
 System TutorialLINUXUnderstand inode and extended attributes to improve data security in Linux cloud environment
System TutorialLINUXUnderstand inode and extended attributes to improve data security in Linux cloud environmentUnderstand inode and extended attributes to improve data security in Linux cloud environment

In the Linux cloud environment, data security is a very important task. The two concepts of inode and extended attributes may have a significant impact on your data security. Inode is one of the core concepts in the Linux file system. It saves the physical location, access permissions and other information of a file or directory on the disk. Extended attributes are a set of additional metadata contained in the inode, which can add more detailed information to a file or directory, such as the author of the file, creation time, etc. This information is very important in data recovery and protection.

1. What is inode?
To understand inode, we must start with file storage.
Files are stored on the hard disk. The smallest storage unit of the hard disk is called "Sector". Each sector stores 512 bytes (equivalent to 0.5KB).
When the operating system reads the hard disk, it does not read it sector by sector, which is too inefficient. Instead, it reads multiple sectors continuously at one time, that is, it reads one "block" at a time. . This "block" consisting of multiple sectors is the smallest unit of file access. The most common size of "block" is 4KB, that is, eight consecutive sectors form a block.
File data is stored in "blocks", so obviously, we must also find a place to store the meta-information of the file, such as the creator of the file, the creation date of the file, the size of the file, etc. This area that stores file metainformation is called inode, and its Chinese translation is "index node".
2. Contents of inode
inode contains the meta information of the file, specifically the following contents:
* Number of bytes in the file
* User ID of the file owner
* Group ID of the file
* File read, write, and execute permissions
* There are three timestamps for files: ctime refers to the time when the inode was last changed, mtime refers to the time when the file content was last changed, and atime refers to the time when the file was last opened.
* Number of links, that is, how many file names point to this inode
* The location of the file data block
You can use the stat command to view the inode information of a certain file:
stat example.txt
In short, all file information except the file name is stored in the inode. As for why there is no file name, there will be a detailed explanation below.
3. Inode size
Inode also consumes hard disk space, so when the hard disk is formatted, the operating system automatically divides the hard disk into two areas. One is the data area, which stores file data; the other is the inode area (inode table), which stores the information contained in the inode.
The size of each inode node is generally 128 bytes or 256 bytes. The total number of inode nodes is given during formatting, usually one inode is set every 1KB or every 2KB. Assuming that in a 1GB hard disk, the size of each inode node is 128 bytes, and one inode is set for every 1KB, then the size of the inode table will reach 128MB, accounting for 12.8% of the entire hard disk.
To view the total number of inodes in each hard disk partition and the number that has been used, you can use the df command.
df -i
To view the size of each inode node, you can use the following command:
sudo dumpe2fs -h /dev/hda | grep "Inode size"
Since each file must have an inode, it may happen that the inodes have been used up, but the hard disk is not yet full. At this time, new files cannot be created on the hard drive.
4. Inode number
Each inode has a number, and the operating system uses the inode number to identify different files.
It is worth repeating here that Unix/Linux systems do not use file names internally, but use inode numbers to identify files. For the system, the file name is just an alias or nickname for the inode number for easy identification. On the surface, the user opens the file by the file name. In fact, the process within the system is divided into three steps: first, the system finds the inode number corresponding to the file name; second, obtains the inode information through the inode number; finally, based on the inode information, it finds the block where the file data is located and reads the data.
Use the ls -i command to see the inode number corresponding to the file name:
ls -i example.txt
5. Directory files
In Unix/Linux systems, a directory is also a kind of file. Opening a directory actually means opening the directory file.
The structure of a directory file is very simple, which is a list of a series of directory entries (dirent). Each directory entry consists of two parts: the file name of the contained file, and the inode number corresponding to the file name.
ls command only lists all file names in directory files:
ls /etc
ls -i command lists the entire directory files, that is, file names and inode numbers:
ls -i /etc
If you want to view the detailed information of the file, you must access the inode node and read the information according to the inode number. The ls -l command lists detailed information about a file.
ls -l /etc
6. Hard link
一般情况下,文件名和inode号码是”一一对应”关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为”硬链接”(hard link)。
ln命令可以创建硬链接:
ln 源文件 目标文件
运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做”链接数”,记录指向该inode的文件名总数,这时就会增加1。反过来,删除一个文件名,就会使得inode节点中的”链接数”减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的”链接数”。创建目录时,默认会生成两个目录项:”.”和”..”。前者的inode号码就是当前目录的inode号码,等同于当前目录的”硬链接”;后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的”硬链接”。所以,任何一个目录的”硬链接”总数,总是等于2加上它的子目录总数(含隐藏目录),这里的2是父目录对其的“硬链接”和当前目录下的”.硬链接“。
**七、软链接
**
除了硬链接以外,还有一种特殊情况。文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的”软链接”(soft link)或者”符号链接(symbolic link)。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:”No such file or directory”。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode”链接数”不会因此发生变化。
ln -s命令可以创建软链接。
ln -s 源文文件或目录 目标文件或目录
八、inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
\1. 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
\2. 移动文件或重命名文件,只是改变文件名,不影响inode号码。
\3. 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
九 实际问题
在一台配置较低的Linux服务器(内存、硬盘比较小)的/data分区内创建文件时,系统提示磁盘空间不足,用df -h命令查看了一下磁盘使用情况,发现/data分区只使用了66%,还有12G的剩余空间,按理说不会出现这种问题。 后来用df -i查看了一下/data分区的索引节点(inode),发现已经用满(IUsed=100%),导致系统无法创建新目录和文件。
查找原因:
/data/cache目录中存在数量非常多的小字节缓存文件,占用的Block不多,但是占用了大量的inode。
解决方案:
1、删除/data/cache目录中的部分文件,释放出/data分区的一部分inode。
2、用软连接将空闲分区/opt中的newcache目录连接到/data/cache,使用/opt分区的inode来缓解/data分区inode不足的问题:
ln -s /opt/newcache /data/cache
在Linux云环境下,inode和扩展属性是非常有用的工具,它们可以帮助我们更好地保护和管理数据。通过对inode和扩展属性的深入了解,我们可以更好地理解Linux文件系统的工作原理,更好地掌握数据安全的方法。因此,我们强烈建议Linux云环境下的用户不仅要了解inode和扩展属性,还要深入了解其他的相关概念和技术,从而更好地保护自己的数据安全。
The above is the detailed content of Understand inode and extended attributes to improve data security in Linux cloud environment. For more information, please follow other related articles on the PHP Chinese website!

 How does performance differ between Linux and Windows for various tasks?May 14, 2025 am 12:03 AM
How does performance differ between Linux and Windows for various tasks?May 14, 2025 am 12:03 AMLinux performs well in servers and development environments, while Windows performs better in desktop and gaming. 1) Linux's file system performs well when dealing with large numbers of small files. 2) Linux performs excellently in high concurrency and high throughput network scenarios. 3) Linux memory management has more advantages in server environments. 4) Linux is efficient when executing command line and script tasks, while Windows performs better on graphical interfaces and multimedia applications.
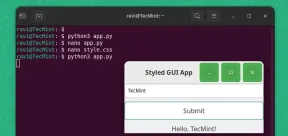 How to Create GUI Applications In Linux Using PyGObjectMay 13, 2025 am 11:09 AM
How to Create GUI Applications In Linux Using PyGObjectMay 13, 2025 am 11:09 AMCreating graphical user interface (GUI) applications is a fantastic way to bring your ideas to life and make your programs more user-friendly. PyGObject is a Python library that allows developers to create GUI applications on Linux desktops using the
 How to Install LAMP Stack with PhpMyAdmin in Arch LinuxMay 13, 2025 am 11:01 AM
How to Install LAMP Stack with PhpMyAdmin in Arch LinuxMay 13, 2025 am 11:01 AMArch Linux provides a flexible cutting-edge system environment and is a powerfully suited solution for developing web applications on small non-critical systems because is a completely open source and provides the latest up-to-date releases on kernel
 How to Install LEMP (Nginx, PHP, MariaDB) on Arch LinuxMay 13, 2025 am 10:43 AM
How to Install LEMP (Nginx, PHP, MariaDB) on Arch LinuxMay 13, 2025 am 10:43 AMDue to its Rolling Release model which embraces cutting-edge software Arch Linux was not designed and developed to run as a server to provide reliable network services because it requires extra time for maintenance, constant upgrades, and sensible fi
![12 Must-Have Linux Console [Terminal] File Managers](https://img.php.cn/upload/article/001/242/473/174710245395762.png?x-oss-process=image/resize,p_40) 12 Must-Have Linux Console [Terminal] File ManagersMay 13, 2025 am 10:14 AM
12 Must-Have Linux Console [Terminal] File ManagersMay 13, 2025 am 10:14 AMLinux console file managers can be very helpful in day-to-day tasks, when managing files on a local machine, or when connected to a remote one. The visual console representation of the directory helps us quickly perform file/folder operations and sav
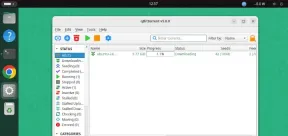 qBittorrent: A Powerful Open-Source BitTorrent ClientMay 13, 2025 am 10:12 AM
qBittorrent: A Powerful Open-Source BitTorrent ClientMay 13, 2025 am 10:12 AMqBittorrent is a popular open-source BitTorrent client that allows users to download and share files over the internet. The latest version, qBittorrent 5.0, was released recently and comes packed with new features and improvements. This article will
 Setup Nginx Virtual Hosts, phpMyAdmin, and SSL on Arch LinuxMay 13, 2025 am 10:03 AM
Setup Nginx Virtual Hosts, phpMyAdmin, and SSL on Arch LinuxMay 13, 2025 am 10:03 AMThe previous Arch Linux LEMP article just covered basic stuff, from installing network services (Nginx, PHP, MySQL, and PhpMyAdmin) and configuring minimal security required for MySQL server and PhpMyadmin. This topic is strictly related to the forme
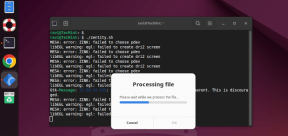 Zenity: Building GTK Dialogs in Shell ScriptsMay 13, 2025 am 09:38 AM
Zenity: Building GTK Dialogs in Shell ScriptsMay 13, 2025 am 09:38 AMZenity is a tool that allows you to create graphical dialog boxes in Linux using the command line. It uses GTK , a toolkit for creating graphical user interfaces (GUIs), making it easy to add visual elements to your scripts. Zenity can be extremely u


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Zend Studio 13.0.1
Powerful PHP integrated development environment

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

