

Feature learning problem in unsupervised learning


Feature learning problems in unsupervised learning require specific code examples
In machine learning, feature learning is an important task. In unsupervised learning, the goal of feature learning is to discover useful features from unlabeled data so that these features can be extracted and utilized in subsequent tasks. This article will introduce the feature learning problem in unsupervised learning and provide some concrete code examples.
1. The significance of feature learning
Feature learning has important significance in machine learning. Usually, the dimensionality of the data is very high and it also contains a lot of redundant information. The goal of feature learning is to mine the most useful features from the original data so that the data can be better processed in subsequent tasks. Through feature learning, the following aspects of optimization can be achieved:
- Data visualization: By reducing the dimensionality of the data, high-dimensional data can be mapped into a two-dimensional or three-dimensional space for visualization. Such visualizations can help us better understand the distribution and structure of the data.
- Data compression: Through feature learning, the original data can be converted into a low-dimensional representation, thereby achieving data compression. This reduces storage and computation overhead while also allowing for more efficient processing of large data sets.
- Data preprocessing: Feature learning can help us discover and remove redundant information in the data, thereby improving the performance of subsequent tasks. By representing data as meaningful features, the interference of noise can be reduced and the generalization ability of the model can be improved.
2. Feature learning methods
In unsupervised learning, there are many methods that can be used for feature learning. Several common methods are introduced below and corresponding code examples are given.
- Principal Component Analysis (PCA):
PCA is a classic unsupervised feature learning method. It maps the original data into a low-dimensional space through linear transformation while maximizing the variance of the data. The following code shows how to use Python's scikit-learn library for PCA feature learning:
from sklearn.decomposition import PCA # 假设X是原始数据矩阵 pca = PCA(n_components=2) # 设置降维后的维度为2 X_pca = pca.fit_transform(X) # 进行PCA变换
- Autoencoder (Autoencoder):
The autoencoder is a neural network model, Can be used for nonlinear feature learning. It maps the original data to a low-dimensional space and regenerates the original data through the combination of encoder and decoder. The following code shows how to build a simple autoencoder model using the Keras library:
from keras.layers import Input, Dense from keras.models import Model # 假设X是原始数据矩阵 input_dim = X.shape[1] # 输入维度 encoding_dim = 2 # 编码后的维度 # 编码器 input_layer = Input(shape=(input_dim,)) encoded = Dense(encoding_dim, activation='relu')(input_layer) # 解码器 decoded = Dense(input_dim, activation='sigmoid')(encoded) # 自编码器 autoencoder = Model(input_layer, decoded) autoencoder.compile(optimizer='adam', loss='binary_crossentropy') # 训练自编码器 autoencoder.fit(X, X, epochs=10, batch_size=32) encoded_data = autoencoder.predict(X) # 得到编码后的数据
- Non-negative matrix factorization (NMF):
NMF is a method used for text, images, etc. Feature learning methods for non-negative data. It extracts the basic features of the original data by decomposing the original data into the product of non-negative matrices. The following code shows how to use Python's scikit-learn library for NMF feature learning:
from sklearn.decomposition import NMF # 假设X是非负数据矩阵 nmf = NMF(n_components=2) # 设置降维后的维度为2 X_nmf = nmf.fit_transform(X) # 进行NMF分解
The above code examples only introduce the basic usage of the three feature learning methods, and more complex ones may be needed in actual applications. Model and parameter tuning. Readers can conduct further research and practice as needed.
3. Summary
Feature learning in unsupervised learning is an important task that can help us discover useful features from unlabeled data. This article introduces the meaning of feature learning, as well as several common feature learning methods, and gives corresponding code examples. It is hoped that readers can better understand and apply feature learning technology and improve the performance of machine learning tasks through the introduction of this article.
The above is the detailed content of Feature learning problem in unsupervised learning. For more information, please follow other related articles on the PHP Chinese website!

 Gemini 2.5 Pro vs GPT 4.5: Can Google Beat OpenAI's Best?Apr 24, 2025 am 09:39 AM
Gemini 2.5 Pro vs GPT 4.5: Can Google Beat OpenAI's Best?Apr 24, 2025 am 09:39 AMThe AI race is heating up with newer, competing models launched every other day. Amid this rapid innovation, Google Gemini 2.5 Pro challenges OpenAI GPT-4.5, both offering cutting-edge advancements in AI capabilities. In this Gem
 Karun Thanks's bluepring for data science successApr 24, 2025 am 09:38 AM
Karun Thanks's bluepring for data science successApr 24, 2025 am 09:38 AMKarun Thankachan: A Data Science Journey from Software Engineer to Walmart Senior Data Scientist Karun Thankachan, a senior data scientist specializing in recommender systems and information retrieval, shares his career path, insights on scaling syst
 We Tried Gemini 2.5 Pro Experimental and It's Mind-Blowing!Apr 24, 2025 am 09:36 AM
We Tried Gemini 2.5 Pro Experimental and It's Mind-Blowing!Apr 24, 2025 am 09:36 AMGoogle DeepMind's Gemini 2.5 Pro (experimental): A Powerful New AI Model Google DeepMind has released Gemini 2.5 Pro (experimental), a groundbreaking AI model that has quickly ascended to the top of the LMArena Leaderboard. Building on its predecess
 Top 5 Code Editors to Vibe Code in 2025Apr 24, 2025 am 09:31 AM
Top 5 Code Editors to Vibe Code in 2025Apr 24, 2025 am 09:31 AMRevolutionizing Software Development: A Deep Dive into AI Code Editors Tired of endless coding, constant tab-switching, and frustrating troubleshooting? The future of coding is here, and it's powered by AI. AI code editors understand your project f
 5 Jobs AI Can't Replace According to Bill GatesApr 24, 2025 am 09:26 AM
5 Jobs AI Can't Replace According to Bill GatesApr 24, 2025 am 09:26 AMBill Gates recently visited Jimmy Fallon's Tonight Show, talking about his new book "Source Code", his childhood and Microsoft's 50-year journey. But the most striking thing in the conversation is about the future, especially the rise of artificial intelligence and its impact on our work. Gates shared his thoughts in a hopeful yet honest way. He believes that AI will revolutionize the world at an unexpected rate and talks about work that AI cannot replace in the near future. Let's take a look at these tasks together. Table of contents A new era of abundant intelligence Solve global shortages in healthcare and education Will artificial intelligence replace jobs? Gates said: For some jobs, it will Work that artificial intelligence (currently) cannot replace: human touch remains important Conclusion
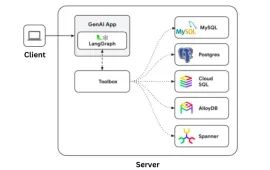 Google Gen AI Toolbox: A Python Library for SQL DatabasesApr 24, 2025 am 09:23 AM
Google Gen AI Toolbox: A Python Library for SQL DatabasesApr 24, 2025 am 09:23 AMGoogle's Gen AI Toolbox for Databases: Revolutionizing Database Interaction with Natural Language Google has unveiled the Gen AI Toolbox for Databases, a revolutionary open-source Python library designed to simplify database interactions using natura
 OpenAI's GPT 4o Image Generation is SUPER COOLApr 24, 2025 am 09:21 AM
OpenAI's GPT 4o Image Generation is SUPER COOLApr 24, 2025 am 09:21 AMOpenAI's ChatGPT Now Boasts Native Image Generation: A Game Changer ChatGPT's latest update has sent ripples through the tech world with the introduction of native image generation, powered by GPT-4o. Sam Altman himself hailed it as "one of the
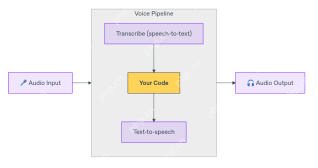 How to Build Multilingual Voice Agent Using OpenAI Agent SDK? - Analytics VidhyaApr 24, 2025 am 09:16 AM
How to Build Multilingual Voice Agent Using OpenAI Agent SDK? - Analytics VidhyaApr 24, 2025 am 09:16 AMOpenAI's Agent SDK now offers a Voice Agent feature, revolutionizing the creation of intelligent, real-time, speech-driven applications. This allows developers to build interactive experiences like language tutors, virtual assistants, and support bo


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

