

 Technology peripheralsAIMotionLM: Language modeling technology for multi-agent motion prediction
Technology peripheralsAIMotionLM: Language modeling technology for multi-agent motion predictionMotionLM: Language modeling technology for multi-agent motion prediction

This article is reprinted with the authorization of the Autonomous Driving Heart public account. Please contact the source for reprinting.
Original title: MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Paper link: https://arxiv.org/pdf/2309.16534.pdf
Author affiliation: Waymo
Conference: ICCV 2023

Paper idea:
For autonomous vehicle safety planning, Reliably predicting future behavior of road agents is critical. This study represents continuous trajectories as sequences of discrete motion tokens and treats multi-agent motion prediction as a language modeling task. Our proposed model, MotionLM, has several advantages: First, it does not require the use of anchor points or explicit latent variables to optimally learn multi-modal distributions. Instead, we exploit the standard language modeling objective of maximizing the average log probability of sequence tokens. Second, our approach avoids post hoc interaction heuristics, where individual agent trajectory generation occurs after interaction scoring. In contrast, MotionLM generates a joint distribution of interactive agent futures in a single autoregressive decoding process. In addition, the sequential decomposition of the model enables temporal causal condition inference. Our proposed method achieves new state-of-the-art performance on the Waymo Open Motion Dataset, ranking first on the interactive challenge leaderboard
Main Contributions:
Here In this article, we discuss multi-agent motion prediction as a language modeling task. We introduce a temporal causal decoder to decode discrete motion tokens trained with a causal language modeling loss
This paper will combine sampling in the model with a simple rollout aggregation scheme to improve the weighted pattern of the joint trajectory Recognition ability. Through experiments in the Waymo Open Motion Dataset interaction prediction challenge, we have demonstrated that this new method improves the ranking joint mAP metric by 6% and reaches the state-of-the-art performance level
This article's approach to this article Extensive ablation experiments are performed and its temporal causal conditional predictions are analyzed, which are largely unsupported by current joint prediction models.
Network Design:
The goal of this paper is to model the distribution on multi-agent interactions in a general way that can be applied to different Downstream tasks, including minimal, joint, and conditional predictions. To achieve this goal, an expressive generative framework is needed that can capture the multiple morphologies in driving scenes. Furthermore, we consider saving time dependencies here; that is, in our model, the inference follows a directed acyclic graph, with each node’s parent node being earlier in time and its child node being later in time, which makes Conditional prediction is closer to causal intervention because it eliminates certain spurious correlations that would otherwise lead to disobedience to temporal causality. This paper observes that joint models that do not preserve temporal dependencies may have limited ability to predict actual agent responses, a key use in planning. To this end, this paper utilizes an autoregressive decomposition of the future decoder, where the agent’s motion tokens conditionally depend on all previously sampled tokens and the trajectories are sequentially derived

figure 1. Our model autoregressively generates sequences of discrete motion tokens for a set of agents to produce consistent interactive trajectory predictions.

Please look at Figure 2, which is the architecture of MotionLM
This article first encodes the heterogeneous scene features (left) related to each modeling agent for scene embeddings of shape R,N,·,H. Among them, R is the number of rollouts, N is the number of jointly modeled agents, and H is the dimensionality of each embedding. During the inference process, in order to parallelize sampling, this paper repeats the embedding R times in the batch dimension. Next, a trajectory decoder rolls out T discrete motion tokens for multiple agents in a temporally causal manner (center). Finally, the typical pattern of rollouts can be recovered by simple aggregation of k-means clusters using non-maximum suppression initialization (right panel).

image 3. The first two prediction joint rollout modes for three WOMD scenarios are shown.
The color gradient represents the time change from t = 0 seconds to t = 8 seconds. The joint mode transitions from green to blue, and the sub-joint mode transitions from orange to purple with the highest probability. We observed three types of interactions: agents in adjacent lanes will give way to the lane-changing agent according to the lane-changing time (left), pedestrians will walk behind passing vehicles according to the vehicle's progress (center), and turning vehicles will either Will give way to a passing cyclist (most likely mode) or will turn before a cyclist approaches (minor mode) (right side)

Please see Figure 4. This figure shows the causal Bayesian network representation of joint induction (left), post-intervention causal Bayesian network (middle), and causal conditioning (right)
Solid lines represent causality in time Correlation, while the dashed lines represent causal information flow. A model without time-dependent constraints will support causal conditioning but not temporal causal conditioning, which can be problematic when trying to predict agent responses.
Experimental results:







# Quote:
Seff, A., Cera, B., Chen, D., Ng, M., Zhou, A., Nayakanti, N., Refaat, K. S., & Sapp, B. (2023). MotionLM: Multi-Agent Motion Forecasting as Language Modeling.ArXiv. /abs/2309.16534

The above is the detailed content of MotionLM: Language modeling technology for multi-agent motion prediction. For more information, please follow other related articles on the PHP Chinese website!

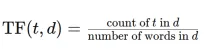 Convert Text Documents to a TF-IDF Matrix with tfidfvectorizerApr 18, 2025 am 10:26 AM
Convert Text Documents to a TF-IDF Matrix with tfidfvectorizerApr 18, 2025 am 10:26 AMThis article explains the Term Frequency-Inverse Document Frequency (TF-IDF) technique, a crucial tool in Natural Language Processing (NLP) for analyzing textual data. TF-IDF surpasses the limitations of basic bag-of-words approaches by weighting te
 Building Smart AI Agents with LangChain: A Practical GuideApr 18, 2025 am 10:18 AM
Building Smart AI Agents with LangChain: A Practical GuideApr 18, 2025 am 10:18 AMUnleash the Power of AI Agents with LangChain: A Beginner's Guide Imagine showing your grandmother the wonders of artificial intelligence by letting her chat with ChatGPT – the excitement on her face as the AI effortlessly engages in conversation! Th
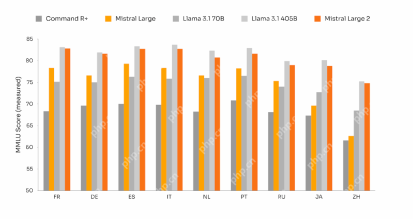 Mistral Large 2: Powerful Enough to Challenge Llama 3.1 405B?Apr 18, 2025 am 10:16 AM
Mistral Large 2: Powerful Enough to Challenge Llama 3.1 405B?Apr 18, 2025 am 10:16 AMMistral Large 2: A Deep Dive into Mistral AI's Powerful Open-Source LLM Meta AI's recent release of the Llama 3.1 family of models was quickly followed by Mistral AI's unveiling of its largest model to date: Mistral Large 2. This 123-billion paramet
 What is Noise Schedules in Stable Diffusion? - Analytics VidhyaApr 18, 2025 am 10:15 AM
What is Noise Schedules in Stable Diffusion? - Analytics VidhyaApr 18, 2025 am 10:15 AMUnderstanding Noise Schedules in Diffusion Models: A Comprehensive Guide Have you ever been captivated by the stunning visuals of digital art generated by AI and wondered about the underlying mechanics? A key element is the "noise schedule,&quo
 How to Build a Conversational Chatbot with GPT-4o? - Analytics VidhyaApr 18, 2025 am 10:06 AM
How to Build a Conversational Chatbot with GPT-4o? - Analytics VidhyaApr 18, 2025 am 10:06 AMBuilding a Contextual Chatbot with GPT-4o: A Comprehensive Guide In the rapidly evolving landscape of AI and NLP, chatbots have become indispensable tools for developers and organizations. A key aspect of creating truly engaging and intelligent chat
 Top 7 Frameworks for Building AI Agents in 2025Apr 18, 2025 am 10:00 AM
Top 7 Frameworks for Building AI Agents in 2025Apr 18, 2025 am 10:00 AMThis article explores seven leading frameworks for building AI agents – autonomous software entities that perceive, decide, and act to achieve goals. These agents, surpassing traditional reinforcement learning, leverage advanced planning and reasoni
 What's the Difference Between Type I and Type II Errors ? - Analytics VidhyaApr 18, 2025 am 09:48 AM
What's the Difference Between Type I and Type II Errors ? - Analytics VidhyaApr 18, 2025 am 09:48 AMUnderstanding Type I and Type II Errors in Statistical Hypothesis Testing Imagine a clinical trial testing a new blood pressure medication. The trial concludes the drug significantly lowers blood pressure, but in reality, it doesn't. This is a Type
 Automated Text Summarization with Sumy LibraryApr 18, 2025 am 09:37 AM
Automated Text Summarization with Sumy LibraryApr 18, 2025 am 09:37 AMSumy: Your AI-Powered Summarization Assistant Tired of sifting through endless documents? Sumy, a powerful Python library, offers a streamlined solution for automatic text summarization. This article explores Sumy's capabilities, guiding you throug


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 English version
Recommended: Win version, supports code prompts!

SublimeText3 Chinese version
Chinese version, very easy to use

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

