

Review of NeurIPS 2023: Tsinghua ToT pushes large models into focus

Recently, as one of the top ten technology blogs in the United States, Latent Space conducted a selected review and summary of the just past NeurIPS 2023 conference.
In the NeurIPS conference, a total of 3586 papers were accepted, 6 of which won awards. While these award-winning papers receive much attention, other papers are equally of outstanding quality and potential. In fact, these papers may even herald the next big breakthrough in AI.
Then let’s take a look together!

##Thesis title: QLoRA: Efficient Finetuning of Quantized LLMs

Paper address: https://openreview.net/pdf?id=OUIFPHEgJU
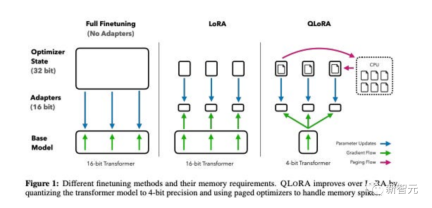
This paper proposes QLoRA, which is a more advanced version of LoRA A memory-efficient but slower version that uses several optimization tricks to save memory.
Overall, QLoRA enables the use of less GPU memory when fine-tuning large language models.
They fine-tuned a new model, named Guanaco, and trained it for 24 hours on just one GPU, outperforming the previous model on the Vicuna benchmark.
At the same time, researchers have also developed other methods, such as 4-bit LoRA quantification, with similar effects.
Paper title: DataComp: In search of the next generation of multimodal datasets

Paper address: https://openreview.net/pdf?id=dVaWCDMBof
Multimodal data Ensembles have played a key role in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4, but their design has not received the same research attention as model architecture or training algorithms.
To address this shortfall in the machine learning ecosystem, researchers introduce DataComp, a new candidate pool of 12.8 billion image-text pairs built around Common Crawl. A test platform for collective experiments.
Users can experiment with DataComp to design new filtering techniques or curate new data sources by running standardized CLIP training code, as well as on 38 downstream test sets. Test the generated models to evaluate them on new datasets.
The results show that the best benchmark DataComp-1B, which allows training a CLIP ViT-L/14 model from scratch, achieves a zero-shot accuracy of 79.2% on ImageNet, compared with OpenAI's CLIP ViT-L/14 model is 3.7 percentage points higher, proving that the DataComp workflow can produce better training sets.
Thesis title: Visual Instruction Tuning

Paper address:https://www.php.cn/link/c0db7643410e1a667d5e01868827a9af
In this paper, The researchers present the first attempt to generate multimodal language-image instruction-following data using GPT-4, which relies solely on language.
By adapting instructions on this generated data, we introduce LLaVA: Large Language and Vision Assistant, a large multimodal model trained end-to-end that connects A visual encoder and LLM for general vision and language understanding.
Early experiments demonstrate that LLaVA demonstrates impressive multimodal chat capabilities, sometimes exhibiting multimodal GPT-4 behavior on unseen images/instructions, and on synthetic multimodal It achieved a relative score of 85.1% compared with GPT-4 on the static instruction following data set.
The synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53% when fine-tuning scientific question answering.

##Thesis title: Tree of Thoughts: Deliberate Problem Solving with Large Language Models

Paper address: https://arxiv.org/pdf/2305.10601.pdf
Language models are getting better and better It is increasingly used for general problem solving across a wide range of tasks, but is still limited to a token-level, left-to-right decision-making process during reasoning. This means they may perform poorly in tasks that require exploration, strategic foresight, or where initial decision-making plays a key role.
To overcome these challenges, researchers introduce a new language model inference framework, Tree of Thoughts (ToT), which generalizes the popular Chain of Thought in prompting language models method and allows exploration on consistent text units (ideas) that serve as intermediate steps in problem solving.
ToT enables language models to make deliberate decisions by considering multiple different reasoning paths and self-evaluating choices to decide on next steps, and looking ahead or backtracking if necessary. Make global choices.
Experiments demonstrate that ToT significantly improves the problem-solving capabilities of language models on three new tasks that require non-trivial planning or search: 24-point games, creative writing, and mini-crossword puzzles . For example, in the 24-point game, while GPT-4 using Chain of Thought prompts only solved 4% of the tasks, ToT achieved a 74% success rate.
Thesis title: Toolformer: Language Models Can Teach Themselves to Use Tools

Paper address: https://arxiv.org/pdf/2302.04761.pdf
The language model shows that Demonstrated ability to solve novel tasks from a small number of examples or textual instructions, especially in large-scale situations. Paradoxically, however, they exhibit difficulties with basic functions such as arithmetic or fact-finding compared to simpler and smaller specialized models.
In this paper, the researchers show that a language model can teach itself to use external tools through a simple API, and achieve the best combination of the two.
They introduced Toolformer, a model trained to decide which APIs to call, when to call them, what parameters to pass and how to best incorporate the results into future token predictions.
This is done in a self-supervised manner, requiring only a small number of demonstrations per API. They integrate a variety of tools, including calculators, question and answer systems, search engines, translation systems, and calendars.
Toolformer achieves significantly improved zero-shot performance on a variety of downstream tasks while competing against larger models, without sacrificing its core language modeling capabilities.
Thesis title: Voyager: An Open-Ended Embodied Agent with Large Language Models

Paper address: https://arxiv.org/pdf/2305.16291.pdf
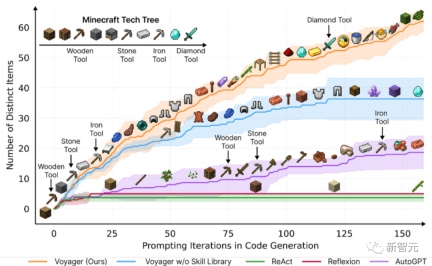
This paper introduces Voyager, the first A learning agent driven by large language models (LLM) that can continuously explore the world, acquire diverse skills, and make independent discoveries in Minecraft.
Voyager consists of three key components:
Automated lessons designed to maximize exploration,
A growing library of executable code skills for storing and retrieving complex behaviors,
A new iterative prompting mechanism that integrates environmental feedback, execution errors and self Validate to improve procedures.
Voyager interacts with GPT-4 through black-box queries, avoiding the need to fine-tune model parameters.
Based on empirical research, Voyager demonstrates strong lifelong learning capabilities within environmental context and demonstrates superior proficiency in playing Minecraft.
It gains access to unique items 3.3 times higher than the previous tech level, travels 2.3 times longer, and unlocks key tech tree milestones 15.3 times faster than the previous tech level.
But while Voyager is able to use its learned skill set to solve novel tasks from scratch in new Minecraft worlds, other techniques are harder to generalize to.
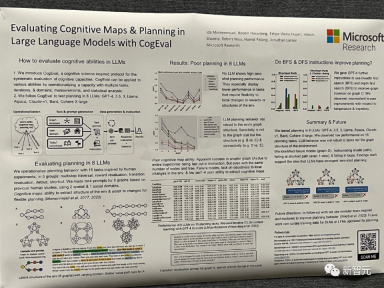
Thesis title: Evaluating Cognitive Maps and Planning in Large Language Models with CogEval

Paper address: https://openreview.net/pdf?id=VtkGvGcGe3
This paper was first proposed CogEval, a protocol inspired by cognitive science for systematically evaluating the cognitive capabilities of large language models.
Secondly, the paper uses the CogEval system to evaluate eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge- 52.4B, Anthropic Claude-1-52B, LLaMA-13B and Alpaca-7B) cognitive mapping and planning capabilities. The task prompts are based on human experiments and are not present in the LLM training set.
Research has found that although LLMs show obvious capabilities in some planning tasks with simpler structures, once the tasks become complex, LLMs will fall into blind spots, including the detection of invalid trajectories. Hallucinations and being stuck in a loop.
These findings do not support the idea that LLMs have plug-and-play planning capabilities. It may be that LLMs do not understand the underlying relational structure behind the planning problem, i.e., the cognitive map, and have problems unfolding goal-directed trajectories based on the underlying structure.
Thesis title: Mamba: Linear-Time Sequence Modeling with Selective State Spaces

Paper address: https://openreview.net/pdf?id=AL1fq05o7H
The author pointed out that at present Many sublinear time architectures, such as linear attention, gated convolution and recurrent models, as well as structured state space models (SSMs), aim to solve the computational inefficiency of Transformer when processing long sequences. However, these models do not perform as well as attention models on important domains such as language. The authors believe that a key weakness of these
types is their inability to perform content-based reasoning, and make some improvements.
First, simply making the SSM parameters a function of the input can address the weaknesses of its discrete modality, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token.
Second, although this change prevents the use of efficient convolutions, the authors designed a hardware-aware parallel algorithm in loop mode. Integrating these selective SSMs into a simplified end-to-end neural network architecture requires no attention mechanism or even an MLP module (Mamba).
Mamba performs well in inference speed (5x faster than Transformers) and scales linearly with sequence length, improving performance on real data up to millions of lengths sequence.
As a universal sequence model backbone, Mamba has achieved state-of-the-art performance in multiple fields including language, audio, and genomics. In terms of language modeling, the Mamba-1.4B model outperforms the Transformers model of the same size in both pre-training and downstream evaluation, and rivals its Transformers model twice the size.

Although these papers did not win awards in 2023, such as Mamba, as a technical model that can revolutionize language model architecture, it is too early to evaluate its impact.
How will NeurIPS go next year, and how will the field of artificial intelligence and neural information systems develop in 2024? Although there are currently different opinions, who can guarantee it? let us wait and see.
The above is the detailed content of Review of NeurIPS 2023: Tsinghua ToT pushes large models into focus. For more information, please follow other related articles on the PHP Chinese website!

 Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AM
Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AMThis article explores the growing concern of "AI agency decay"—the gradual decline in our ability to think and decide independently. This is especially crucial for business leaders navigating the increasingly automated world while retainin
 How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AM
How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AMEver wondered how AI agents like Siri and Alexa work? These intelligent systems are becoming more important in our daily lives. This article introduces the ReAct pattern, a method that enhances AI agents by combining reasoning an
 Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM
Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM"I think AI tools are changing the learning opportunities for college students. We believe in developing students in core courses, but more and more people also want to get a perspective of computational and statistical thinking," said University of Chicago President Paul Alivisatos in an interview with Deloitte Nitin Mittal at the Davos Forum in January. He believes that people will have to become creators and co-creators of AI, which means that learning and other aspects need to adapt to some major changes. Digital intelligence and critical thinking Professor Alexa Joubin of George Washington University described artificial intelligence as a “heuristic tool” in the humanities and explores how it changes
 Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AM
Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AMLangChain is a powerful toolkit for building sophisticated AI applications. Its agent architecture is particularly noteworthy, allowing developers to create intelligent systems capable of independent reasoning, decision-making, and action. This expl
 What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AM
What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AMRadial Basis Function Neural Networks (RBFNNs): A Comprehensive Guide Radial Basis Function Neural Networks (RBFNNs) are a powerful type of neural network architecture that leverages radial basis functions for activation. Their unique structure make
 The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AM
The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AMBrain-computer interfaces (BCIs) directly link the brain to external devices, translating brain impulses into actions without physical movement. This technology utilizes implanted sensors to capture brain signals, converting them into digital comman
 Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AM
Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AMThis "Leading with Data" episode features Ines Montani, co-founder and CEO of Explosion AI, and co-developer of spaCy and Prodigy. Ines offers expert insights into the evolution of these tools, Explosion's unique business model, and the tr
 A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AM
A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AMThis article explores Retrieval Augmented Generation (RAG) systems and how AI agents can enhance their capabilities. Traditional RAG systems, while useful for leveraging custom enterprise data, suffer from limitations such as a lack of real-time dat


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver Mac version
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

WebStorm Mac version
Useful JavaScript development tools

