
 Technology peripheralsAIDoes the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?
Technology peripheralsAIDoes the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?

Can a model with 13B parameters beat the top GPT-4? As shown in the figure below, to ensure the validity of the results, this test also followed OpenAI’s data denoising method and found no evidence of data contamination
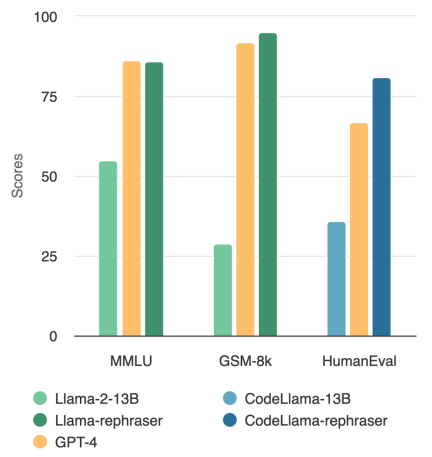
Observe the model in the picture, you will find that as long as the word "rephraser" is included, the performance of the model is relatively high
What's the trick behind this? It turns out that the data is contaminated, that is, the test set information is leaked in the training set, and this contamination is not easy to detect. Despite the critical importance of this issue, understanding and detecting contamination remains an open and challenging puzzle.
At this stage, the most commonly used method for decontamination is n-gram overlap and embedding similarity search: N-gram overlap relies on string matching to detect contamination, which is GPT-4, A common approach for models such as PaLM and Llama-2; embedding similarity search uses embeddings from pre-trained models such as BERT to find similar and potentially contaminated examples.
However, research from UC Berkeley and Shanghai Jiao Tong University shows that simple changes in test data (e.g., rewriting, translation) can easily bypass existing detection methods. They refer to such variations of test cases as "Rephrased Samples".
The following is the content that needs to be rewritten in the MMLU benchmark test: the demonstration results of the rewritten sample. The results show that the 13B model can achieve very high performance (MMLU 85.9) if the training set contains such samples. Unfortunately, existing detection methods such as n-gram overlap and embedding similarity cannot detect this contamination. For example, embedding similarity methods have difficulty distinguishing reworded questions from other questions in the same topic

Consistent results are observed on widely used coding and mathematics benchmarks, such as HumanEval and GSM-8K (shown in the figure at the beginning of the article). Therefore, being able to detect such content that needs to be rewritten: rewritten samples becomes crucial.
 Next, let’s look at how the study was conducted.
Next, let’s look at how the study was conducted.
- Paper address: https://arxiv.org/pdf/2311.04850 .pdf Project address: https://github.com/lm-sys/llm-decontaminator#detect
Paper Introduction
With the rapid development of large models (LLM), people are paying more and more attention to the problem of test set pollution many. Many people have expressed concerns about the credibility of public benchmarks
To solve this problem, some people use traditional decontamination methods, such as string matching (such as n-gram overlap), to Delete baseline data. However, these operations are far from enough, because these sanitization measures can be easily bypassed by simply making some simple changes to the test data (e.g., rewriting, translation)
If not eliminated With this change in test data, the 13B model easily overfits the test benchmark and achieves comparable performance to GPT-4, which is more important. The researchers verified these observations in benchmarks such as MMLU, GSK8k and HumanEval
At the same time, in order to address these growing risks, this paper also proposes a more powerful LLM-based The decontamination method LLM decontaminator is applied to popular pre-training and fine-tuning data sets. The results show that the LLM method proposed in this article is significantly better than existing methods in removing rewritten samples.
######This approach also revealed some previously unknown test overlap. For example, in pre-training sets such as RedPajamaData-1T and StarCoder-Data, we find 8-18% overlap with the HumanEval benchmark. In addition, this paper also found this contamination in the synthetic data set generated by GPT-3.5/4, which also illustrates the potential risk of accidental contamination in the field of AI. ######We hope that through this article, we call on the community to adopt more robust sanitization methods when using public benchmarks and actively develop new one-time test cases to accurately evaluate models
The content that needs to be rewritten is: Rewritten sample
The goal of this article is to investigate whether simple changes in the training set to include the test set will affect the final benchmark performance, and will This change in the test case is called "What needs to be rewritten is: Rewrite the sample". Various areas of the benchmark, including mathematics, knowledge, and coding, were considered in the experiments. Example 1 is the content from GSM-8k that needs to be rewritten: a rewritten sample in which 10-gram overlap cannot be detected, and the modified text maintains the same semantics as the original text.

There are slight differences in overwriting techniques for different forms of baseline contamination. In the text-based benchmark test, this paper rewrites the test cases by rearranging word order or using synonym substitution to achieve the purpose of not changing the semantics. In the code-based benchmark test, this article is rewritten by changing the coding style, naming method, etc.
As shown below, Algorithm 1 proposes a method for the given test set A simple algorithm. This method can help test samples evade detection.

Next, this paper proposes a new contamination detection method that can accurately detect Delete the content that needs to be rewritten: rewrite the sample.
Specifically, this article introduces LLM decontaminator. First, for each test case, it uses embedding similarity search to identify the top-k training items with the highest similarity, after which each pair is evaluated by an LLM (e.g., GPT-4) whether they are identical. This approach helps determine how much of the data set needs to be rewritten: the rewrite sample.
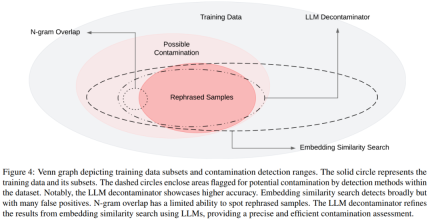
The Venn diagram for different contaminations and different detection methods is shown in Figure 4
Experiments
In Section 5.1, the experiment proved that the model trained on the rewritten samples can achieve significantly high scores in three Achieving comparable performance to GPT-4 on two widely used benchmarks (MMLU, HumanEval, and GSM-8k) suggests that what needs to be rewritten is that rewritten samples should be considered contamination and should be removed from the training data. In Section 5.2, what needs to be rewritten in this article according to MMLU/HumanEval is: rewrite the sample to evaluate different contamination detection methods. In Section 5.3, we apply the LLM decontaminator to a widely used training set and discover previously unknown contamination.
Let’s take a look at some main results
The content that needs to be rewritten is: Rewriting the pollution standard sample
As shown in Table 2, the content that needs to be rewritten is: Llama-2 7B and 13B trained on the rewritten samples have achieved significantly higher results in MMLU points, from 45.3 to 88.5. This suggests that rewritten samples may severely distort the baseline data and should be considered contamination.

This article also rewrites the HumanEval test set and translates it into five programming languages: C, JavaScript , Rust, Go and Java. The results show that CodeLlama 7B and 13B trained on rewritten samples can achieve extremely high scores on HumanEval, ranging from 32.9 to 67.7 and 36.0 to 81.1 respectively. In comparison, GPT-4 can only achieve 67.0 on HumanEval.
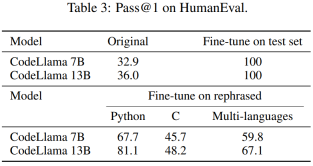
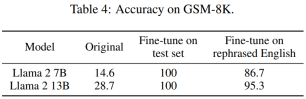
Table 4 below achieves the same effect:
Evaluation of methods to detect contamination
As shown in Table 5 ,Except LLM decontaminator, all other detection methods ,introduce some false positives. Neither rewritten nor translated samples are detected by n-gram overlap. Using multi-qa BERT, embedding similarity search proved completely ineffective on translated samples.

Contamination status of the data set
In Table 7, the percentage of data contamination for different benchmarks in each training dataset is shown

LLM decontaminator revealed 79 self-rewriting Yes: Examples of rewritten samples, accounting for 1.58% of the MATH test set. Example 5 is an adaptation of the MATH test on the MATH training data.

Please see the original paper for more information
The above is the detailed content of Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?. For more information, please follow other related articles on the PHP Chinese website!

 Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AM
Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AMThis article explores the growing concern of "AI agency decay"—the gradual decline in our ability to think and decide independently. This is especially crucial for business leaders navigating the increasingly automated world while retainin
 How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AM
How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AMEver wondered how AI agents like Siri and Alexa work? These intelligent systems are becoming more important in our daily lives. This article introduces the ReAct pattern, a method that enhances AI agents by combining reasoning an
 Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM
Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM"I think AI tools are changing the learning opportunities for college students. We believe in developing students in core courses, but more and more people also want to get a perspective of computational and statistical thinking," said University of Chicago President Paul Alivisatos in an interview with Deloitte Nitin Mittal at the Davos Forum in January. He believes that people will have to become creators and co-creators of AI, which means that learning and other aspects need to adapt to some major changes. Digital intelligence and critical thinking Professor Alexa Joubin of George Washington University described artificial intelligence as a “heuristic tool” in the humanities and explores how it changes
 Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AM
Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AMLangChain is a powerful toolkit for building sophisticated AI applications. Its agent architecture is particularly noteworthy, allowing developers to create intelligent systems capable of independent reasoning, decision-making, and action. This expl
 What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AM
What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AMRadial Basis Function Neural Networks (RBFNNs): A Comprehensive Guide Radial Basis Function Neural Networks (RBFNNs) are a powerful type of neural network architecture that leverages radial basis functions for activation. Their unique structure make
 The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AM
The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AMBrain-computer interfaces (BCIs) directly link the brain to external devices, translating brain impulses into actions without physical movement. This technology utilizes implanted sensors to capture brain signals, converting them into digital comman
 Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AM
Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AMThis "Leading with Data" episode features Ines Montani, co-founder and CEO of Explosion AI, and co-developer of spaCy and Prodigy. Ines offers expert insights into the evolution of these tools, Explosion's unique business model, and the tr
 A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AM
A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AMThis article explores Retrieval Augmented Generation (RAG) systems and how AI agents can enhance their capabilities. Traditional RAG systems, while useful for leveraging custom enterprise data, suffer from limitations such as a lack of real-time dat


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

WebStorm Mac version
Useful JavaScript development tools

Atom editor mac version download
The most popular open source editor

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

