
Home >System Tutorial >LINUX >Machine learning application for automated operation and maintenance of DBMS
Machine learning application for automated operation and maintenance of DBMS

- 王林forward
- 2024-01-24 12:21:16751browse
A database management system (DBMS) is a critical part of any data-intensive application. They can handle large amounts of data and complex workloads, but they are also difficult to manage because there are hundreds or thousands of "knobs" (configuration variables) that control various factors, such as how much memory to use for caching and writing to disk. frequency. Organizations often have to hire experts to do the tuning, and experts are too expensive for many organizations. Students and researchers in Carnegie Mellon University's Database Research Group are developing a new tool called OtterTune that automatically finds the right settings for the "knobs" of a DBMS. The purpose of the tool is to allow anyone to deploy a DBMS, even without any database administration expertise.
OtterTune is different from other DBMS setup tools because it uses knowledge of previous DBMS tuning to tune a new DBMS, which significantly reduces the time and resources consumed. OtterTune achieves this by maintaining a knowledge base accumulated from previous tuning. This accumulated data is used to build machine learning (ML) models to capture the DBMS's reaction to different settings. OtterTune uses these models to guide experimentation with new applications, recommending configurations that improve end goals such as reducing latency and increasing throughput.
In this article, we will discuss each of OtterTune’s machine learning pipeline components and how they interact to tune your DBMS setup. We then evaluate OtterTune's tuning performance on MySQL and Postgres, comparing its optimal configurations with DBAs and other automated tuning tools.
OtterTune is an open source tool developed by students and researchers in the Database Research Group at Carnegie Mellon University. All code is hosted on Github and released under the Apache License 2.0 license.
How OtterTune worksThe picture below shows the OtterTune components and workflow
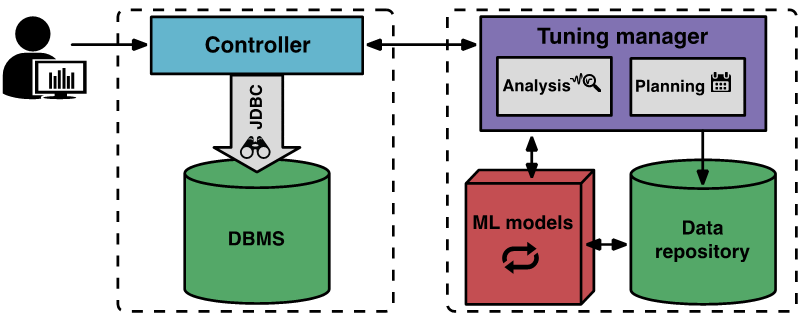
The tuning process begins when the user tells OtterTune the end goal to be tuned (for example, latency or throughput), and the client controller program connects to the target DBMS and collects the Amazon EC2 instance type and current configuration.
Then, the controller starts the first observation period to observe and record the final goal. After the observation is complete, the controller collects DBMS internal metrics, such as MySQL disk page read and write counts. The controller returns this data to the tuning manager program.
OtterTune's tuning manager saves received metric data to the knowledge base. OtterTune uses these results to calculate the next configuration for the target DBMS and returns it to the controller along with the estimated performance improvement. The user can decide whether to continue or terminate the tuning process.
NoticeOtterTune maintains a blacklist of "knobs" for each supported DBMS version, including those that are insignificant for tuning (such as the path to save the data file), or those that have serious or hidden consequences (such as data loss) part. OtterTune provides this blacklist to the user at the beginning of the tuning process, and the user can add other "knobs" they want OtterTune to avoid.
OtterTune has some predetermined assumptions that may cause certain limitations for some users. For example, it assumes that the user has administrator rights in order for the controller to modify the DBMS configuration. Otherwise, users must deploy a copy of the database on other hardware for OtterTune to perform tuning experiments. This requires users to either reproduce the workload or forward queries to the production DBMS. See our paper for complete presuppositions and restrictions.
Machine Learning PipelineThe following figure is the process of OtterTune ML pipeline processing data, and all observation results are saved in the knowledge base.
OtterTune first feeds observation data to the Workload Characterization component, which identifies a small set of DBMS metrics that most effectively capture performance changes and salient characteristics of different workloads.
Next step, the "Knob Identification component" generates a knob ranking list, including which knobs have the greatest impact on DBMS performance. OtterTune then "feeds" all this information to the Automatic Tuner, which maps the target DBMS's workload to the closest workload in the knowledge base and reuses this workload data to generate a better configuration.
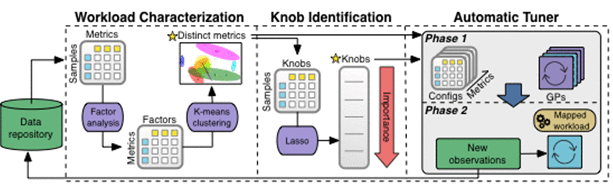
Let’s dig deeper into each component of the machine learning pipeline below.
Workload Characterization: OtterTune leverages the DBMS's internal runtime metrics to characterize the behavior of a certain workload. These metrics accurately represent the workload because they capture multiple aspects of the workload's behavior. However, many indicators are redundant: some represent the same measure in different units, others represent some independent component of the DBMS, but their values are highly correlated. Sorting out redundant measures is important to reduce the complexity of machine learning models. Therefore, we cluster the DBMS metrics based on correlation and select the most representative one, specifically the one closest to the median. Subsequent components of machine learning will use these measures.
Knob identification: A DBMS can have hundreds of knobs, but only some of them affect performance. OtterTune uses a popular feature-selection technique called Lasso to determine which knobs have the greatest impact on the overall performance of your system. Using this technique to process the data in the knowledge base, OtterTune was able to determine the order of importance of the DBMS knobs.
Next, OtterTune must decide how many knobs to use when making configuration recommendations. Using too many knobs will significantly increase OtterTune’s tuning time, while using too few knobs will make it difficult to find the best configuration. OtterTune uses an incremental approach to automate this process, gradually increasing the number of knobs used during a tuning session. This approach allows OtterTune to explore and fine-tune the configuration with a small number of the most important knobs first, and then expand to consider other knobs.
Automatic tuner: The automatic tuner component uses a two-step analysis method to decide which configuration to recommend after each observation phase.
First, the system uses the performance data found by the workload characterization component to identify the historical tuning process that is closest to the current target DBMS workload, comparing the two metrics to identify which values are similar for different knob settings. Reaction.
OtterTune then tries another knob configuration, applying a statistical model to the collected data and the closest workload data in the knowledge base. This model lets OtterTune predict how the DBMS will perform under every possible configuration. OtterTune tunes the next configuration, alternating between exploration (gathering information to improve the model) and exploitation (greedily approaching the target metric).
accomplishOtterTune is written in Python.
For the workload characterization and knob identification components, runtime performance is not a major consideration, so we use scikit-learn to implement the corresponding machine learning algorithm. These algorithms run in background processes and absorb newly generated data into the knowledge base.
For automatic tuning components, machine learning algorithms are very critical. Each observation phase needs to be run after completion, absorbing new data so OtterTune can pick the next knob to test. Since performance needs to be considered, we use TensorFlow to implement it.
To collect DBMS hardware, knob configuration, and runtime performance metrics, we integrated the OLTP-Bench benchmark framework into OtterTune’s controller.
experimental designWe compared OtterTune’s best-in-class configurations for MySQL and Postgres with the following configuration options for evaluation:
Default: DBMS initial configuration
Tuning script: Configuration made by an open source tuning suggestion tool
DBA: Configuration selected by human DBA
RDS: Apply a custom configuration of an Amazon developer-managed DBMS to the same EC2 instance type.
We performed all experiments on Amazon EC2 Spot instances. Each experiment runs on two instances, of type m4.large and m3.xlarge: one for the OtterTune controller and one for the target DBMS deployment. The OtterTune tuning manager and knowledge base are deployed locally on a 20-core 128G memory server.
The workload uses TPC-C, which is the industry standard for evaluating the performance of online trading systems.
EvaluateWe measured latency and throughput for each of the databases in the experiment — MySQL and Postgres — and the graphs below show the results. The first chart shows the number of "99th percentile latency", which represents the "worst case" time it takes to complete a transaction. The second chart shows the throughput results, measured as the average number of transactions executed per second.
MySQL Experiment ResultsThe optimal configuration generated by OtterTune compared to the configuration of the tuning script and RDS, OtterTune reduced MySQL latency by approximately 60% and increased throughput by 22% to 35%. OtterTune also generates a configuration that is almost as good as DBA.
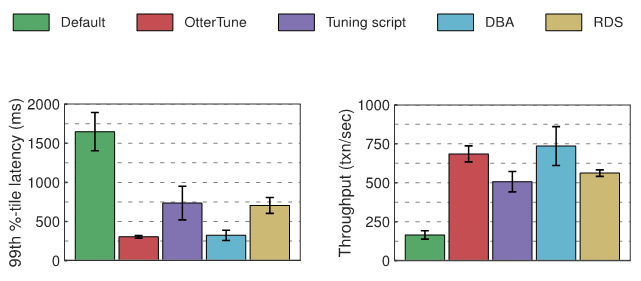
Under TPC-C loads, only a few MySQL knobs significantly affect performance. The configuration of OtterTune and DBA sets these knobs to good values. RDS performed slightly worse because one knob was assigned a suboptimal value. The tuning script performed the worst because only one knob was modified.
Postgres Experimental Results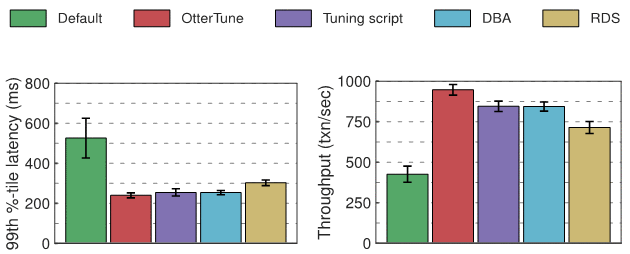
In terms of latency, compared to the Postgres default configuration, the configurations of OtterTune, tuning tools, DBA and RDS have achieved similar improvements. We can probably attribute this to the network overhead between the OLTP-Bench client and the DBMS. In terms of throughput, Postgres is 12% higher than DBA and tuning scripts when configured with OtterTune, and 32% higher than RDS.
ConclusionOtterTune automates the process of finding optimal values for DBMS configuration knobs. It tunes a newly deployed DBMS by reusing training data collected from previous tuning processes. Because OtterTune does not need to generate an initialization data set to train its machine learning model, tuning time is greatly reduced.
What happens next? In keeping with the growing popularity of DBaaS (where remote login to the DBMS host is not possible), OtterTune will soon be able to automatically probe the hardware capabilities of the target DBMS without requiring remote login.
To learn more about OtterTune, check out our paper and the code on GitHub. Keep an eye on this site as we will soon make OtterTune an online tuning service.
The above is the detailed content of Machine learning application for automated operation and maintenance of DBMS. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- What is Red Hat Linux?
- Linux open source brother Red Hat has been acquired by IBM for US$34 billion
- How to use the linux zip compression command
- How to filter and classify logs through Linux command line tools?
- Oracle, SUSE and CIQ join forces to form Open Enterprise Linux Association to jointly develop distributions compatible with Red Hat RHEL Enterprise Edition