


A new interpretation of the declining intelligence level of GPT-4

GPT-4, regarded as one of the most powerful language models in the world since its release, has unfortunately experienced a series of crises of trust.
If we connect the "intermittent intelligence" incident earlier this year with OpenAI's redesign of the GPT-4 architecture, then there are recent reports that GPT-4 has become "lazy" "The rumors are even more interesting. Someone tested and found that as long as you tell GPT-4 "it is winter vacation", it will become lazy, as if it has entered a hibernation state.
To solve the problem of poor zero-sample performance of the model on new tasks, we can take the following methods: 1. Data enhancement: Increase the generalization ability of the model by expanding and transforming existing data. For example, image data can be altered by rotation, scaling, translation, etc., or by synthesizing new data samples. 2. Transfer learning: Use models that have been trained on other tasks to transfer their parameters and knowledge to new tasks. This can leverage existing knowledge and experience to improve
Recently, researchers from the University of California, Santa Cruz published a new discovery in a paper that may It can explain the underlying reasons for the performance degradation of GPT-4.

“We found that LLM performed surprisingly better on datasets released before the training data creation date. Datasets released later."
They perform well on "seen" tasks and perform poorly on new tasks. This means that LLM is just a method of imitating intelligence based on approximate retrieval, mainly memorizing things without any level of understanding.
To put it bluntly, LLM’s generalization ability is “not as strong as stated” - the foundation is not solid, and there will always be mistakes in actual combat.
One of the major reasons for this result is "task pollution", which is one form of data pollution. The data pollution we are familiar with before is test data pollution, which is the inclusion of test data examples and labels in the pre-training data. "Task contamination" is the addition of task training examples to pre-training data, making the evaluation in zero-sample or few-sample methods no longer realistic and effective.
The researcher conducted a systematic analysis of the data pollution problem for the first time in the paper:

Paper link: https://arxiv.org/pdf/2312.16337.pdf
After reading the paper, someone said "pessimistically":
This is the fate of all machine learning (ML) models that do not have the ability to continuously learn, that is, ML models The weights are frozen after training, but the input distribution continues to change, and if the model cannot continue to adapt to this change, it will slowly degrade.
This means that as programming languages are constantly updated, LLM-based coding tools will also degrade. This is one of the reasons why you don't have to rely too heavily on such a fragile tool.
The cost of constantly retraining these models is high, and sooner or later someone will give up on these inefficient methods.
No ML model yet can reliably and continuously adapt to changing input distributions without causing severe disruption or performance loss to the previous encoding task.
And this is one of the areas where biological neural networks are good at. Due to the strong generalization ability of biological neural networks, learning different tasks can further improve the performance of the system, because the knowledge gained from one task helps to improve the entire learning process itself, which is called "meta-learning".
How serious is the problem of "task pollution"? Let’s take a look at the content of the paper.
Models and data sets
There are 12 models used in the experiment (as shown in Table 1), 5 of which are proprietary Of the GPT-3 series models, 7 are open models with free access to weights.

Datasets are divided into two categories: published before or after January 1, 2021 Data set, researchers use this partitioning method to analyze the zero-sample or few-sample performance difference between the old data set and the new data set, and use the same partitioning method for all LLMs. Table 1 lists the creation time of each model training data, and Table 2 lists the publication date of each dataset.
The consideration behind the above approach is that zero-shot and few-shot evaluations involve the model making predictions about tasks that it has never seen or only seen a few times during training. The key premise is that the model has no prior exposure to the specific task to be completed. , thereby ensuring a fair assessment of their learning abilities. However, tainted models can give the illusion of competence that they have not been exposed to or have only been exposed to a few times because they have been trained on task examples during pre-training. In a chronological data set, it will be relatively easier to detect such inconsistencies, as any overlaps or anomalies will be obvious.
Measurement methods
The researchers used four methods to measure "task pollution":
- Training data inspection: Search the training data for task training examples.
- Task example extraction: Extract task examples from existing models. Only instruction-tuned models can be extracted. This analysis can also be used for training data or test data extraction. Note that in order to detect task contamination, the extracted task examples do not have to exactly match existing training data examples. Any example that demonstrates a task demonstrates the possible contamination of zero-shot learning and few-shot learning.
- Member Reasoning: This method only applies to build tasks. Checks that the model-generated content for the input instance is exactly the same as the original dataset. If it matches exactly, we can infer that it is a member of the LLM training data. This differs from task example extraction in that the generated output is checked for an exact match. Exact matches on the open-ended generation task strongly suggest that the model saw these examples during training, unless the model is "psychic" and knows the exact wording used in the data. (Note, this can only be used for build tasks.)
- Time series analysis: For a model set where training data was collected during a known time frame, measure its performance on a dataset with a known release date, and use Temporal evidence checks for contamination evidence.
The first three methods have high precision, but low recall rate. If you can find the data in the task's training data, you can be sure that the model has seen the example. However, due to changes in data formats, changes in keywords used to define tasks, and the size of data sets, finding no evidence of contamination using the first three methods does not prove the absence of contamination.
The fourth method, the recall rate of chronological analysis is high, but the precision is low. If performance is high due to task contamination, then chronological analysis has a good chance of spotting it. But other factors may also cause performance to improve over time and therefore be less accurate.
Therefore, the researchers used all four methods to detect task contamination and found strong evidence of task contamination in certain model and dataset combinations.
They first performed timing analysis on all tested models and datasets as it was most likely to find possible contamination; then used training data inspection and task example extraction to find task contamination Further evidence; we next observe the performance of LLM on a pollution-free task, and finally conduct additional analysis using membership inference attacks.
The key conclusions are as follows:
1. The researcher created a data set for each model before its training data was crawled on the Internet. and then analyzed the data set created. It was found that the odds of performing above most baselines were significantly higher for datasets created before collecting LLM training data (Figure 1).

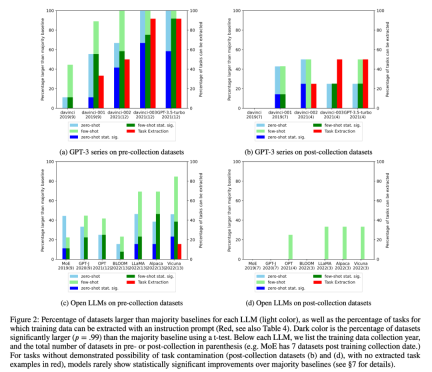
#2. The researcher conducted training data inspection and task example extraction to find possible task contamination. It was found that for classification tasks where task contamination is unlikely, models rarely achieve statistically significant improvements over simple majority baselines across a range of tasks, whether zero- or few-shot (Figure 2).
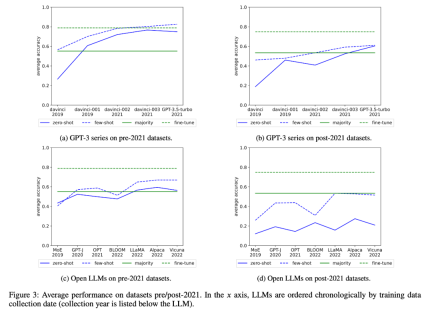
The researchers also examined the changes in the average performance of the GPT-3 series and open LLM over time, as shown in Figure 3 :
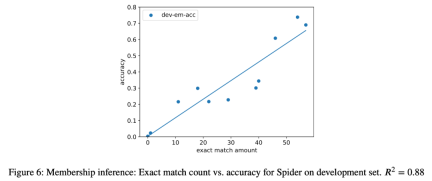
3. As a case study, the researcher also tried to perform semantic parsing tasks on all models in the analysis. Inference attack, found a strong correlation (R=.88) between the number of extracted instances and the accuracy of the model in the final task (Figure 6). This strongly proves that the improvement in zero-shot performance in this task is due to task contamination.
4. The researchers also carefully studied the GPT-3 series models and found that training examples can be extracted from the GPT-3 model, and in each version from davinci to GPT-3.5-turbo, the training examples that can be extracted The number is increasing, which is closely related to the improvement of the zero-sample performance of the GPT-3 model on this task (Figure 2). This strongly proves that the performance improvement of GPT-3 models from davinci to GPT-3.5-turbo on these tasks is due to task contamination.
The above is the detailed content of A new interpretation of the declining intelligence level of GPT-4. For more information, please follow other related articles on the PHP Chinese website!

 Microsoft Work Trend Index 2025 Shows Workplace Capacity StrainApr 24, 2025 am 11:19 AM
Microsoft Work Trend Index 2025 Shows Workplace Capacity StrainApr 24, 2025 am 11:19 AMThe burgeoning capacity crisis in the workplace, exacerbated by the rapid integration of AI, demands a strategic shift beyond incremental adjustments. This is underscored by the WTI's findings: 68% of employees struggle with workload, leading to bur
 Can AI Understand? The Chinese Room Argument Says No, But Is It Right?Apr 24, 2025 am 11:18 AM
Can AI Understand? The Chinese Room Argument Says No, But Is It Right?Apr 24, 2025 am 11:18 AMJohn Searle's Chinese Room Argument: A Challenge to AI Understanding Searle's thought experiment directly questions whether artificial intelligence can genuinely comprehend language or possess true consciousness. Imagine a person, ignorant of Chines
 China's 'Smart' AI Assistants Echo Microsoft Recall's Privacy FlawsApr 24, 2025 am 11:17 AM
China's 'Smart' AI Assistants Echo Microsoft Recall's Privacy FlawsApr 24, 2025 am 11:17 AMChina's tech giants are charting a different course in AI development compared to their Western counterparts. Instead of focusing solely on technical benchmarks and API integrations, they're prioritizing "screen-aware" AI assistants – AI t
 Docker Brings Familiar Container Workflow To AI Models And MCP ToolsApr 24, 2025 am 11:16 AM
Docker Brings Familiar Container Workflow To AI Models And MCP ToolsApr 24, 2025 am 11:16 AMMCP: Empower AI systems to access external tools Model Context Protocol (MCP) enables AI applications to interact with external tools and data sources through standardized interfaces. Developed by Anthropic and supported by major AI providers, MCP allows language models and agents to discover available tools and call them with appropriate parameters. However, there are some challenges in implementing MCP servers, including environmental conflicts, security vulnerabilities, and inconsistent cross-platform behavior. Forbes article "Anthropic's model context protocol is a big step in the development of AI agents" Author: Janakiram MSVDocker solves these problems through containerization. Doc built on Docker Hub infrastructure
 Using 6 AI Street-Smart Strategies To Build A Billion-Dollar StartupApr 24, 2025 am 11:15 AM
Using 6 AI Street-Smart Strategies To Build A Billion-Dollar StartupApr 24, 2025 am 11:15 AMSix strategies employed by visionary entrepreneurs who leveraged cutting-edge technology and shrewd business acumen to create highly profitable, scalable companies while maintaining control. This guide is for aspiring entrepreneurs aiming to build a
 Google Photos Update Unlocks Stunning Ultra HDR For All Your PicturesApr 24, 2025 am 11:14 AM
Google Photos Update Unlocks Stunning Ultra HDR For All Your PicturesApr 24, 2025 am 11:14 AMGoogle Photos' New Ultra HDR Tool: A Game Changer for Image Enhancement Google Photos has introduced a powerful Ultra HDR conversion tool, transforming standard photos into vibrant, high-dynamic-range images. This enhancement benefits photographers a
 Descope Builds Authentication Framework For AI Agent IntegrationApr 24, 2025 am 11:13 AM
Descope Builds Authentication Framework For AI Agent IntegrationApr 24, 2025 am 11:13 AMTechnical Architecture Solves Emerging Authentication Challenges The Agentic Identity Hub tackles a problem many organizations only discover after beginning AI agent implementation that traditional authentication methods aren’t designed for machine-
 Google Cloud Next 2025 And The Connected Future Of Modern WorkApr 24, 2025 am 11:12 AM
Google Cloud Next 2025 And The Connected Future Of Modern WorkApr 24, 2025 am 11:12 AM(Note: Google is an advisory client of my firm, Moor Insights & Strategy.) AI: From Experiment to Enterprise Foundation Google Cloud Next 2025 showcased AI's evolution from experimental feature to a core component of enterprise technology, stream


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Linux new version
SublimeText3 Linux latest version

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

