

 Technology peripheralsAIThe Swin moment of the visual Mamba model, the Chinese Academy of Sciences, Huawei and others launched VMamba
Technology peripheralsAIThe Swin moment of the visual Mamba model, the Chinese Academy of Sciences, Huawei and others launched VMambaThe Swin moment of the visual Mamba model, the Chinese Academy of Sciences, Huawei and others launched VMamba

Transformer’s position in the field of large models is unshakable. However, as the model scale expands and the sequence length increases, the limitations of the traditional Transformer architecture begin to become apparent. Fortunately, the advent of Mamba is quickly changing this situation. Its outstanding performance immediately caused a sensation in the AI community. The emergence of Mamba has brought huge breakthroughs to large-scale model training and sequence processing. Its advantages are spreading rapidly in the AI community, bringing great hope for future research and applications.
Last Thursday, the introduction of Vision Mamba (Vim) has demonstrated its great potential to become the next generation backbone of the visual basic model. Just one day later, Researchers from the Chinese Academy of Sciences, Huawei, and Pengcheng Laboratory proposed VMamba:A visual Mamba model with global receptive field and linear complexity. This work marks the arrival of the visual Mamba model Swin moment.

- ##Paper title: VMamba: Visual State Space Model
- Paper address: https://arxiv.org/abs/2401.10166
- Code address: https://github.com/MzeroMiko/VMamba
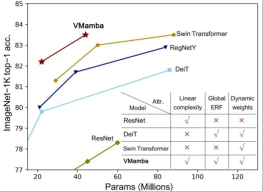
CNN and Visual Transformer (ViT) are currently the two most mainstream basic visual models. Although CNN has linear complexity, ViT has more powerful data fitting capabilities, but at the cost of higher computational complexity. Researchers believe that ViT has strong fitting ability because it has a global receptive field and dynamic weights. Inspired by the Mamba model, researchers designed a model that has both excellent properties under linear complexity, namely the Visual State Space Model (VMamba). Extensive experiments have proven that VMamba performs well in various visual tasks. As shown in the figure below, VMamba-S achieves 83.5% accuracy on ImageNet-1K, which is 3.2% higher than Vim-S and 0.5% higher than Swin-S.
Method introduction

The success of VMamba The key lies in the use of the S6 model, which was originally designed to solve natural language processing (NLP) tasks. Unlike ViT's attention mechanism, the S6 model effectively reduces quadratic complexity to linearity by interacting each element in the 1D vector with previous scan information. This interaction makes VMamba more efficient when processing large-scale data. Therefore, the introduction of the S6 model laid a solid foundation for VMamba's success.
However, since visual signals (such as images) do not have a natural orderliness like text sequences, the data scanning method in S6 cannot simply be directly performed on visual signals. application. For this purpose, researchers designed a Cross-Scan scanning mechanism. Cross-Scan module (CSM) adopts a four-way scanning strategy, that is, scanning from the four corners of the feature map simultaneously (see the figure above). This strategy ensures that each element in the feature integrates information from all other locations in different directions, thus forming a global receptive field without increasing linear computational complexity.

Based on CSM, the author designed the 2D-selective-scan (SS2D) module. As shown in the figure above, SS2D consists of three steps:
- #scan expand Flatten a 2D feature in 4 different directions (upper left, lower right, lower left, upper right) is a 1D vector.
- The S6 block independently sends the four 1D vectors obtained in the previous step to the S6 operation.
- scan merge fuses the four 1D vectors obtained into a 2D feature output.

The above picture is the VMamba structure diagram proposed in this article. The overall framework of VMamba is similar to the mainstream visual model. The main difference lies in the operators used in the basic module (VSS block). VSS block uses the 2D-selective-scan operation introduced above, namely SS2D. SS2D ensures that VMamba achieves the global receptive field at the linear complexity cost.
Experimental results
ImageNet classification

##passed Comparing the experimental results, it is not difficult to see that under similar parameter amounts and FLOPs:
- VMamba-T achieved a performance of 82.2%, exceeding RegNetY- 4G reached 2.2%, DeiT-S reached 2.4%, and Swin-T reached 0.9%.
- VMamba-S achieved a performance of 83.5%, exceeding RegNetY-8G by 1.8% and Swin-S by 0.5%.
- VMamba-B achieved a performance of 83.2% (there is a bug, the correct result will be updated on the Github page as soon as possible), which is 0.3% higher than RegNetY.
These results are much higher than the Vision Mamba (Vim) model, fully validating the potential of VMamba.
COCO target detection
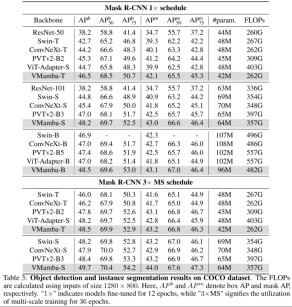
On the COOCO data set, VMamba also Maintaining excellent performance: In the case of fine-tune 12 epochs, VMamba-T/S/B reached 46.5%/48.2%/48.5% mAP respectively, exceeding Swin-T/S/B by 3.8%/3.6%/1.6 % mAP, exceeding ConvNeXt-T/S/B by 2.3%/2.8%/1.5% mAP. These results verify that VMamba fully works in downstream visual experiments, demonstrating its potential to replace mainstream basic visual models.
ADE20K Semantic Segmentation

On ADE20K, VMamba also shows Excellent performance. The VMamba-T model achieves 47.3% mIoU at 512 × 512 resolution, a score that surpasses all competitors, including ResNet, DeiT, Swin, and ConvNeXt. This advantage can still be maintained under the VMamba-S/B model.
Analysis Experiment
Effective Receptive Field

VMamba has a global effective receptive field, and only DeiT among other models has this feature. However, it is worth noting that the cost of DeiT is quadratic complexity, while VMamaba is linear complexity.
Input scale scaling
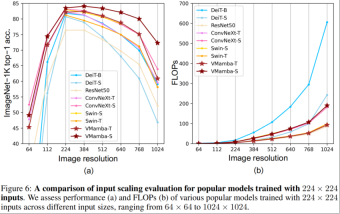
- Above picture (a) It is shown that VMamba exhibits the most stable performance (without fine-tuning) under different input image sizes. Interestingly, as the input size increases from 224 × 224 to 384 × 384, only VMamba shows a significant increase in performance (VMamba-S from 83.5% to 84.0%), highlighting its robustness to input image size changes sex.
- The above figure (b) shows that the complexity of the VMamba series models increases linearly as the input becomes larger, which is consistent with the CNN model.
Finally, let us look forward to more Mamba-based vision models being proposed, alongside CNNs and ViTs, to provide a third option for basic vision models.
The above is the detailed content of The Swin moment of the visual Mamba model, the Chinese Academy of Sciences, Huawei and others launched VMamba. For more information, please follow other related articles on the PHP Chinese website!

 One Prompt Can Bypass Every Major LLM's SafeguardsApr 25, 2025 am 11:16 AM
One Prompt Can Bypass Every Major LLM's SafeguardsApr 25, 2025 am 11:16 AMHiddenLayer's groundbreaking research exposes a critical vulnerability in leading Large Language Models (LLMs). Their findings reveal a universal bypass technique, dubbed "Policy Puppetry," capable of circumventing nearly all major LLMs' s
 5 Mistakes Most Businesses Will Make This Year With SustainabilityApr 25, 2025 am 11:15 AM
5 Mistakes Most Businesses Will Make This Year With SustainabilityApr 25, 2025 am 11:15 AMThe push for environmental responsibility and waste reduction is fundamentally altering how businesses operate. This transformation affects product development, manufacturing processes, customer relations, partner selection, and the adoption of new
 H20 Chip Ban Jolts China AI Firms, But They've Long Braced For ImpactApr 25, 2025 am 11:12 AM
H20 Chip Ban Jolts China AI Firms, But They've Long Braced For ImpactApr 25, 2025 am 11:12 AMThe recent restrictions on advanced AI hardware highlight the escalating geopolitical competition for AI dominance, exposing China's reliance on foreign semiconductor technology. In 2024, China imported a massive $385 billion worth of semiconductor
 If OpenAI Buys Chrome, AI May Rule The Browser WarsApr 25, 2025 am 11:11 AM
If OpenAI Buys Chrome, AI May Rule The Browser WarsApr 25, 2025 am 11:11 AMThe potential forced divestiture of Chrome from Google has ignited intense debate within the tech industry. The prospect of OpenAI acquiring the leading browser, boasting a 65% global market share, raises significant questions about the future of th
 How AI Can Solve Retail Media's Growing PainsApr 25, 2025 am 11:10 AM
How AI Can Solve Retail Media's Growing PainsApr 25, 2025 am 11:10 AMRetail media's growth is slowing, despite outpacing overall advertising growth. This maturation phase presents challenges, including ecosystem fragmentation, rising costs, measurement issues, and integration complexities. However, artificial intell
 'AI Is Us, And It's More Than Us'Apr 25, 2025 am 11:09 AM
'AI Is Us, And It's More Than Us'Apr 25, 2025 am 11:09 AMAn old radio crackles with static amidst a collection of flickering and inert screens. This precarious pile of electronics, easily destabilized, forms the core of "The E-Waste Land," one of six installations in the immersive exhibition, &qu
 Google Cloud Gets More Serious About Infrastructure At Next 2025Apr 25, 2025 am 11:08 AM
Google Cloud Gets More Serious About Infrastructure At Next 2025Apr 25, 2025 am 11:08 AMGoogle Cloud's Next 2025: A Focus on Infrastructure, Connectivity, and AI Google Cloud's Next 2025 conference showcased numerous advancements, too many to fully detail here. For in-depth analyses of specific announcements, refer to articles by my
 Talking Baby AI Meme, Arcana's $5.5 Million AI Movie Pipeline, IR's Secret Backers RevealedApr 25, 2025 am 11:07 AM
Talking Baby AI Meme, Arcana's $5.5 Million AI Movie Pipeline, IR's Secret Backers RevealedApr 25, 2025 am 11:07 AMThis week in AI and XR: A wave of AI-powered creativity is sweeping through media and entertainment, from music generation to film production. Let's dive into the headlines. AI-Generated Content's Growing Impact: Technology consultant Shelly Palme


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Atom editor mac version download
The most popular open source editor

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SublimeText3 English version
Recommended: Win version, supports code prompts!

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

