Large Scale Visual Language Model (LVLM) can improve performance by scaling the model. However, increasing the parameter size increases training and inference costs because the calculation of each token activates all model parameters.
Researchers from Peking University, Sun Yat-sen University and other institutions jointly proposed a new training strategy called MoE-Tuning to solve the performance degradation problem related to multi-modal learning and model sparsity. MoE-Tuning is able to build sparse models with a surprising number of parameters but constant computational cost. In addition, the researchers also proposed a new sparse LVLM architecture based on MoE, called the MoE-LLaVA framework. In this framework, only the top k experts are activated through the routing algorithm, and the remaining experts remain inactive. In this way, the MoE-LLaVA framework can more efficiently utilize the resources of the expert network during the deployment process. These research results provide new solutions to solve the challenges of multi-modal learning and model sparsity of LVLM models.

Paper address: https://arxiv.org/abs/2401.15947
Project address: https://github.com/PKU-YuanGroup/MoE-LLaVA
Demo address: https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
Paper title: MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
MoE-LLaVA has only 3B sparse activation parameters, but its performance is similar to LLaVA- 1.5-7B is comparable on various visual understanding datasets and even surpasses LLaVA-1.5-13B on the object illusion benchmark. Through MoE-LLaVA, this study aims to establish a benchmark for sparse LVLMs and provide valuable insights for future research to develop more efficient and effective multi-modal learning systems. The MoE-LLaVA team has made all data, code and models open.
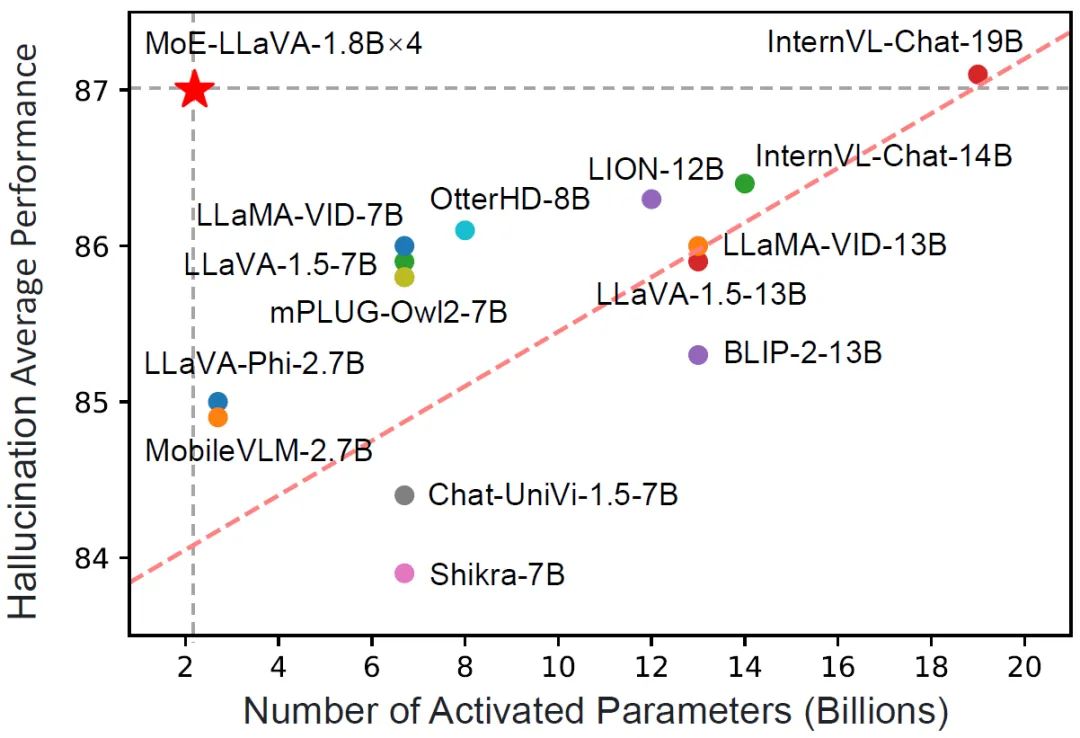
Figure 1 Comparison of MoE-LLaVA’s hallucination performance with other LVLMMoE-LLaVA adopts a three-stage training strategy.
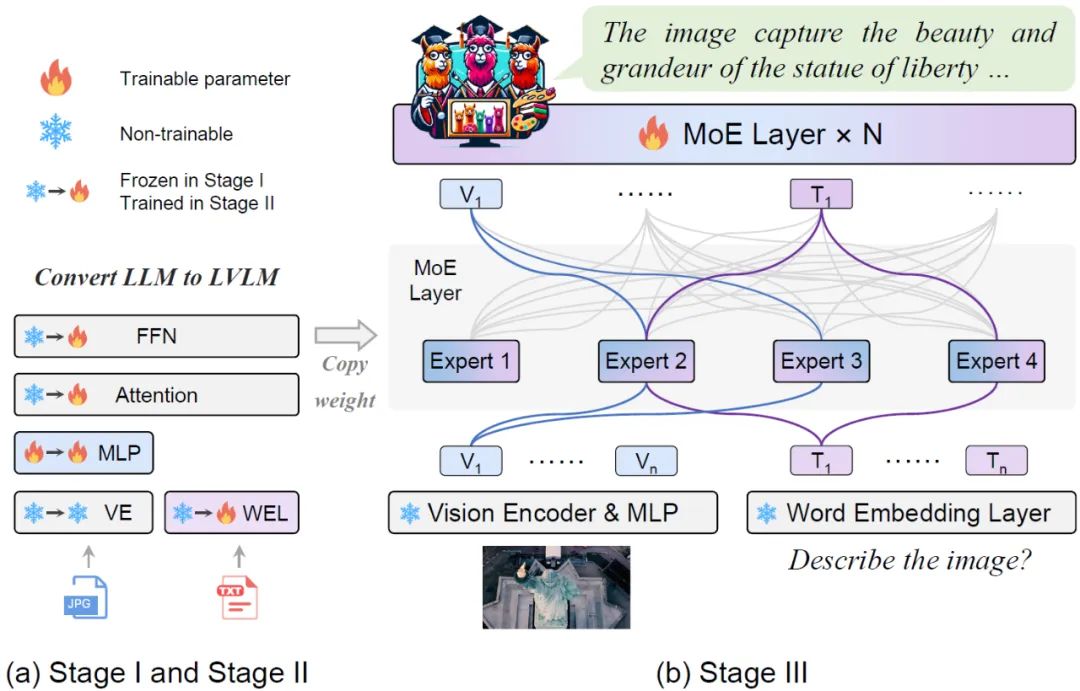
Figure 2 MoE-Tuning flow chart As shown in Figure 2, the vision encoder processes the input image to obtain a visual token sequence. A projection layer is used to map visual tokens into dimensions acceptable to the LLM. Similarly, the text paired with the image is projected through a word embedding layer to obtain the sequence text token. Phase 1: As shown in Figure 2, the goal of Phase 1 is to adapt the visual token to LLM and give LLM the ability to understand the entities in the picture. MoE-LLaVA uses an MLP to project image tokens into the input domain of LLM, which means that small image patches are treated as pseudo-text tokens by LLM. At this stage, LLM is trained to describe images and understand higher-level image semantics. The MoE layer will not be applied to LVLM at this stage.
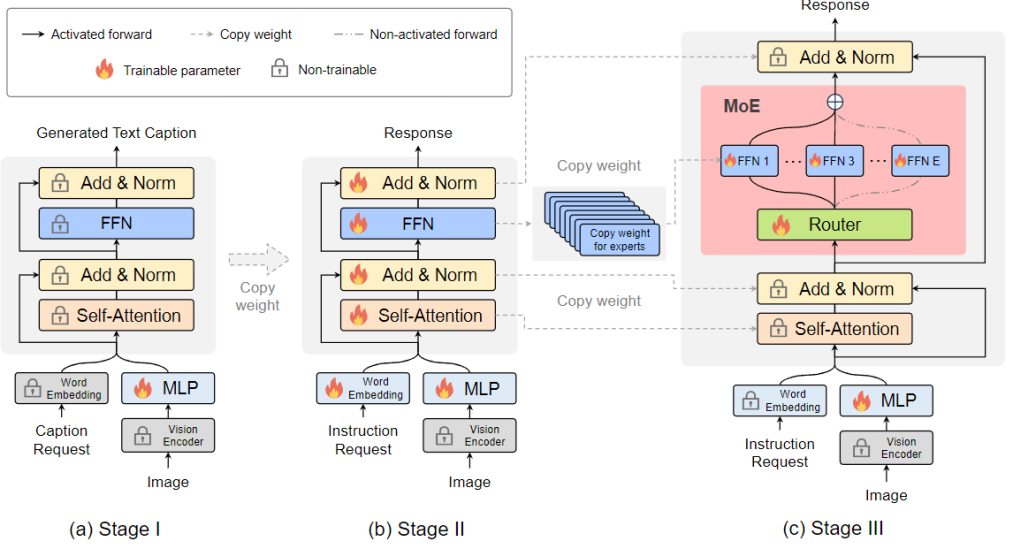
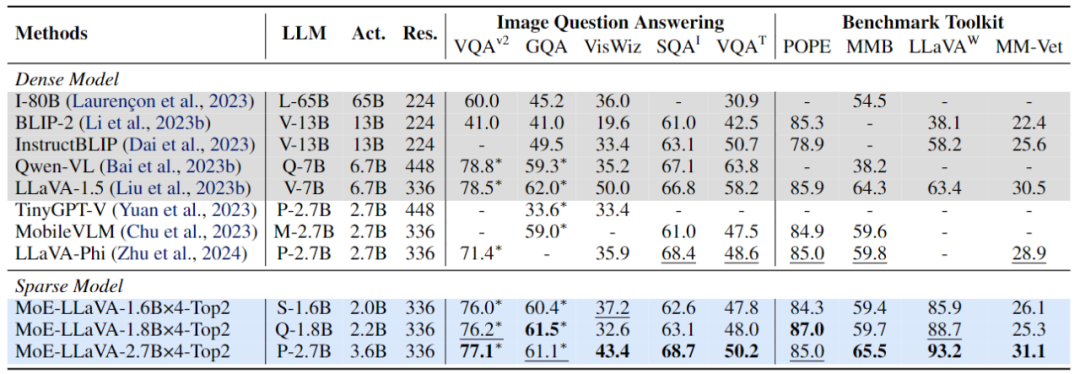
Figure 3 More specific training framework and training strategyPhase 2: Using multi-modal instruction data Fine-tuning is a key technology to improve the capability and controllability of large models, and at this stage LLM is adjusted to LVLM with multi-modal understanding capabilities. At this stage, the research adds more complex instructions, including advanced tasks such as picture logical reasoning and text recognition, which require the model to have stronger multi-modal understanding capabilities. Generally speaking, the LVLM of the dense model is trained at this point. However, the research team found that it is challenging to convert the LLM to LVLM and sparse the model at the same time. Therefore, MoE-LLaVA will use the weights of the second stage as the initialization of the third stage to reduce the difficulty of sparse model learning. Phase 3: MoE-LLaVA copies multiple copies of FFN as the initialization weight of the expert set. When visual tokens and text tokens are fed into the MoE layer, the router will calculate the matching weight of each token and the experts, and then each token will be sent to the most matching top-k experts for processing, and finally based on the weight of the router The weighted summation is aggregated into the output. When the top-k experts are activated, the remaining experts remain inactive, and this model constitutes MoE-LLaVA with infinite possible sparse pathways. ##As shown in Figure 4, due to MoE-LLaVA is the first sparse model based on LVLM equipped with soft router, so this study summarizes the previous models as dense models. The research team verified the performance of MoE-LLaVA on 5 image question and answer benchmarks, and reported the amount of activated parameters and image resolution. Compared with the SOTA method LLaVA-1.5, MoE-LLaVA-2.7B×4 demonstrates strong image understanding capabilities, and its performance on 5 benchmarks is very close to LLaVA-1.5. Among them, MoE-LLaVA uses 3.6B sparse activation parameters and exceeds LLaVA-1.5-7B on SQAI by 1.9%. It is worth noting that due to the sparse structure of MoE-LLaVA, only 2.6B activation parameters are needed to fully surpass IDEFICS-80B.
Figure 4 Performance of MoE-LLaVA on 9 benchmarks In addition, the research team also paid attention to the recent small visual language model TinyGPT-V, MoE-LLaVA-1.8B×4, which exceeded TinyGPT-V by 27.5% and 10% respectively in GQA and VisWiz under equivalent activation parameters. This signifies MoE-LLaVA's powerful understanding capabilities in natural vision.
To more comprehensively verify the multi-modal understanding capabilities of MoE-LLaVA, this study evaluated model performance on 4 benchmark toolkits. The benchmark toolkit is a toolkit for verifying whether the model can answer questions in natural language. Usually the answers are open and have no fixed template. As shown in Figure 4, MoE-LLaVA-1.8B×4 outperforms Qwen-VL, which uses a larger image resolution. These results show that MoE-LLaVA, a sparse model, can achieve performance comparable to or even exceeding that of dense models with fewer activation parameters.
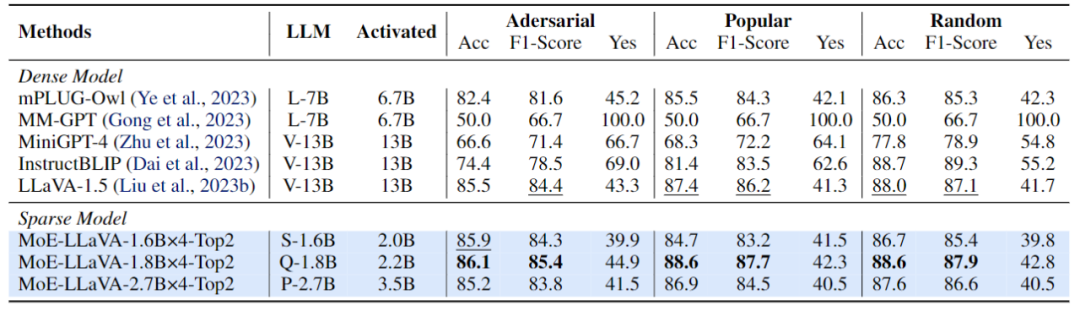
Figure 5 Performance evaluation of MoE-LLaVA on hallucinatory object detectionThis study uses the POPE evaluation pipeline to verify the object illusion of MoE-LLaVA. The results are shown in Figure 5. MoE-LLaVA shows the best performance, which means that MoE-LLaVA tends to generate images that are consistent with the given image. Object. Specifically, MoE-LLaVA-1.8B×4 surpassed LLaVA with an activation parameter of 2.2B. In addition, the research team observed that the yes ratio of MoE-LLaVA is in a relatively balanced state, which shows that the sparse model MoE-LLaVA can make correct feedback according to the problem.
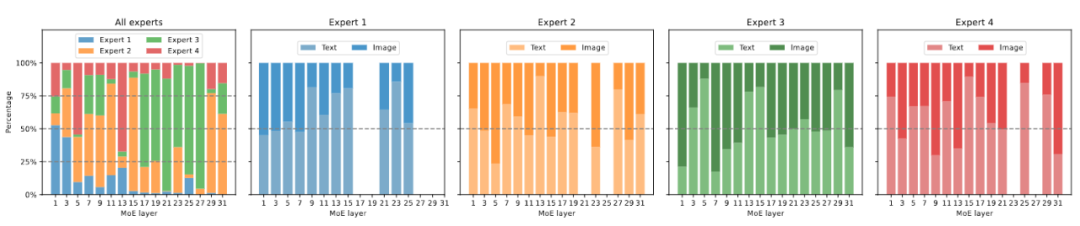
Figure 6 Expert load visualizationFigure 6 Display Received the expert load of MoE-LLaVA-2.7B×4-Top2 on ScienceQA. Overall, during training initialization, the load of experts in all MoE layers is relatively balanced. However, as the model gradually becomes sparse, the load of experts on layers 17 to 27 suddenly increases, and even covers almost all tokens. For shallow layers 5-11, experts 2, 3, and 4 mainly work together. It is worth noting that Expert 1 works almost exclusively on layers 1-3 and gradually drops out of the work as the model gets deeper. Therefore, MoE-LLaVA experts have learned a specific pattern that enables expert division of labor according to certain rules.
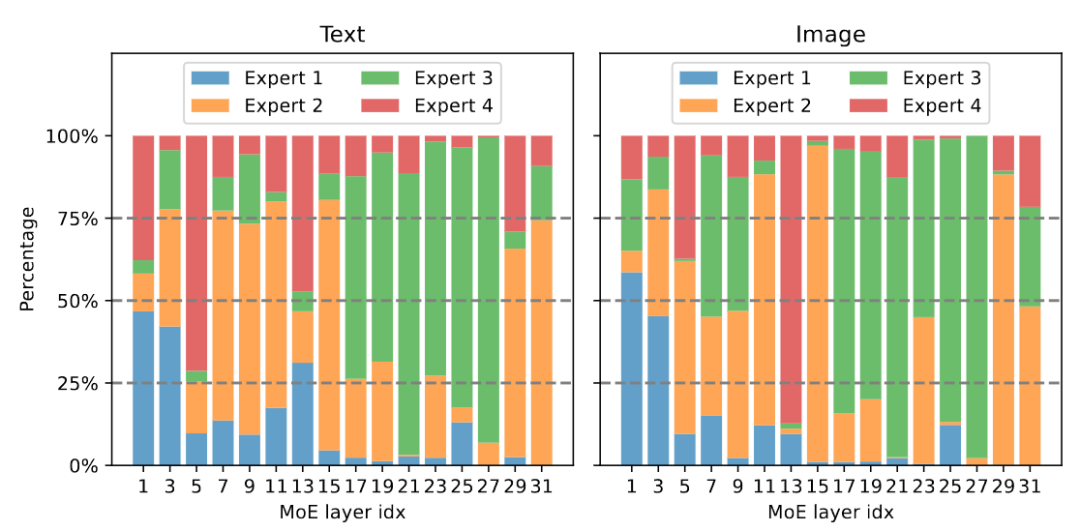
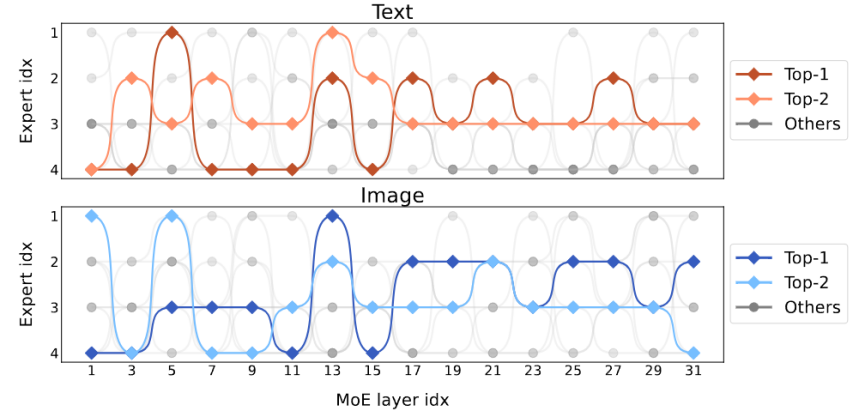
Figure 7 Visualization of modal distribution##Figure 7 shows the modal distribution of different experts. The study found that the routing distribution of text and image is very similar. For example, when expert 3 works hard on layers 17-27, the proportion of text and image processed by it is similar. This shows that MoE-LLaVA has no clear preference for modality. #The study also observed the behavior of experts at the token level and tracked the trajectory of all tokens in the sparse network on downstream tasks. For all activated pathways of text and image, this study used PCA to reduce dimensionality to obtain the main 10 pathways, as shown in Figure 8. The research team found that for an unseen text token or image token, MoE-LLaVA always prefers to dispatch experts 2 and 3 to handle the depth of the model. Experts 1 and 4 tend to deal with initialized tokens. These results can help us better understand the behavior of sparse models in multi-modal learning and explore unknown possibilities.
Figure 8 Visualization of activated pathwaysThe above is the detailed content of Sparse the multi-modal large model, and the 3B model MoE-LLaVA is comparable to LLaVA-1.5-7B. For more information, please follow other related articles on the PHP Chinese website!