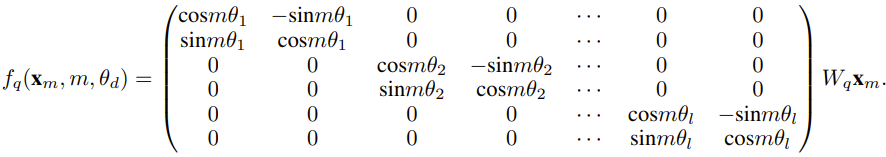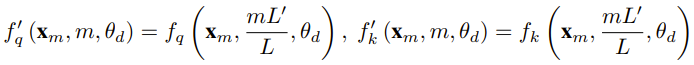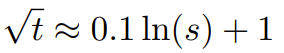Transformer-based large language models (LLM) have demonstrated the powerful ability to perform contextual learning (ICL) and have almost become the only choice for many natural language processing (NLP) tasks. Transformer's self-attention mechanism allows training to be highly parallelized, allowing long sequences to be processed in a distributed manner. The length of the sequence used for LLM training is called its context window.
The Transformer's context window directly determines the amount of space in which examples can be provided, thereby limiting its ICL capabilities. If a model has a limited context window, there is less room to provide the model with robust examples on which to perform ICL. Furthermore, other tasks such as summarization are also severely hampered when the model's context window is particularly short. In terms of the nature of the language itself, the position of the token is crucial for effective modeling, and self-attention will not be directly encoded due to its parallelism location information. The Transformer architecture introduces positional encoding to solve this problem. The original Transformer architecture used an absolute sinusoidal position encoding, which was later improved into a learnable absolute position encoding. Since then, relative position encoding schemes have further improved Transformer performance. Currently, the most popular relative position encodings are T5 Relative Bias, RoPE, XPos and ALiBi. Positional encoding has a recurring limitation: the inability to generalize to the context window seen during training. Although some methods such as ALiBi have the ability to do some limited generalization, no method has yet generalized to sequences significantly longer than its pre-trained length. There have been some research results trying to overcome these limitations. For example, some research proposes to slightly modify RoPE through positional interpolation (PI) and fine-tune on a small amount of data to extend the context length. Two months ago, Bowen Peng of Nous Research shared a solution on Reddit, which is to achieve "NTK-aware interpolation" by incorporating high-frequency losses. NTK here refers to Neural Tangent Kernel. It claims that the NTK-aware extended RoPE can greatly expand the context window of the LLaMA model (more than 8k) without any fine-tuning and the impact on perplexity. Also extremely small. Recently, a related paper by him and three other collaborators was released!
- Paper: https://arxiv.org/abs/2309.00071
- Model: https: //github.com/jquesnelle/yarn
In this paper, they made two improvements to NTK-aware interpolation. Each focuses on different aspects:
- Dynamic NTK interpolation method can be used for pre-trained models without fine-tuning.
- Partial NTK interpolation method, the model can achieve the best performance when fine-tuned with a small amount of longer context data.
The researcher said that before the birth of this paper, there were already researchers using NTK-aware interpolation and dynamic NTK interpolation for some open source Model. Examples include Code Llama (which uses NTK-aware interpolation) and Qwen 7B (which uses dynamic NTK interpolation). In this paper, based on previous research results on NTK-aware interpolation, dynamic NTK interpolation and partial NTK interpolation, the researcher proposed YaRN (Yet another RoPE extensioN method), a method that can efficiently expand the context window of models using Rotary Position Embeddings (RoPE), and can be used for LLaMA, GPT-NeoX and PaLM series models. The study found that YaRN can achieve the best context window expansion performance currently by only using representative samples that are approximately 0.1% of the original model’s pre-training data size for fine-tuning. Rotary Position Embeddings (RoPE) was first published in the paper "RoFormer: Enhanced transformer with rotary position embedding" was introduced and is also the basis of YaRN.Simply put, RoPE can be written in the following form: For LLM pre-trained with fixed context length, If positional interpolation (PI) is used to extend the context length, it can be expressed as: It can be seen that PI will extend all RoPE dimensions equally. The researchers found that the theoretical interpolation bounds described in the PI paper were insufficient to predict the complex dynamics between RoPE and LLM internal embeddings. The main problems of PI discovered and solved by researchers will be described below so that readers can understand the background, causes and reasons for solving various new methods in YaRN. High frequency information loss - NTK aware interpolationIf only from the perspective of information encoding Looking at RoPE, according to the Neural Tangent Kernel (NTK) theory, if the input dimension is low and the corresponding embedding lacks high-frequency components, then it is difficult for a deep neural network to learn high-frequency information. To solve the problem of losing high-frequency information when embedding interpolation for RoPE, Bowen Peng proposed NTK-aware interpolation in the above Reddit post. This approach does not expand each dimension of the RoPE equally, but rather spreads the interpolation pressure across multiple dimensions by expanding high frequencies less and low frequencies more. In tests, the researchers found that this approach outperformed PI in scaling the context size of untuned models. However, this approach has a significant drawback: since it is not just an interpolation scheme, some dimensions are extrapolated into some "outside" values, so fine-tuning using NTK-aware interpolation is not as effective as PI. #Furthermore, due to the existence of "outside" values, the theoretical expansion factor cannot accurately describe the true degree of context expansion. In practice, for a given context length extension, the extension value s must be set slightly higher than the expected extension value. Loss of relative local distance - partial NTK interpolation##For RoPE embedding, there is an interesting Observation: Given a context size L, there exist some dimensions d where the wavelength λ is longer than the maximum context length seen in the pre-training stage (λ > L), which illustrates the distribution of embeddings of some dimensions that may be in the rotated domain Uneven.
PI and NTK-aware interpolation treats all RoPE hidden dimensions equally (as if they have the same effect on the network). But researchers have found through experiments that the Internet treats some dimensions differently than other dimensions. As mentioned before, given a context length L, some dimensions have wavelengths λ greater than or equal to L. Since when the wavelength of a hidden dimension is greater than or equal to L, all position pairs will encode a specific distance, so the researchers hypothesize that the absolute position information is retained; when the wavelength is shorter, the network can only obtain the relative position. information.
When using the expansion ratio s or the base change value b' to stretch all RoPE dimensions, all tokens will become closer to each other because they are stretched by a smaller amount The dot product of two rotated vectors will be larger. This extension can seriously impair the LLM's ability to understand small local relationships between its internal embeddings. The researchers hypothesized that this compression would cause the model to become confused about the positional order of nearby tokens, thereby harming the model's ability.
To solve this problem, based on what the researchers observed, they chose not to interpolate higher frequency dimensions at all.
They also proposed that for all dimensions d, the dimensions of r
β are not interpolated at all (always extrapolated). Using the technique described in this section, a method called partial NTK interpolation was born. This improved method outperforms previous PI- and NTK-aware interpolation methods and works on both untuned and fine-tuned models. Because this method avoids extrapolating dimensions where the rotation domain is unevenly distributed, all fine-tuning problems of previous methods are avoided.
Dynamic Scaling - Dynamic NTK InterpolationExpand the context without fine-tuning when using the RoPE interpolation method size, we want the model to degrade slowly over longer context sizes, rather than completely degrading over the entire context size when the extension s exceeds the desired value.
In the dynamic NTK method, the extent s is calculated dynamically. During inference, when the context size is exceeded, the expansion degree s is dynamically changed, so that all models slowly reach the training context limit L Deterioration rather than sudden collapse. Increase the average minimum cosine similarity for long distances - YaRNEven if solved The local distance problem described earlier, in order to avoid extrapolation, also has to interpolate a larger distance at the threshold α. Intuitively, this does not seem to be a problem, because global distance does not require high accuracy to distinguish token positions (i.e. the network only needs to roughly know whether the token is at the beginning, middle, or end of the sequence). However, the researchers found that since the average minimum distance becomes closer as the number of tokens increases, it will make the attention softmax distribution become sharper ( That is, the average entropy of the attention softmax is reduced). In other words, as the impact of long-distance attenuation is reduced by interpolation, the network "pays more attention" to more tokens. This shift in distribution can lead to a degradation in the quality of the LLM output, which is another issue unrelated to the previous question. Since the entropy in the attention softmax distribution decreases when interpolating RoPE embeddings to longer context sizes, we aim to reverse this entropy decrease. (That is, increasing the "temperature" of the attention logit). This can be done by multiplying the intermediate attention matrix by the temperature t > 1 before applying softmax, but since the RoPE embedding is encoded as a rotation matrix, it is possible to simply extend the length of the RoPE embedding by a constant factor √t. This "length expansion" technique allows research without modifying the attention code, which greatly simplifies integration with existing training and inference pipelines and has a time complexity of only O(1). Since this RoPE interpolation scheme non-uniformly interpolates the RoPE dimensions, it is difficult to calculate an analytical solution for the required temperature scale t with respect to the degree of expansion s. Fortunately, the researchers found through experiments that by minimizing the degree of confusion, all LLaMA models follow roughly the same fitting curve: The researchers worked on LLaMA 7B, This formula is found on 13B, 33B and 65B. They found that this formula also worked well for the LLaMA 2 models (7B, 13B, and 70B), with subtle differences. This suggests that this entropy-increasing property is common and generalizes to different models and training data. This final modification resulted in the YaRN method. The new method outperforms all previous methods in both fine-tuned and un-tuned scenarios without requiring any modifications to the inference code. Only the algorithm used to generate RoPE embeddings in the first place needs to be modified. YaRN is so simple that it can be easily implemented in all inference and training libraries, including compatibility with Flash Attention 2. ##The experiment shows that YaRN can successfully expand the context window of LLM. Furthermore, they achieved this result after training for only 400 steps, which is roughly 0.1% of the model’s original pre-training corpus and a significant decrease from previous work. This shows that the new method is highly computationally efficient and has no additional inference cost.
To evaluate the resulting model, the researchers calculated the perplexity of long documents and scored them on existing benchmarks, and found that the new method outperformed all others. Context window extension method.
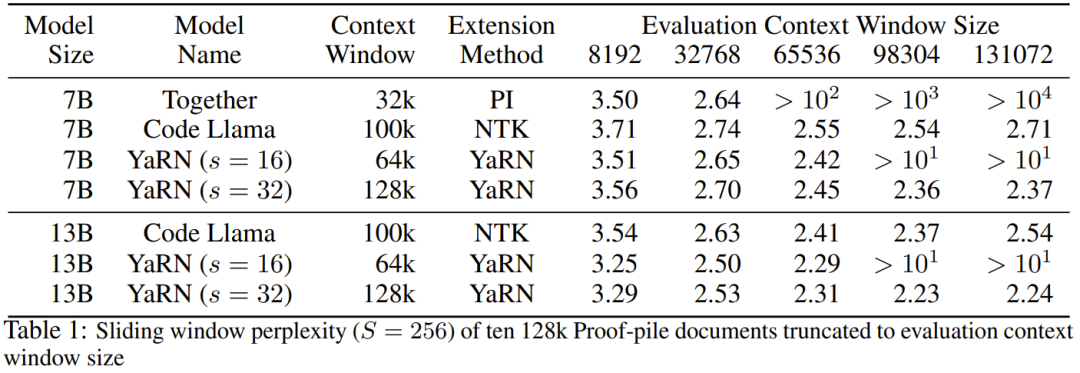
#First, the researchers evaluated the performance of the model when the context window was increased. Table 1 summarizes the experimental results.
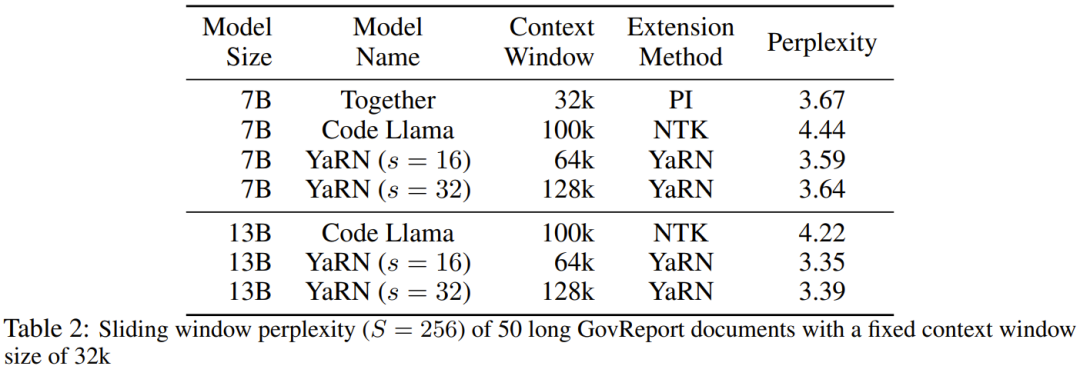
#Table 2 shows the final perplexity on 50 uncensored GovReport documents (at least 16k tokens in length).
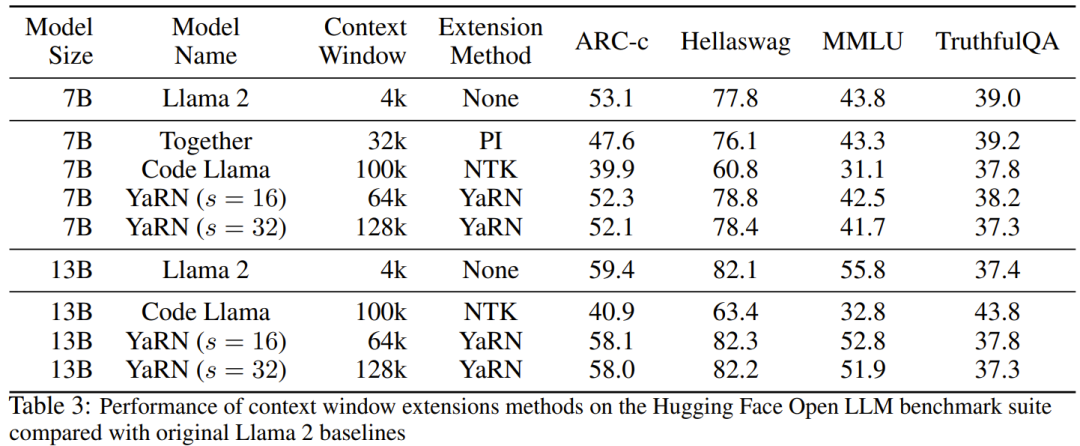
To test the degradation of model performance when using context extensions, the researchers evaluated the model using the Hugging Face Open LLM Leaderboard suite and compared it with the LLaMA 2 baseline model and the public Available scores for PI and NTK-aware models are compared. Table 3 summarizes the experimental results.
The above is the detailed content of If you want the large model to learn more examples in prompt, this method allows you to enter more characters. For more information, please follow other related articles on the PHP Chinese website!