
Home >Technology peripherals >It Industry >Anomaly Detection: Minimize False Positives with Rules Engine
Anomaly Detection: Minimize False Positives with Rules Engine

- DDDOriginal
- 2023-09-12 11:03:071879browse
Anomalies are deviations from expected patterns and can occur in a variety of environments—whether in banking transactions, industrial operations, the marketing industry, or healthcare monitoring. Traditional detection methods often produce high false alarm rates. A false positive occurs when a system incorrectly identifies a routine event as an anomaly, resulting in unnecessary investigation efforts and operational delays. This inefficiency is a pressing problem because it drains resources and diverts attention from the real problems that need to be solved. This article takes an in-depth look at a specialized approach to anomaly detection that makes extensive use of rule-based engines. This approach improves the accuracy of identifying violations by cross-referencing multiple key performance indicators (KPIs). Not only can this approach more effectively verify or disprove the presence of an anomaly, but it can sometimes also isolate and identify the root cause of the problem.
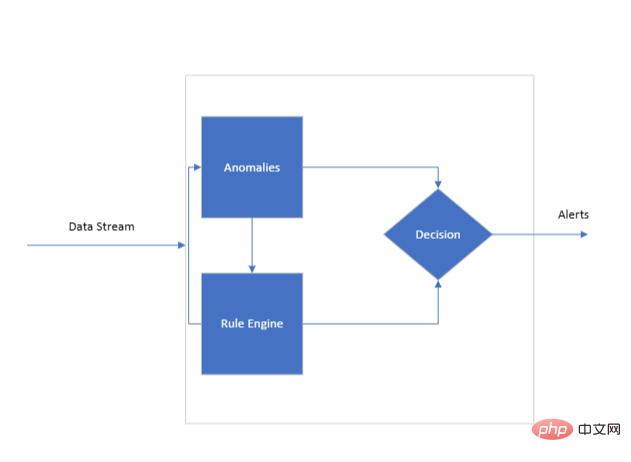
System Architecture Overview
Data Flow
This is the continuous data flow reviewed by the engine. Each point in the flow may be associated with one or more KPIs that are used by the rules engine to evaluate against its training ruleset. A continuous flow of data is essential for real-time monitoring, providing the engine with the necessary information to work.
Rules Engine Architecture
The heart of the system is the rules engine, which needs to be trained to understand the nuances of the KPIs it will monitor. This is where a set of KPI rules comes into play. These rules serve as the algorithmic basis of the engine and are designed to correlate two or more KPIs together.
Type of KPI rules:
- Data quality: rules that focus on the consistency, accuracy and reliability of data flow.
- KPI Relevance: Rules that focus on the relevance of certain KPIs
Rule application process
After receiving the data, the engine immediately looks for deviations or anomalies in the incoming KPIs. An anomaly here refers to any metric that falls outside a predetermined acceptable range. The engine flags these anomalies for further investigation, which can be divided into three main operations: accept, reject, and narrow down. This may involve correlating one KPI with another to validate or negate a detected anomaly.
Method
Rule Formation
The basic steps involve creating a series of KPIs that relate multiple KPIs to each other associated rules. For example, a rule might relate product quality metrics to production speed in a factory setting. For example:
- Direct relationship between KPIs: A "direct relationship" between two KPIs means that when one KPI increases, the other KPI also increases, or when one KPI decreases, the other will also decrease. For example, in a retail business, an increase in advertising spend (KPI1) may be directly related to an increase in sales revenue (KPI2). In this case, an increase in one of the aspects has a positive impact on the other. This knowledge is invaluable to businesses as it aids in strategic planning and resource allocation.
- Inverse relationship between KPIs: On the other hand, an “inverse relationship” means that when one KPI increases, the other KPI decreases and vice versa. For example, in a manufacturing environment, the time it takes to produce a product (KPI1) may have an inverse relationship with productivity (KPI2). As production time is reduced, productivity may increase. Understanding the inverse relationship is also critical for business optimization, as it may require balancing measures to optimize both KPIs.
- Combine KPIs to create new rules: Sometimes it can be beneficial to combine two or more KPIs to create a new metric that can provide valuable insights into business performance. For example, combining Customer Lifetime Value (KPI1) and Customer Acquisition Cost (KPI2) results in a third KPI: Customer Value to Cost Ratio. This new KPI provides a more comprehensive understanding of whether the cost of acquiring a new customer is commensurate with the value it delivers over time.
Training rule engine
The rule engine has been comprehensively trained and can effectively Apply these rules.
Real-time review
The rules engine proactively monitors incoming data, applying its trained rules to identify anomalies or potential anomalies.
Decision
In identifying potential anomalies, the engine:
- Accepting exceptions: Confirmation phase: After an exception is flagged, the engine will compare it with other associated KPIs using its pre-trained KPI rules. The point here is to determine whether the anomaly is actually a problem or just an outlier. This confirmation is done based on the correlation between primary and secondary KPIs.
- Reject exceptions: False positive phase: Not all exceptions indicate a problem; some may be statistical outliers or data errors. In this case, the engine uses its training to reject the anomaly, essentially identifying it as a false positive. This is critical to eliminating unnecessary alert fatigue and focusing resources on the real problem.
- Narrowing down the scope of the exception: Refinement phase: Sometimes, an exception can be part of a larger problem that affects multiple components. Here, the engine further pinpoints the exact nature of the problem by narrowing it down to specific KPI components. This advanced filtering helps quickly identify issues and resolve root causes.
Advantages
- Reduce false positives: By using a rules engine that cross-references multiple KPIs, the system greatly reduces Incidence of false positives.
- Time and Cost Efficiency: Detection and resolution of anomalies is increased, reducing operational time and associated costs.
- Improve Accuracy: The ability to compare and contrast multiple KPIs allows for a more granular and accurate representation of abnormal events.
Conclusion
This article outlines an approach to anomaly detection using a rules engine trained on various KPI rule sets. In contrast to traditional anomaly detection systems, which often rely solely on statistical algorithms or machine learning models, this approach uses a specialized rules engine as its cornerstone. By delving deeper into the relationships and interactions between different KPIs, businesses can gain more granular insights that simple, stand-alone metrics cannot provide. This enables more robust strategic planning, better risk management, and an overall more effective approach to achieving business goals. Once an anomaly is flagged, the engine compares it to other associated KPIs using its pre-trained KPI rules. The point here is to determine whether the anomaly is actually a problem or just an outlier.
The above is the detailed content of Anomaly Detection: Minimize False Positives with Rules Engine. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Rethinking anomaly detection based on structured data: What kind of graph neural network do we need?
- How to perform application log analysis and anomaly detection through Python
- Anomaly detection algorithm implementation steps in PHP
- How to use PHP to implement anomaly detection and fraud analysis
- Python for time series analysis: forecasting and anomaly detection