 1 below. ##Verify on each decode In this step, the tokens generated by the approximate model are verified in parallel to ensure that the output quality is highly consistent with the target large language model. This process also determines the number of tokens allowed at each step, an important factor that can affect speedup. A summary of the various validation criteria is shown in Table 2 below, including those that support greedy decoding and kernel sampling in large language model inference. The sub-steps of generation and verification will continue to iterate until the termination condition is met, that is, the [EOS] token is decoded or the sentence reaches the maximum length. In addition, this article introduces the token tree verification algorithm, which is an effective strategy to gradually improve token acceptance. Improving guess accuracy is key to speeding up speculative decoding: predictions from approximate models The closer the behavior is to the target large language model, the higher the acceptance rate of its generated tokens. To this end, existing work explores various knowledge extraction (KD) strategies to align the output content of the approximate model with that of the target large language model. Blocked decoding first uses sequence-level knowledge extraction (Seq-KD) for model alignment, and uses sentences generated by the target large language model to train the approximate model. In addition, Seq-KD is also an effective strategy to improve the quality of parallel decoding generation, improving the generation performance of parallel decoding. The main characteristics of existing speculative decoding methods are summarized in Table 3 below, including the type of approximate model or generation strategy, model alignment method, supported evaluation strategy and degree of acceleration. In addition to being a general paradigm, recent The work also shows that some variants of speculative decoding exhibit extraordinary effectiveness in specific tasks. Additionally, other research has applied this paradigm to address latency issues unique to certain application scenarios, thereby achieving inference acceleration. For example, some scholars believe that speculative decoding is particularly suitable for tasks where the model input and output are highly similar, such as grammatical error correction and retrieval enhancement generation. In addition to these works, RaLMSpec (Zhang et al., 2023b) uses speculative decoding to accelerate retrieval augmented language models (RaLMs). Question 1: How to weigh the accuracy of predicted content and the efficiency of generating it? Although some progress has been made on this problem, there is still considerable room for improvement in aligning approximate models with what the target large language model generates. In addition to model alignment, other factors such as generation quality and determination of prediction length also affect the accuracy of predictions and deserve further exploration. Question 2: How to combine speculative decoding with other leading technologies? As a general decoding mode, speculative decoding has been combined with other advanced technologies to demonstrate its potential. In addition to accelerating large language models for plain text, the application of speculative decoding in multimodal reasoning, such as image synthesis, text-to-speech synthesis, and video generation, is also an interesting and valuable direction for future research. Please refer to the original paper for more details. 

Model Alignment

Application
Opportunities and Challenges
The above is the detailed content of What is the speculative decoding that GPT-4 might also be using? An article summarizing the past, present and application situations. For more information, please follow other related articles on the PHP Chinese website!

 Excel TRANSPOSE FunctionApr 22, 2025 am 09:52 AM
Excel TRANSPOSE FunctionApr 22, 2025 am 09:52 AMPowerful tools in Excel data analysis and processing: Detailed explanation of TRANSPOSE function Excel remains a powerful tool in the field of data analysis and processing. Among its many features, the TRANSPOSE function stands out for its ability to reorganize data quickly and efficiently. This feature is especially useful for data scientists and AI professionals who often need to reconstruct data to suit specific analytics needs. In this article, we will explore the TRANSPOSE function of Excel in depth, exploring its uses, usage and its practical application in data science and artificial intelligence. Learn more: Microsoft Excel Data Analytics Table of contents In Excel
 How to Install Power BI DesktopApr 22, 2025 am 09:49 AM
How to Install Power BI DesktopApr 22, 2025 am 09:49 AMGet Started with Microsoft Power BI Desktop: A Comprehensive Guide Microsoft Power BI is a powerful, free business analytics tool enabling data visualization and seamless insight sharing. Whether you're a data scientist, analyst, or business user, P
 Graph RAG: Enhancing RAG with Graph Structures - Analytics VidhyaApr 22, 2025 am 09:48 AM
Graph RAG: Enhancing RAG with Graph Structures - Analytics VidhyaApr 22, 2025 am 09:48 AMIntroduction Ever wondered how some AI systems seem to effortlessly access and integrate relevant information into their responses, mimicking a conversation with an expert? This is the power of Retrieval-Augmented Generation (RAG). RAG significantly
 SQL GRANT CommandApr 22, 2025 am 09:45 AM
SQL GRANT CommandApr 22, 2025 am 09:45 AMIntroduction Database security hinges on managing user permissions. SQL's GRANT command is crucial for this, enabling administrators to assign specific access rights to different users or roles. This article explains the GRANT command, its syntax, c
 What is Python IDLE?Apr 22, 2025 am 09:43 AM
What is Python IDLE?Apr 22, 2025 am 09:43 AMIntroduction Python IDLE is a powerful tool that can easily develop, debug and run Python code. Its interactive shell, syntax highlighting, autocomplete and integrated debugger make it ideal for programmers of all levels of experience. This article will outline its functions, settings, and practical applications. Overview Learn about Python IDLE and its development benefits. Browse and use the main components of the IDLE interface. Write, save, and run Python scripts in IDLE. Use syntax highlighting, autocomplete and intelligent indentation. Use the IDLE integrated debugger to effectively debug Python code. Table of contents
 Python & # 039: S maximum Integer ValueApr 22, 2025 am 09:40 AM
Python & # 039: S maximum Integer ValueApr 22, 2025 am 09:40 AMPython: Mastering Large Integers – A Comprehensive Guide Python's exceptional capabilities extend to handling integers of any size. While this offers significant advantages, it's crucial to understand potential limitations. This guide provides a deta
 9 Free Stanford AI CoursesApr 22, 2025 am 09:35 AM
9 Free Stanford AI CoursesApr 22, 2025 am 09:35 AMIntroduction Artificial intelligence (AI) is revolutionizing industries and unlocking unprecedented possibilities across diverse fields. Stanford University, a leading institution in AI research, provides a wealth of free online courses to help you
 What is Meta's Segment Anything Model(SAM)?Apr 22, 2025 am 09:25 AM
What is Meta's Segment Anything Model(SAM)?Apr 22, 2025 am 09:25 AMMeta's Segment Anything Model (SAM): A Revolutionary Leap in Image Segmentation Meta AI has unveiled SAM (Segment Anything Model), a groundbreaking AI model poised to revolutionize computer vision and image segmentation. This article delves into SAM


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Dreamweaver Mac version
Visual web development tools

