
Home >Technology peripherals >AI >Transformer's pioneering paper is shocking? The picture is inconsistent with the code, and the mysterious bug makes me stupid
Transformer's pioneering paper is shocking? The picture is inconsistent with the code, and the mysterious bug makes me stupid

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-11 12:46:131554browse
Today, the AI circle was shocked by a shocking "overturn".
The diagrams in "Attention Is All Your Need", Google Brain's NLP foundation work and the pioneering paper proposing the Transformer architecture, were found by netizens to be inconsistent with the code.

## Paper address: https://arxiv.org/abs/1706.03762
Since its inception in 2017, Transformer has become the cornerstone king in the AI field. Even the real mastermind behind the popular ChatGPT is him.
In 2019, Google also applied for a patent specifically for it.

Tracing back to the origin, all kinds of GPT (Generative Pre-trained Transformer) that are emerging in an endless stream all originated from this article 17 years of thesis.
According to Google Scholar, so far, this foundational work has been cited more than 70,000 times.

So, the foundation stone of ChatGPT is not stable?
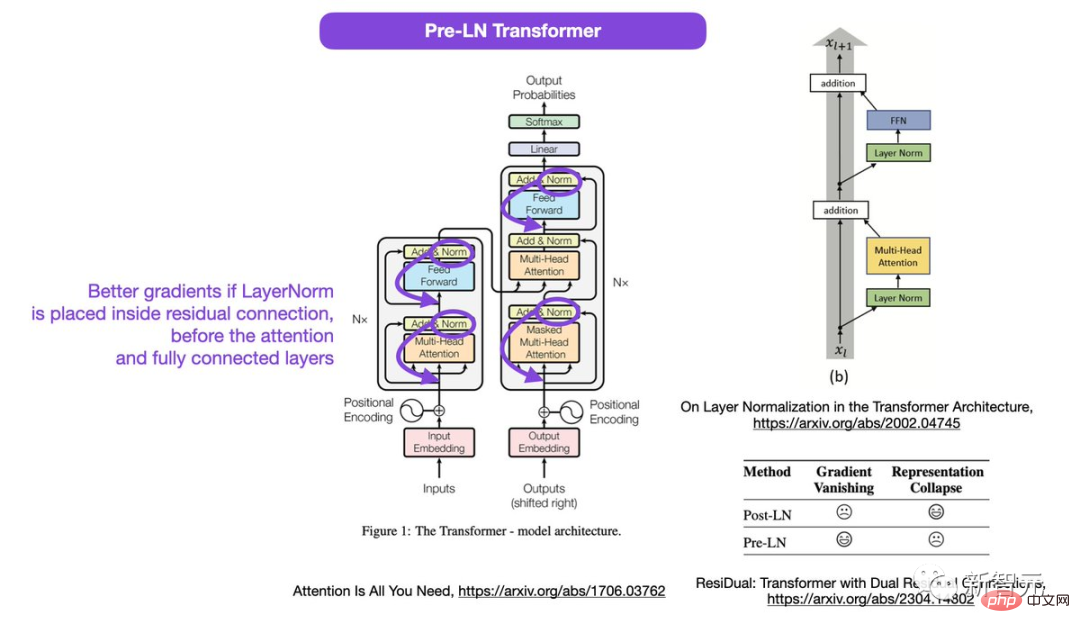
As the "originator" of the paper, the structure diagram is actually wrong?Sebastian Raschka, founder of Lightning AI and machine learning researcher, discovered that the Transformer diagram in this paper is wrong.
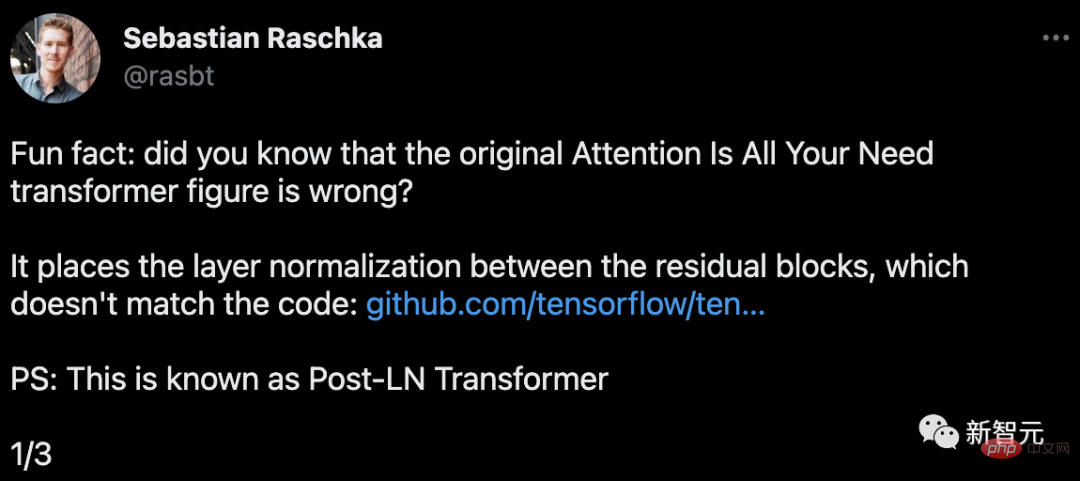
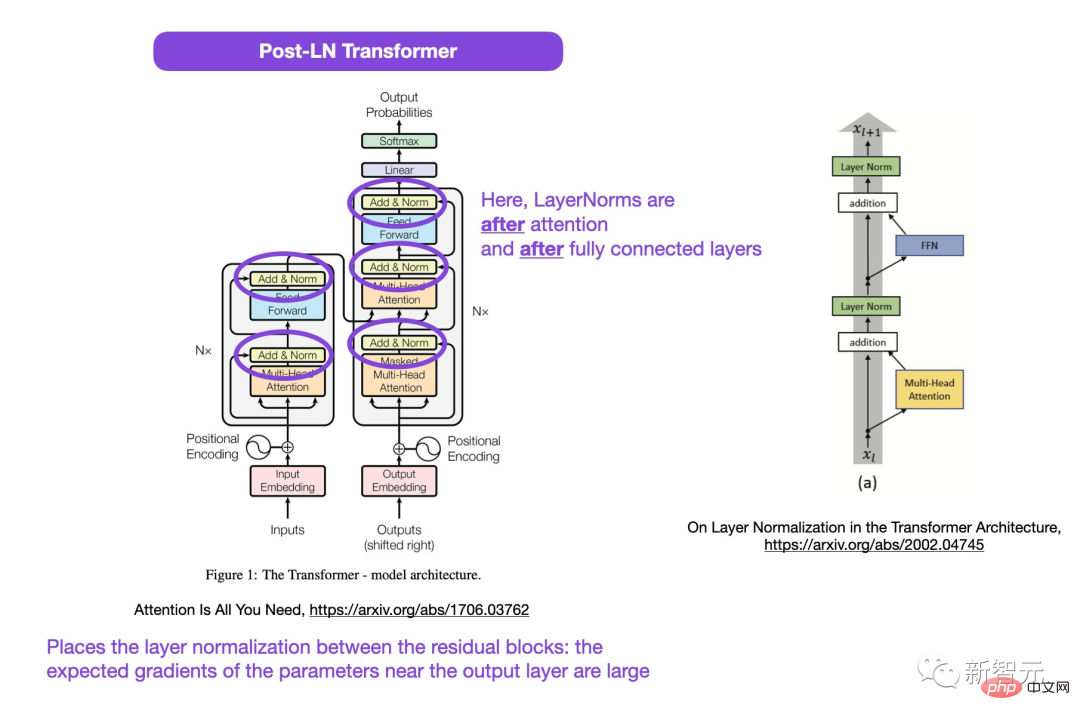
In the circled area in the figure, LayerNorms is after the attention and fully connected layers. Placing layer normalization between residual blocks results in large expected gradients for parameters near the output layer.
Also, this is inconsistent with the code.
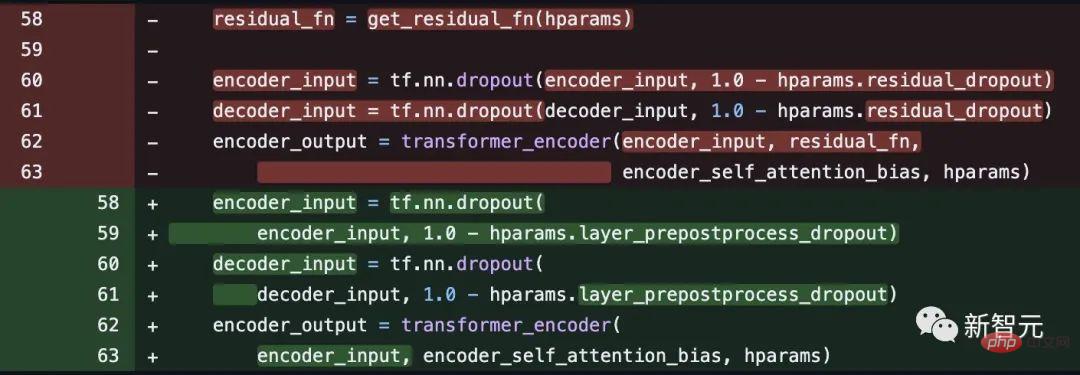
# Code address: https: //github.com/tensorflow/tensor2tensor/commit/f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef16871bdbf46bf04dfe7f1477bafb884748f08197c9cf1b10a4dd78e
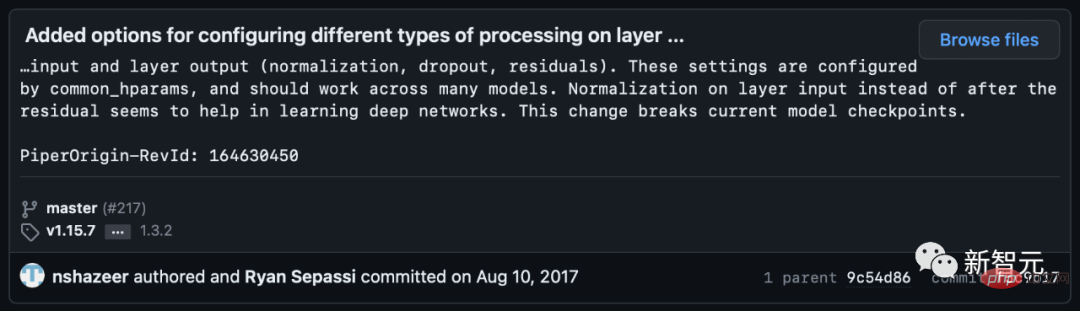
However, some netizens pointed out that Noam Shazeer corrected the code a few weeks later.

Better gradients will be achieved if the layer normalization is placed in the residual connection before the attention and fully connected layers.
Sebastian pointed out that although the discussion about using Post-LN or Pre-LN is still ongoing, there is also a new paper proposing to combine the two.

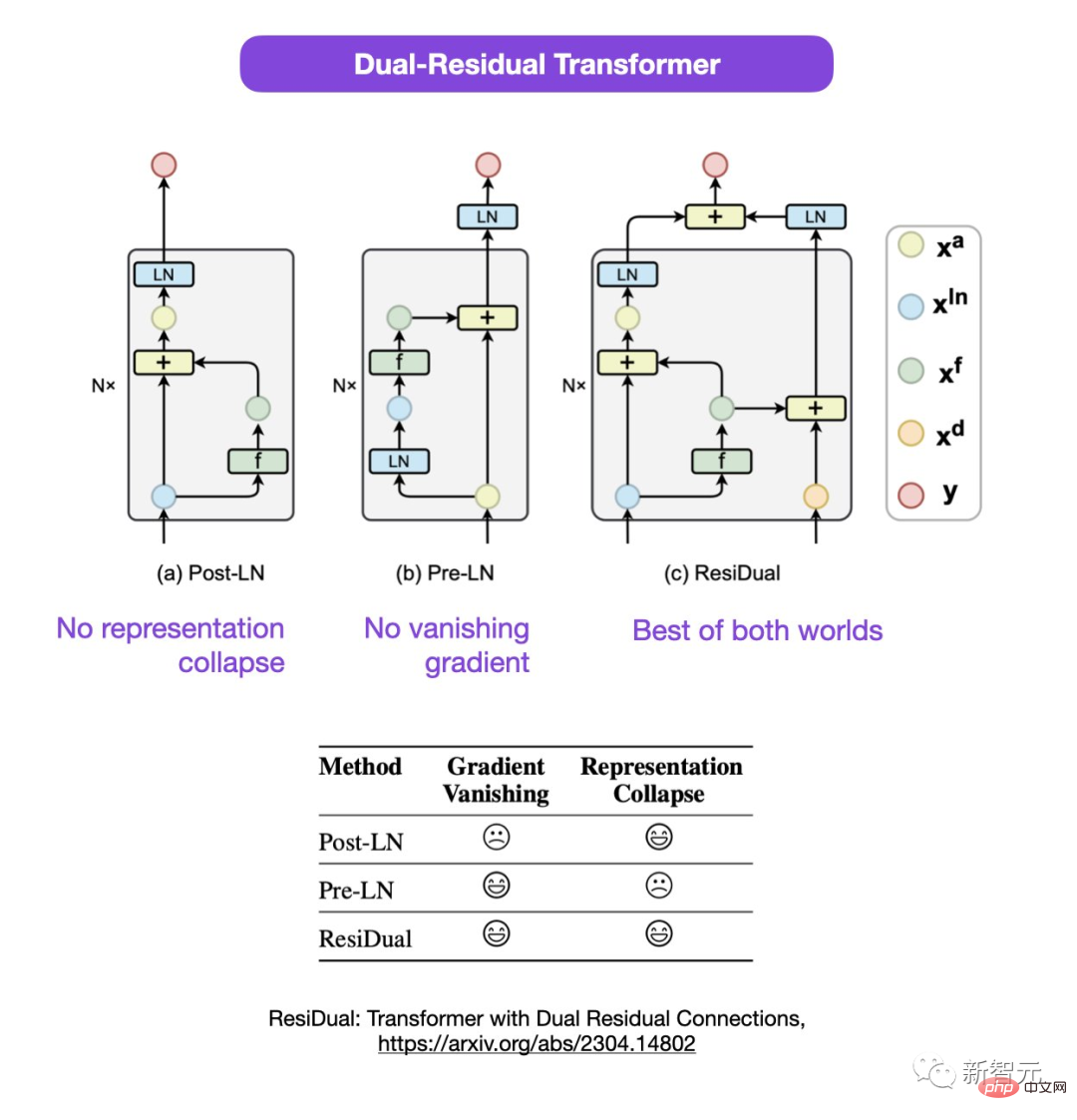
##Paper address: https://arxiv.org/abs/2304.14802
In this double-residual Transformer, the problems of representation collapse and gradient disappearance are solved.
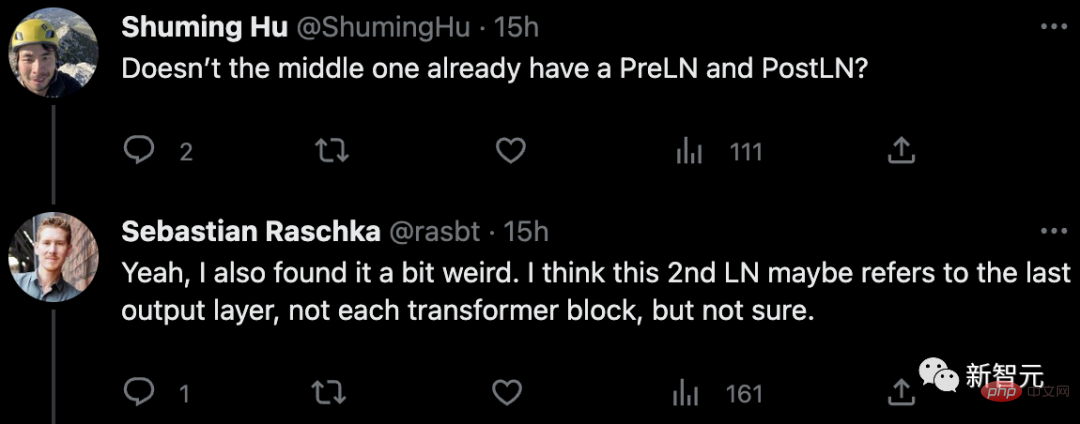
Regarding the doubtful points in the paper, some netizens pointed out: Isn’t there already something in the middle? Have you learned PreLN and PostLN?
Sebastian replied that he felt a little strange too. Maybe 2nd LN refers to the last output layer rather than each transformer block, but he's not sure about that either.
Some netizens said: "We often encounter papers that do not match the code or results. Most of them are due to Wrong, but sometimes people are very strange. This paper has been circulating for a long time, why this kind of question has never been raised before, it is really strange."

Sebastian said that to be fair, the original code was consistent with the picture, but they modified the code version in 2017 but did not update the picture. So, this is confusing.

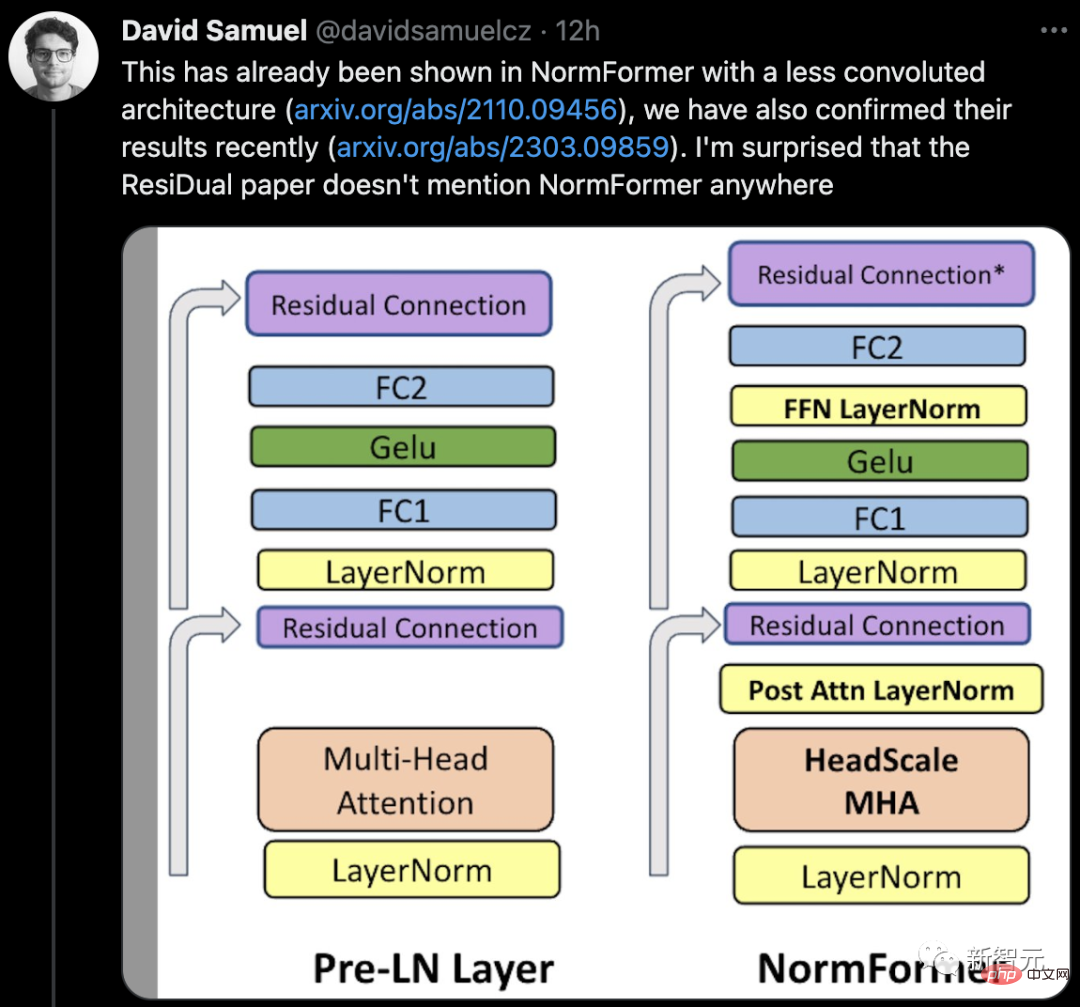
Some netizens said that there are already papers showing a less complex architecture in NormFormer, and his team Their results were also recently confirmed. The ResiDual paper does not mention NormFormer anywhere, which is surprising.


############# . ########################################So, the paper really has loopholes, Or an own incident? ############Let us wait and see what happens next. ######
The above is the detailed content of Transformer's pioneering paper is shocking? The picture is inconsistent with the code, and the mysterious bug makes me stupid. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology