
Home >Technology peripherals >AI >Efficiently improve detection capabilities: break through the detection of small targets above 200 meters
Efficiently improve detection capabilities: break through the detection of small targets above 200 meters

- PHPzforward
- 2024-01-15 19:51:291144browse
This article is reprinted with the authorization of the Autonomous Driving Heart public account. Please contact the source for reprinting.
3D Object Detection based on LiDAR point cloud has always been a very classic problem. Both academia and industry have proposed various models to improve accuracy, speed and robustness. sex. However, due to the complex outdoor environment, the performance of Object Detection for outdoor point clouds is not very good. Lidar point clouds are sparse in nature. How to solve this problem in a targeted manner? The paper gives its own answer: extract information based on the aggregation of time series information.
1. Paper information

##2. Introduction

3. Method
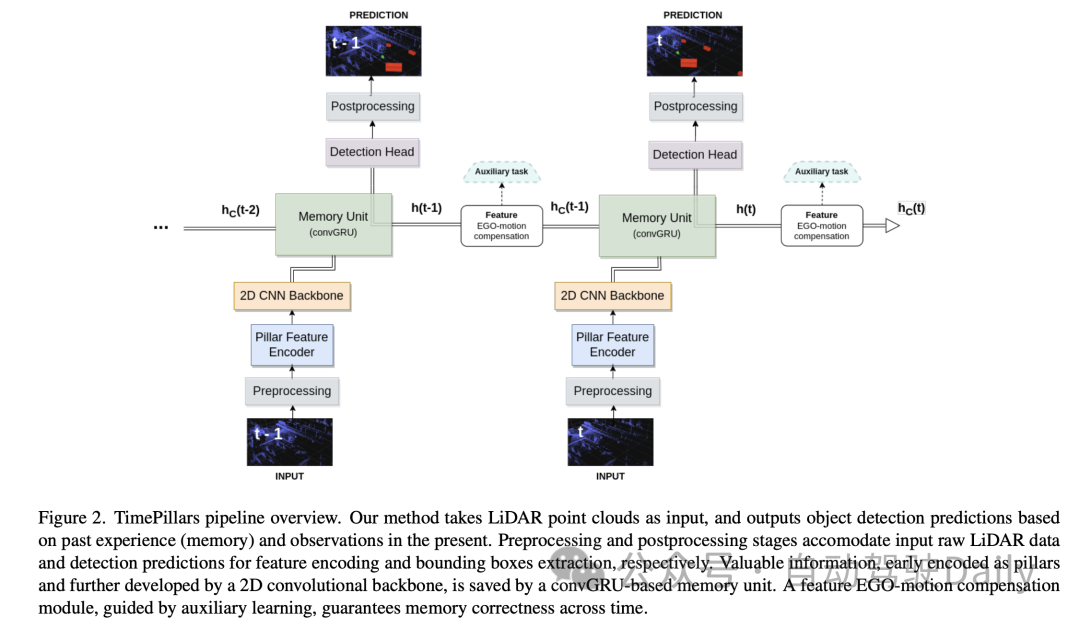
3.1 Input preprocessing
In the "input preprocessing" part of this paper, the author adopts The "pillarization" technology is used to process the input point cloud data. This method is different from conventional voxelization, which segments the point cloud into vertical columnar structures only in the horizontal direction (x and y axes) while maintaining a fixed height in the vertical direction (z axis). Doing so keeps the network input dimensions consistent and allows efficient processing using 2D convolutions.
However, one problem with Pillarisation is that it produces many empty columns, resulting in very sparse data. To solve this problem, the paper proposes the use of dynamic voxelization technology. This technique avoids the need to have a predefined number of points for each column, thereby eliminating the need for truncation or filling operations on each column. Instead, the entire point cloud data is processed as a whole to match the required total number of points, here set to 200,000 points. The benefit of this preprocessing method is that it minimizes the loss of information and makes the generated data representation more stable and consistent.
3.2 Model architecture
Then for the Model architecture, the author introduces in detail a model consisting of a Pillar Feature Encoder (Pillar Feature Encoder), a 2D Convolutional Neural Network (CNN) backbone and a detection head. Neural network architecture.
- Pillar Feature Encoder: This part maps the preprocessed input tensor into a Bird's Eye View (BEV) pseudo image. After using dynamic voxelization, the simplified PointNet is adjusted accordingly. The input is processed by 1D convolution, batch normalization and ReLU activation function, resulting in a tensor with shape , where represents the number of channels. Before the final scatter max layer, max pooling is applied to the channels, forming a latent space of shape . Since the initial tensor is encoded as , which becomes after the previous layer, the max pooling operation is removed.
- Backbone: Using the 2D CNN backbone architecture proposed in the original columnar paper due to its superior depth efficiency. The latent space is reduced using three downsampling blocks (Conv2D-BN-ReLU) and restored using three upsampling blocks and transposed convolution, with the output shape being .
- Memory Unit: Model the memory of the system as a recurrent neural network (RNN), specifically using convolutional GRU (convGRU), which is the convolutional version of Gated Recurrent Unit. The advantage of convolutional GRU is that it avoids the vanishing gradient problem and improves efficiency while maintaining spatial data characteristics. Compared to other options such as LSTM, GRU has fewer trainable parameters due to its smaller number of gates and can be considered a memory regularization technique (reducing the complexity of the hidden states). By merging operations of similar nature, the number of required convolutional layers is reduced, making the unit more efficient.
- Detection Head: A simple modification to SSD (Single Shot MultiBox Detector). The core concept of SSD is retained, that is, single pass without region proposal, but the use of anchor boxes is eliminated. Directly outputting predictions for each cell in the grid, although losing the cell multi-object detection capability, avoids tedious and often imprecise anchor box parameter adjustments and simplifies the inference process. The linear layer handles the respective outputs of classification and localization (position, size, and angle) regression. Only the size uses an activation function (ReLU) to prevent taking negative values. In addition, unlike related literature, this paper avoids the problem of direct angle regression by independently predicting the sine and cosine components of the vehicle's driving direction and extracting angles from them.
3.3 Feature Ego-Motion Compensation
In this part of the paper, the author discusses how to process the hidden state features output by the convolutional GRU, which are the coordinate system of the previous frame expressed. If stored directly and used to calculate the next prediction, a spatial mismatch will occur due to ego-motion.
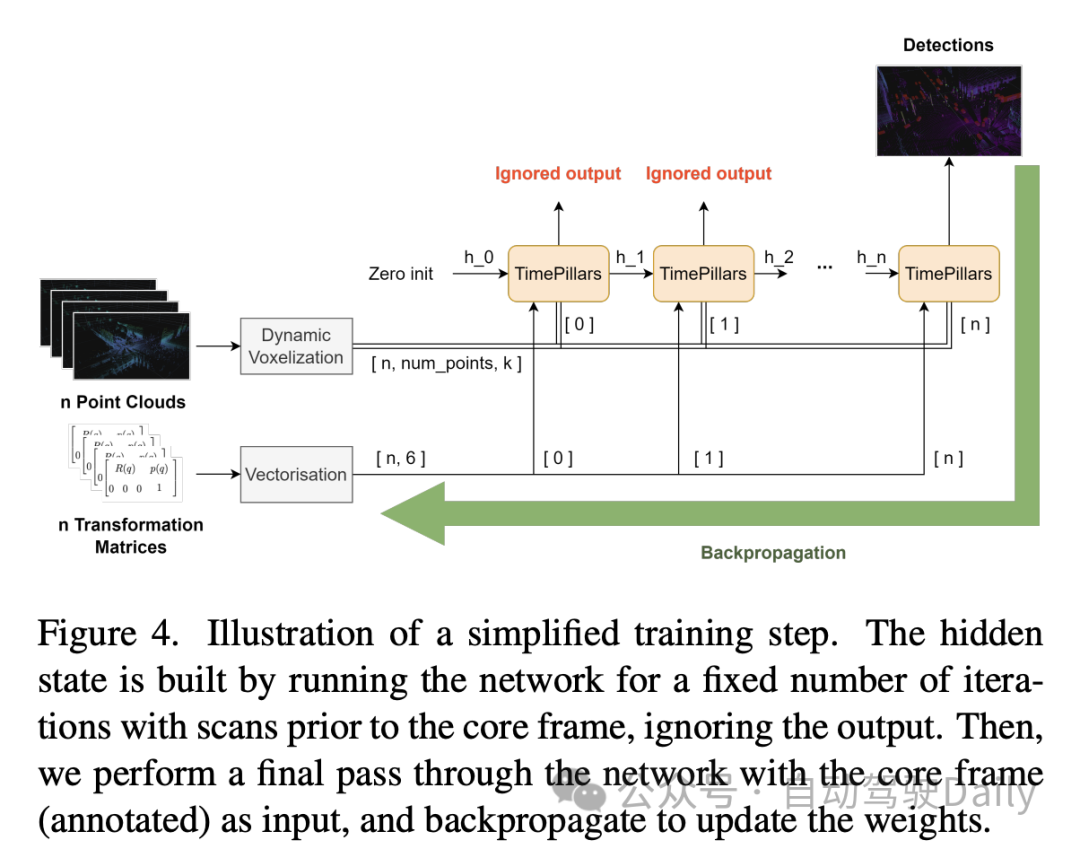
In order to perform the conversion, different techniques can be applied. Ideally, the corrected data would be fed into the network rather than transformed within the network. However, this is not the method proposed in the paper, as it requires resetting the hidden states at each step in the inference process, transforming the previous point clouds, and propagating them throughout the network. Not only is this inefficient, it defeats the purpose of using RNNs. Therefore, in a loop context, compensation needs to be done at the feature level. This makes the hypothetical solution more efficient, but also makes the problem more complex. Traditional interpolation methods can be used to obtain features in transformed coordinate systems.
In contrast, the paper, inspired by the work of Chen et al., proposes to use convolution operations and auxiliary tasks to perform transformations. Considering the limited details of the aforementioned work, the paper proposes a customized solution to this problem.
The approach taken by the paper is to provide the network with the information needed to perform feature transformation through an additional convolutional layer. The relative transformation matrix between two consecutive frames is first calculated, i.e. the operations required to successfully transform features. Then, extract the 2D information (rotation and translation parts) from it:
4. Experiment
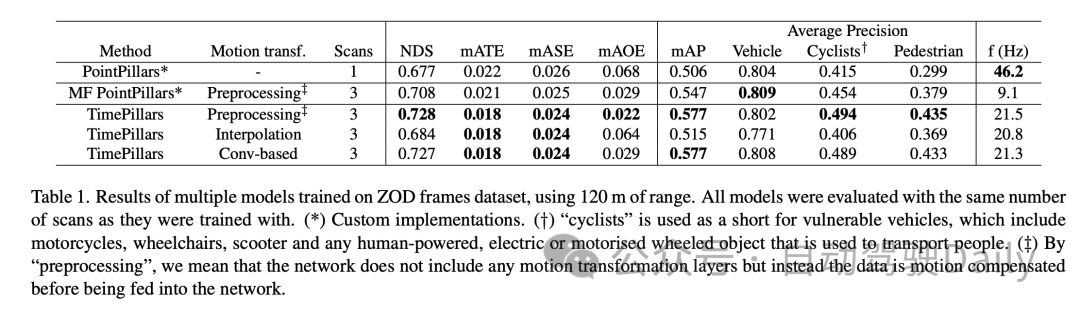

In the performance comparison within different distance ranges, it can be seen that TimePillars performs better in each range. For the vehicle category, the detection accuracy of TimePillars in the ranges of 0 to 50 meters, 50 to 100 meters and more than 100 meters is 0.884, 0.776 and 0.591 respectively, which are all higher than the performance of PointPillars in the same range. This shows that TimePillars has higher accuracy in vehicle detection, both at close and far distances. TimePillars also demonstrated better detection performance when dealing with vulnerable vehicles (such as motorcycles, wheelchairs, electric scooters, etc.). Especially in the range of more than 100 meters, the detection accuracy of TimePillars is 0.178, while PointPillars is only 0.036, showing significant advantages in long-distance detection. For pedestrian detection, TimePillars also showed better performance, especially in the range of 50 to 100 meters, with a detection accuracy of 0.350, while PointPillars was only 0.211. Even at longer distances (more than 100 meters), TimePillars still achieves a certain level of detection (accuracy of 0.032), while PointPillars perform zero at this range.
These experimental results highlight the superior performance of TimePillars in handling object detection tasks in different distance ranges. Whether at close range or at the more challenging long range, TimePillars provide more accurate and reliable detection results, which are critical to the safety and efficiency of autonomous vehicles.
5. Discussion

First of all, the main advantage of the TimePillars model is its effectiveness for long-distance object detection. By adopting dynamic voxelization and convolutional GRU structure, the model is better able to handle sparse lidar data, especially in long-distance object detection. This is critical for the safe operation of autonomous vehicles in complex and changing road environments. In addition, the model also shows good performance in terms of processing speed, which is essential for real-time applications. On the other hand, TimePillars adopts a convolution-based method for Motion Compensation, which is a major improvement over traditional methods. This approach ensures the correctness of the transformation through auxiliary tasks during training, improving the accuracy of the model when handling moving objects.
However, the research of the paper also has some limitations. First, while TimePillars performs well at handling distant object detection, this performance increase may come at the expense of some processing speed. While the speed of the model is still suitable for real-time applications, it is still a decrease compared to single-frame methods. In addition, the paper mainly focuses on LiDAR data and does not consider other sensor inputs, such as cameras or radars, which may limit the application of the model in more complex multi-sensor environments.
That is to say, TimePillars has shown significant advantages in 3D lidar object detection for autonomous vehicles, especially in long-distance detection and Motion Compensation. Despite the slight trade-off in processing speed and limitations in processing multi-sensor data, TimePillars still represents an important advance in this field.
6. Conclusion
This work shows that considering past sensor data is superior to only utilizing current information. Accessing previous driving environment information can cope with the sparse nature of lidar point clouds and lead to more accurate predictions. We demonstrate that recurrent networks are suitable as a means to achieve the latter. Giving the system memory leads to a more robust solution compared to point cloud aggregation methods that create denser data representations through extensive processing. Our proposed method, TimePillars, implements a way to solve the recursive problem. By simply adding three additional convolutional layers to the inference process, we demonstrate that basic network building blocks are sufficient to achieve significant results and ensure that existing efficiency and hardware integration specifications are met. To the best of our knowledge, this work provides the first benchmark results for the 3D object detection task on the newly introduced Zenseact open dataset. We hope our work can contribute to safer, more sustainable roads in the future.

Original link: https://mp.weixin.qq.com/s/94JQcvGXFWfjlDCT77gjlA
The above is the detailed content of Efficiently improve detection capabilities: break through the detection of small targets above 200 meters. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- An article about autonomous driving decision-making systems
- Autonomous driving technology and intelligent transportation system practice implemented in Java
- Multi-target tracking problem in target detection technology
- Spread everything? 3DifFusionDet: Diffusion model enters LV fusion 3D target detection!
- Tesla once again innovates autonomous driving technology: introducing 3D scene display to improve parking assistance functions