

Convergence issues in adversarial training


Adversarial Training is a training method that has attracted widespread attention in the field of deep learning in recent years. It aims to enhance the robustness of the model so that it can resist various attack methods. However, in practical applications, adversarial training faces an important problem, namely the convergence problem. In this article, we will discuss the convergence problem and give a concrete code example to solve this problem.
First, let’s understand what the convergence problem is. In adversarial training, we train the model by adding adversarial examples to the training set. Adversarial examples are artificially modified examples that have a strong similarity between humans and models but are able to fool the model's classifier. This makes the model more robust in the face of adversarial examples.
However, due to the introduction of adversarial examples, the training process becomes more difficult. It is difficult for traditional optimization methods to find a converged solution, resulting in the model being unable to obtain good generalization capabilities. This is the convergence problem. Specifically, the convergence problem is manifested in the failure of the model's loss function to decrease steadily during the training process, or the model's performance on the test set cannot be significantly improved.
In order to solve this problem, researchers have proposed many methods. Among them, a common method is to improve the convergence of the model by adjusting parameters during the training process. For example, you can adjust the learning rate, regularization terms, training set size, etc. In addition, there are some methods specifically designed for adversarial training, such as the PGD (Projected Gradient Descent) algorithm proposed by Madry et al.
Below, we will give a specific code example to show how to use the PGD algorithm to solve the convergence problem. First, we need to define an adversarial training model. This model can be any deep learning model, such as convolutional neural network (CNN), recurrent neural network (RNN), etc.
Next, we need to define an adversarial example generator. The PGD algorithm is an iterative attack method that generates adversarial samples through multiple iterations. In each iteration, we update the adversarial examples by computing the gradient of the current model. Specifically, we use gradient ascent to update adversarial examples to make them more deceptive to the model.
Finally, we need to conduct the adversarial training process. In each iteration, we first generate adversarial examples and then use adversarial examples and real samples for training. In this way, the model can gradually improve its robustness in constant confrontation.
The following is a simple code example that shows how to use the PGD algorithm for adversarial training:
import torch
import torch.nn as nn
import torch.optim as optim
class AdversarialTraining:
def __init__(self, model, eps=0.01, alpha=0.01, iterations=10):
self.model = model
self.eps = eps
self.alpha = alpha
self.iterations = iterations
def generate_adversarial_sample(self, x, y):
x_adv = x.clone().detach().requires_grad_(True)
for _ in range(self.iterations):
loss = nn.CrossEntropyLoss()(self.model(x_adv), y)
loss.backward()
x_adv.data += self.alpha * torch.sign(x_adv.grad.data)
x_adv.grad.data.zero_()
x_adv.data = torch.max(torch.min(x_adv.data, x + self.eps), x - self.eps)
x_adv.data = torch.clamp(x_adv.data, 0.0, 1.0)
return x_adv
def train(self, train_loader, optimizer, criterion):
for x, y in train_loader:
x_adv = self.generate_adversarial_sample(x, y)
logits = self.model(x_adv)
loss = criterion(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 定义模型和优化器
model = YourModel()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
criterion = nn.CrossEntropyLoss()
# 创建对抗训练对象
adv_training = AdversarialTraining(model)
# 进行对抗训练
adv_training.train(train_loader, optimizer, criterion)In the above code, model is the model we want to train , eps is the perturbation range when generating adversarial samples, alpha is the step size of each iteration, iterations is the number of iterations. The generate_adversarial_sample method is used to generate adversarial samples, and the train method is used for adversarial training.
Through the above code examples, we can see how to use the PGD algorithm to solve the convergence problem in adversarial training. Of course, this is just one method and may need to be adjusted according to actual conditions for different problems. I hope this article can help you understand and solve convergence problems.
The above is the detailed content of Convergence issues in adversarial training. For more information, please follow other related articles on the PHP Chinese website!

 How to Use Aliases in SQL? - Analytics VidhyaApr 21, 2025 am 10:30 AM
How to Use Aliases in SQL? - Analytics VidhyaApr 21, 2025 am 10:30 AMSQL alias: A tool to improve the readability of SQL queries Do you think there is still room for improvement in the readability of your SQL queries? Then try the SQL alias! Alias This convenient tool allows you to give temporary nicknames to tables and columns, making your queries clearer and easier to process. This article discusses all use cases for aliases clauses, such as renaming columns and tables, and combining multiple columns or subqueries. Overview SQL alias provides temporary nicknames for tables and columns to enhance the readability and manageability of queries. SQL aliases created with AS keywords simplify complex queries by allowing more intuitive table and column references. Examples include renaming columns in the result set, simplifying table names in the join, and combining multiple columns into one
 Code Execution with Google Gemini FlashApr 21, 2025 am 10:14 AM
Code Execution with Google Gemini FlashApr 21, 2025 am 10:14 AMGoogle's Gemini: Code Execution Capabilities of Large Language Models Large Language Models (LLMs), successors to Transformers, have revolutionized Natural Language Processing (NLP) and Natural Language Understanding (NLU). Initially replacing rule-
 Tree of Thoughts Method in AI - Analytics VidhyaApr 21, 2025 am 10:11 AM
Tree of Thoughts Method in AI - Analytics VidhyaApr 21, 2025 am 10:11 AMUnlocking AI's Potential: A Deep Dive into the Tree of Thoughts Technique Imagine navigating a dense forest, each path promising a different outcome, your goal: discovering hidden treasure. This analogy perfectly captures the essence of the Tree of
 How to Implement Normalization with SQL?Apr 21, 2025 am 10:05 AM
How to Implement Normalization with SQL?Apr 21, 2025 am 10:05 AMIntroduction Imagine transforming a cluttered garage into a well-organized, brightly lit space where everything is easily accessible and neatly arranged. In the world of databases, this process is called normalization. Just as a tidy garage improve
 Delimiters in Prompt EngineeringApr 21, 2025 am 10:04 AM
Delimiters in Prompt EngineeringApr 21, 2025 am 10:04 AMPrompt Engineering: Mastering Delimiters for Superior AI Results Imagine crafting a gourmet meal: each ingredient measured precisely, each step timed perfectly. Prompt engineering for AI is similar; delimiters are your essential tools. Just as pre
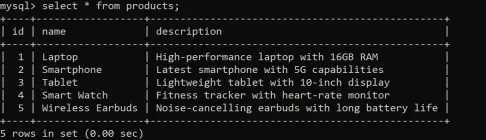 6 Ways to Clean Up Your Database Using SQL REPLACE()Apr 21, 2025 am 09:57 AM
6 Ways to Clean Up Your Database Using SQL REPLACE()Apr 21, 2025 am 09:57 AMSQL REPLACE Functions: Efficient Data Cleaning and Text Operation Guide Have you ever needed to quickly fix large amounts of text in your database? SQL REPLACE functions can help a lot! It allows you to replace all instances of a specific substring with a new substring, making it easy to clean up data. Imagine that your data is scattered with typos—REPLACE can solve this problem immediately. Read on and I'll show you the syntax and some cool examples to get you started. Overview The SQL REPLACE function can efficiently clean up data by replacing specific substrings in text with other substrings. Use REPLACE(string, old
 R-CNN vs R-CNN Fast vs R-CNN Faster vs YOLO - Analytics VidhyaApr 21, 2025 am 09:52 AM
R-CNN vs R-CNN Fast vs R-CNN Faster vs YOLO - Analytics VidhyaApr 21, 2025 am 09:52 AMObject Detection: From R-CNN to YOLO – A Journey Through Computer Vision Imagine a computer not just seeing, but understanding images. This is the essence of object detection, a pivotal area in computer vision revolutionizing machine-world interactio
 What is KL Divergence that Revolutionized Machine Learning? - Analytics VidhyaApr 21, 2025 am 09:49 AM
What is KL Divergence that Revolutionized Machine Learning? - Analytics VidhyaApr 21, 2025 am 09:49 AMKullback-Leibler (KL) Divergence: A Deep Dive into Relative Entropy Few mathematical concepts have as profoundly impacted modern machine learning and artificial intelligence as Kullback-Leibler (KL) divergence. This powerful metric, also known as re


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

