
Home >Technology peripherals >AI >Uncovering the NVIDIA large model inference framework: TensorRT-LLM
Uncovering the NVIDIA large model inference framework: TensorRT-LLM

- WBOYforward
- 2024-02-01 17:24:231088browse
1. Product positioning of TensorRT-LLM
TensorRT-LLM is a scalable inference solution developed by NVIDIA for large language models (LLM). It builds, compiles and executes calculation graphs based on the TensorRT deep learning compilation framework, and draws on the efficient Kernels implementation in FastTransformer. In addition, it utilizes NCCL for communication between devices. Developers can customize operators to meet specific needs based on technology development and demand differences, such as developing customized GEMM based on cutlass. TensorRT-LLM is NVIDIA's official inference solution, committed to providing high performance and continuously improving its practicality.

TensorRT-LLM is open source on GitHub and is divided into two branches: Release branch and Dev branch. The Release branch is updated once a month, while the Dev branch will update features from official or community sources more frequently to facilitate developers to experience and evaluate the latest features. The figure below shows the framework structure of TensorRT-LLM. Except for the green TensorRT compilation part and the kernels involving hardware information, other parts are open source.

TensorRT-LLM also provides an API similar to Pytorch to reduce developers’ learning costs, and provides many predefined models for User use.

Due to the large size of large language models, inference may not be completed on a single graphics card, so TensorRT-LLM provides two parallel mechanisms : Tensor Parallelism and Pipeline Parallelism to support multi-card or multi-machine reasoning. These mechanisms allow the model to be split into multiple parts and distributed across multiple graphics cards or machines for parallel computation to improve inference performance. Tensor Parallelism achieves parallel computing by distributing model parameters on different devices and calculating the output of different parts at the same time. Pipeline Parallelism divides the model into multiple stages, each stage is calculated in parallel on different devices, and the output is passed to the next stage, thereby achieving the overall

2. Important features of TensorRT-LLM
TensorRT-LLM is a powerful tool , with rich model support and low-precision inference capabilities. First of all, TensorRT-LLM supports mainstream large language models, including model adaptation completed by developers, such as Qwen (Qianwen), and has been included in official support. This means that users can easily extend or customize these predefined models and apply them to their own projects quickly and easily. Secondly, TensorRT-LLM uses the FP16/BF16 precision inference method by default. This low-precision reasoning can not only improve reasoning performance, but also use the industry's quantization methods to further optimize hardware throughput. By reducing the accuracy of the model, TensorRT-LLM can greatly improve the speed and efficiency of inference without sacrificing too much accuracy. In summary, TensorRT-LLM's rich model support and low-precision inference capabilities make it a very practical tool. Whether for developers or researchers, TensorRT-LLM can provide efficient inference solutions to help them achieve better performance in deep learning applications.

Another feature is the implementation of FMHA (fused multi-head attention) kernel. Since the most time-consuming part of Transformer is the calculation of self-attention, the official designed FMHA to optimize the calculation of self-attention, and provided different versions with accumulators of fp16 and fp32. In addition, in addition to the improvement in speed, the memory usage is also greatly reduced. We also provide a flash attention-based implementation that can extend sequence-length to arbitrary lengths.

The following is the detailed information of FMHA, where MQA is Multi Query Attention and GQA is Group Query Attention.
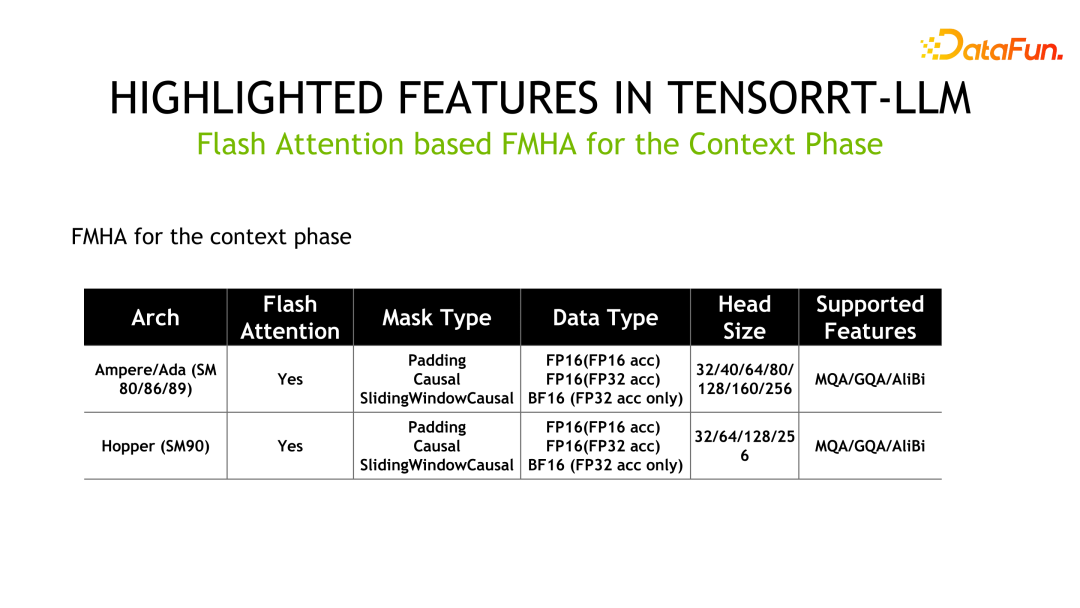
Another Kernel is MMHA (Masked Multi-Head Attention). FMHA is mainly used for calculations in the context phase, while MMHA mainly provides acceleration of attention in the generation phase and provides support for Volta and subsequent architectures. Compared with the implementation of FastTransformer, TensorRT-LLM is further optimized and the performance is improved by up to 2x.

#Another important feature is quantization technology, which achieves inference acceleration with lower precision. Commonly used quantization methods are mainly divided into PTQ (Post Training Quantization) and QAT (Quantization-aware Training). For TensorRT-LLM, the reasoning logic of these two quantization methods is the same. For LLM quantification technology, an important feature is the co-design of algorithm design and engineering implementation, that is, the characteristics of the hardware must be considered at the beginning of the design of the corresponding quantification method. Otherwise, the expected inference speed improvement may not be achieved.

The PTQ quantification steps in TensorRT are generally divided into the following steps. First, quantify the model, and then convert the weights and model into TensorRT-LLM. express. For some customized operations, users also need to write their own kernels. Commonly used PTQ quantification methods include INT8 weight-only, SmoothQuant, GPTQ and AWQ, which are typical co-design methods.

INT8 weight-only directly quantizes the weight to INT8, but the activation value remains as FP16. The advantage of this method is that model storage is reduced by 2x and the storage bandwidth for loading weights is halved, achieving the purpose of improving inference performance. This method is called W8A16 in the industry, that is, the weight is INT8 and the activation value is FP16/BF16 - stored with INT8 precision and calculated in FP16/BF16 format. This method is intuitive, does not change weights, is easy to implement, and has good generalization performance.

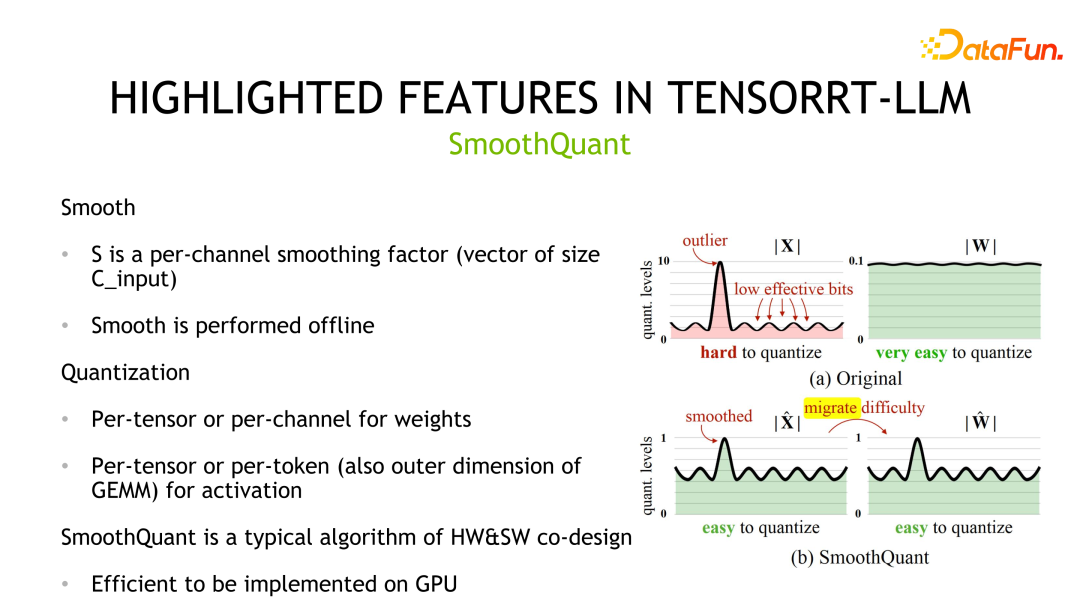
The second quantification method is SmoothQuant, which was jointly designed by NVIDIA and the community. It is observed that weights usually obey Gaussian distribution and are easy to quantize, but there are outliers in the activation values, and the utilization of quantization bits is not high.

SmoothQuant compresses the corresponding distribution by first smoothing the activation value, that is, dividing it by a scale. At the same time, in order to ensure equivalence, it is necessary to The weights are multiplied by the same scale. Afterwards, both weights and activations can be quantified. The corresponding storage and calculation precision can be INT8 or FP8, and INT8 or FP8 TensorCore can be used for calculation. In terms of implementation details, weights support Per-tensor and Per-channel quantization, and activation values support Per-tensor and Per-token quantification.
The third quantization method is GPTQ, a layer-by-layer quantization method achieved by minimizing the reconstruction loss. GPTQ is a weight-only method, and the calculation uses the FP16 data format. This method is used when quantizing large models. Since quantization itself is relatively expensive, the author designed some tricks to reduce the cost of quantization itself, such as Lazy batch-updates and quantizing the weights of all rows in the same order. GPTQ can also be used in conjunction with other methods such as grouping strategies. Moreover, TensorRT-LLM provides different implementation optimization performance for different situations. Specifically, when the batch size is small, cuda core is used to implement it; conversely, when the batch size is large, tensor core is used to implement it.

The fourth quantization method is AWQ. This method considers that not all weights are equally important, only 0.1%-1% of the weights (salient weights) contribute more to the model accuracy, and these weights depend on the activation value distribution rather than the weight distribution. The quantification process of this method is similar to SmoothQuant. The main difference is that scale is calculated based on the activation value distribution.


In addition to quantization, another way to improve TensorRT-LLM performance is to use multi-machine and multi-card inference. In some scenarios, large models are too large to be placed on a single GPU for inference, or they can be put down but the computing efficiency is affected, requiring multiple cards or multiple machines for inference.

TensorRT-LLM currently provides two parallel strategies, Tensor Parallelism and Pipeline Parallelism. TP splits the model vertically and places each part on different devices. This will introduce frequent data communication between devices and is generally used in scenarios with high interconnection between devices, such as NVLINK. Another segmentation method is horizontal segmentation. At this time, there is only one horizontal front, and the corresponding communication method is point-to-point communication, which is suitable for scenarios where the device communication bandwidth is weak.

The last feature to highlight is In-flight batching. Batching is a common practice to improve inference performance, but in LLM inference scenarios, the output length of each sample/request in a batch is unpredictable. If you follow the static batching method, the delay of a batch depends on the longest output in sample/request. Therefore, although the output of the shorter sample/request has ended, the computing resources have not been released, and its delay is the same as the delay of the longest output sample/request. The method of in-flight batching is to insert a new sample/request at the end of the sample/request. In this way, it not only reduces the delay of a single sample/request and avoids resource waste, but also improves the throughput of the entire system.

#3. TensorRT-LLM usage process
TensorRT-LLM is similar to TensorRT. First, you need to obtain a pre-trained model, then use the API provided by TensorRT-LLM to rewrite and reconstruct the model calculation graph, and then use TensorRT. Compile and optimize, and then save it as a serialized engine for inference deployment.

Taking Llama as an example, first install TensorRT-LLM, then download the pre-trained model, then use TensorRT-LLM to compile the model, and finally reasoning.

For debugging model inference, the debugging method of TensorRT-LLM is consistent with TensorRT. One of the optimizations provided thanks to the deep learning compiler, namely TensorRT, is layer fusion. Therefore, if you want to output the results of a certain layer, you need to mark the corresponding layer as the output layer to prevent it from being optimized by the compiler, and then compare and analyze it with the baseline. At the same time, every time a new output layer is marked, the TensorRT engine must be recompiled.

For custom layers, TensorRT-LLM provides many Pytorch-like operators to help users implement functions without having to write the kernel themselves. As shown in the example, the API provided by TensorRT-LLM is used to implement the logic of rms norm, and TensorRT will automatically generate the corresponding execution code on the GPU.

If the user has higher performance requirements or TensorRT-LLM does not provide building blocks to implement the corresponding functions, the user needs to customize the kernel at this time , and packaged as a plugin for use by TensorRT-LLM. The sample code is a sample code that implements SmoothQuant's customized GEMM and encapsulates it into a plugin for TensorRT-LLM to call.

##4. Inference performance of TensorRT-LLM
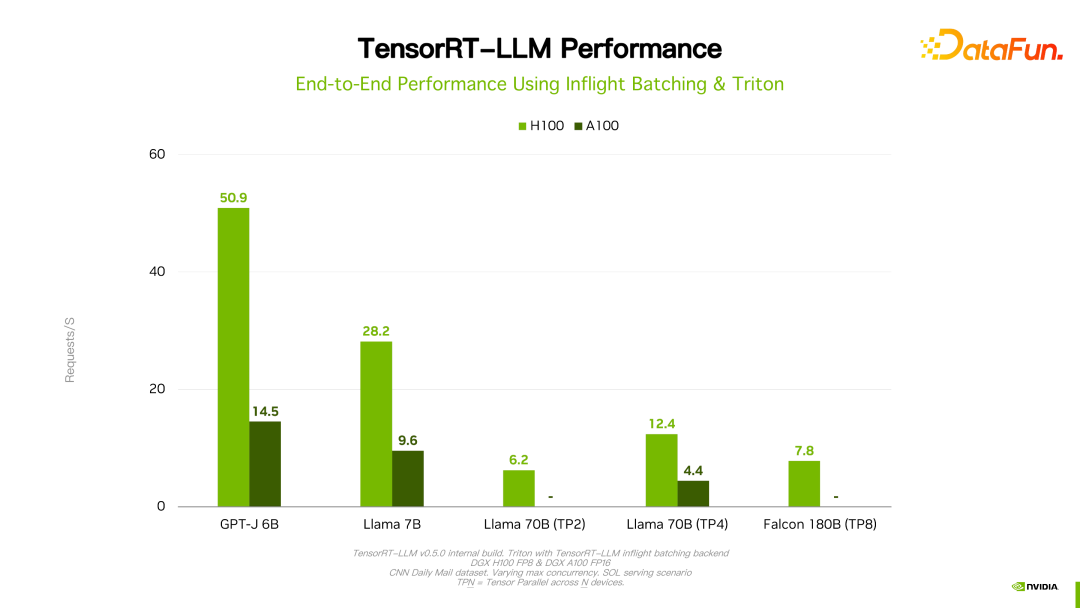
Details such as performance and configuration can be seen on the official website and will not be introduced in detail here. This product has been cooperating with many major domestic manufacturers since its establishment. Through feedback, in general, TensorRT-LLM is the best solution currently from a performance perspective. Since many factors such as technology iteration, optimization methods, and system optimization will affect performance and change very quickly, the performance data of TensorRT-LLM will not be introduced in detail here. If you are interested, you can go to the official website to learn the details. These performances are all reproducible.
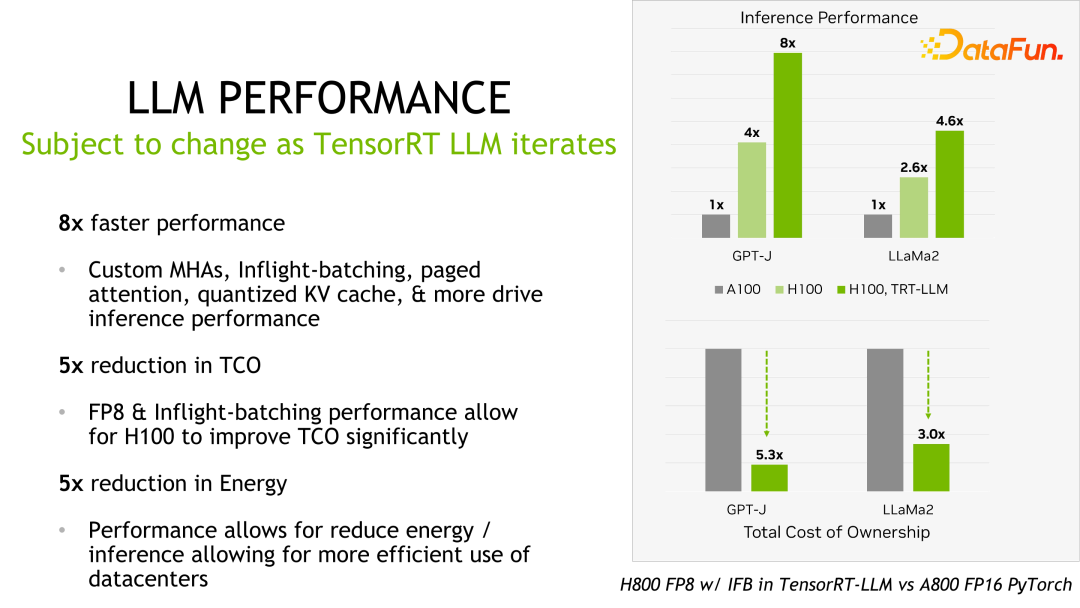
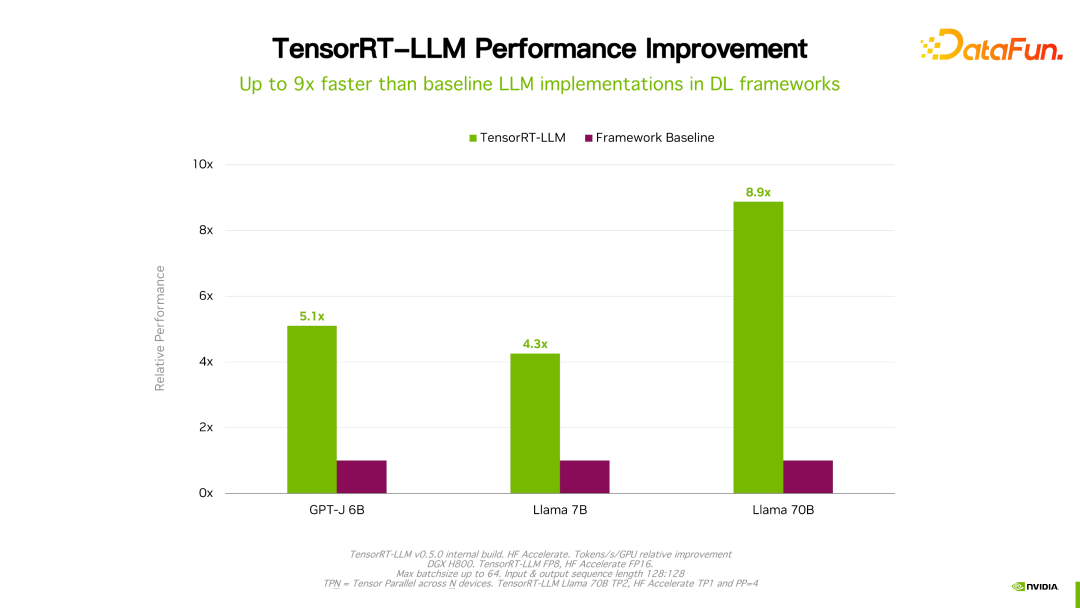
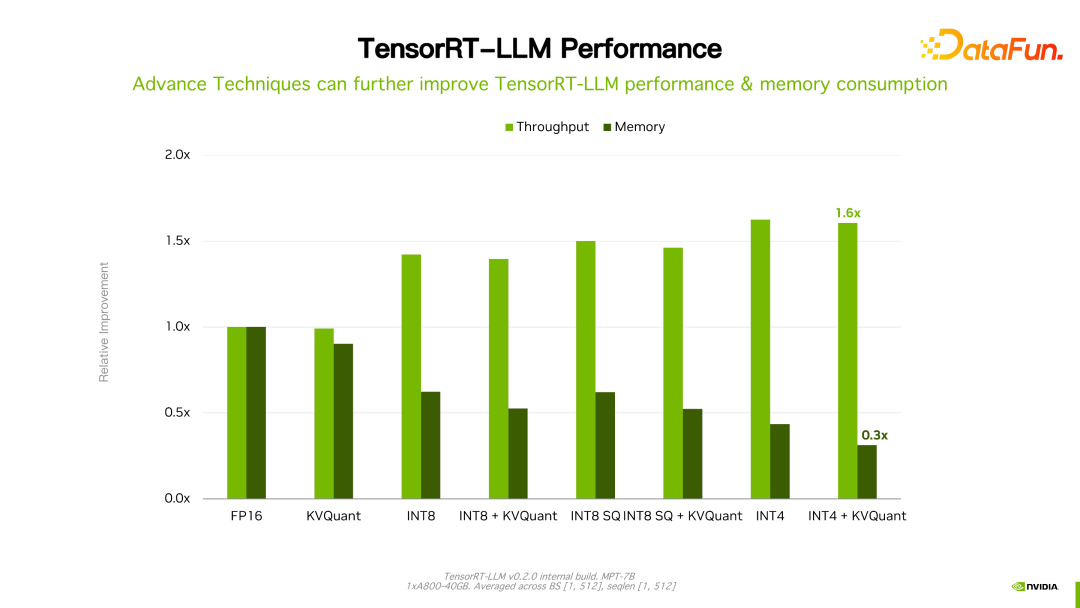
Worth What I mention is that the performance of TensorRT-LLM has continued to improve compared with its previous version. As shown in the figure above, based on FP16, after using KVQuant, the usage of video memory is reduced while maintaining the same speed. Using INT8, you can see a significant improvement in throughput, and at the same time, the memory usage is further reduced. It can be seen that with the continuous evolution of TensorRT-LLM optimization technology, performance will continue to improve. This trend will continue.
##5. The future outlook of TensorRT-LLM
LLM is a scenario where reasoning is very expensive and cost-sensitive. We believe that in order to achieve the next hundred-fold acceleration effect, joint iteration of algorithms and hardware is required, and this goal can be achieved through co-design between software and hardware. The hardware provides lower-precision quantization, while the software perspective uses algorithms such as optimized quantization and network pruning to further improve performance.


# 6. Question and Answer Session
Q1: Does every calculation output need to be dequantized? What should I do if precision overflow occurs during quantization?
A1: Currently TensorRT-LLM provides two types of methods, namely FP8 and the INT4/INT8 quantization method just mentioned. Low-precision If INT8 is used as GEMM, the accumulator will use high-precision data types, such as fp16, or even fp32 to prevent overflow. Regarding inverse quantization, taking fp8 quantization as an example, when TensorRT-LLM optimizes the calculation graph, it may automatically move the inverse quantization node and merge it into other operations to achieve optimization purposes. However, the GPTQ and QAT introduced earlier are currently written in the kernel through hard coding, and there is no unified processing of quantization or dequantization nodes.
Q2: Are you currently doing inverse quantization specifically for specific models?
A2: The current quantification is indeed like this, providing support for different models. We have plans to make a cleaner API or to uniformly support model quantification through configuration items.
Q3: For best practices, should TensorRT-LLM be used directly or combined with Triton Inference Server? Are there any missing features if used together?
A3: Because some functions are not open source, if it is your own serving, you need to do adaptation work. If it is triton, it will be a complete solution.
Q4: There are several quantization methods for quantization calibration, and what is the acceleration ratio? How many points are there in the effects of these quantification schemes? The output length of each example in In-flight branching is unknown. How to do dynamic batching?
A4: You can talk privately about quantification performance. Regarding the effect, we only did basic verification to ensure that the implemented kernel is OK. We cannot guarantee that all quantification algorithms will work in actual business. As a result, there are still some uncontrollable factors, such as the data set used for quantification and its impact. Regarding in-flight batching, it refers to detecting and judging whether the output of a certain sample/request has ended during runtime. If so, and then insert other arriving requests, TensorRT-LLM will not and cannot predict the length of the predicted output.
Q5: Will the C interface and python interface of In-flight branching be consistent? The installation cost of TensorRT-LLM is high. Are there any improvement plans in the future? Will TensorRT-LLM have a different development perspective from VLLM?
A5: We will try our best to provide a consistent interface between c runtime and python runtime, which is already under planning. Previously, the team focused on improving performance and improving functions, and will continue to improve on ease of use in the future. It is not easy to compare directly with vllm here, but NVIDIA will continue to increase investment in TensorRT-LLM development, community and customer support to provide the industry with the best LLM inference solution.
The above is the detailed content of Uncovering the NVIDIA large model inference framework: TensorRT-LLM. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to solve the problem that nvidia driver is not compatible with windows
- Learn new CSS features: Directional clipping overflow:clip
- New breakthrough in HCP laboratory of Sun Yat-sen University: using causal paradigm to upgrade multi-modal large models
- Baidu CIO Li Ying: Large models are an important opportunity in the enterprise office field, and the native reconstruction of AI will change the way intelligent work is done.
- This article will take you to understand the universal large language model independently developed by Tencent - the Hunyuan large model.