
Home >Technology peripherals >AI >Dubbo load balancing strategy consistent hashing
Dubbo load balancing strategy consistent hashing

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-06-26 15:39:181856browse
This article mainly explains the principle of the consistent hash algorithm and its existing data skew problem, then introduces methods to solve the data skew problem, and finally analyzes the use of the consistent hash algorithm in Dubbo. This article introduces how the consistent hashing algorithm works, as well as the problems and solutions faced by the algorithm.
1. Load Balancing
Here is a quote from dubbo’s official website——
LoadBalance in Chinese means load balancing. Its responsibility is to transfer network requests, or other forms of The load is "evenly distributed" to different machines. Avoid the situation where some servers in the cluster are under excessive pressure while other servers are relatively idle. Through load balancing, each server can obtain a load suitable for its own processing capabilities. While offloading high-load servers, you can also avoid wasting resources, killing two birds with one stone. Load balancing can be divided into software load balancing and hardware load balancing. In our daily development, it is generally difficult to access hardware load balancing. But software load balancing is still available, such as Nginx. In Dubbo, there is also the concept of load balancing and corresponding implementation.
In order to avoid excessive load on certain service providers, Dubbo needs to allocate call requests from service consumers. The service provider's load is too large, which may cause some requests to time out. Therefore, it is very necessary to balance the load to each service provider. Dubbo provides 4 load balancing implementations, namely RandomLoadBalance based on weighted random algorithm, LeastActiveLoadBalance based on least active calls algorithm, ConsistentHashLoadBalance based on hash consistency, and RoundRobinLoadBalance based on weighted polling algorithm. Although the codes of these load balancing algorithms are not very lengthy, understanding their principles requires certain professional knowledge and understanding.
2. Hash algorithm
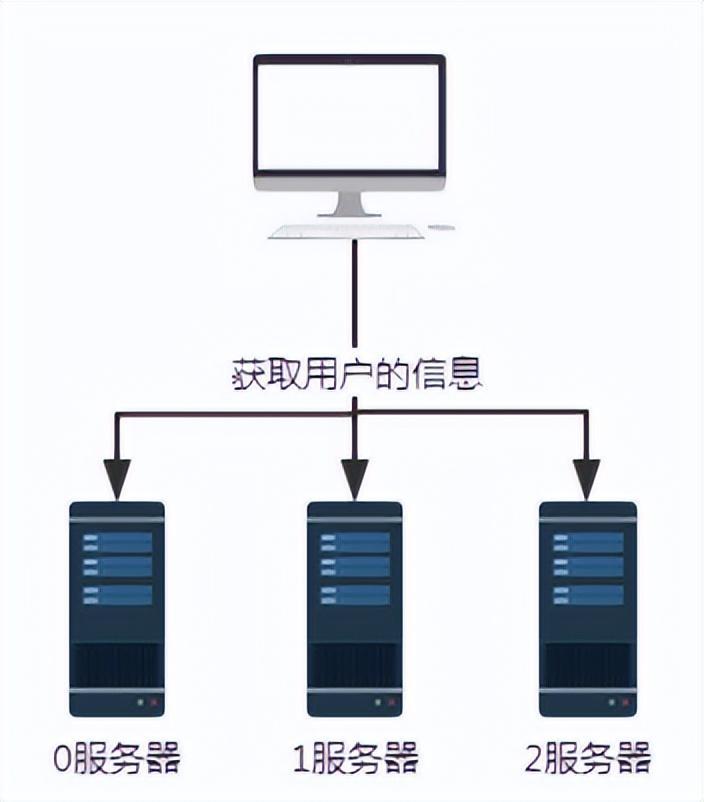
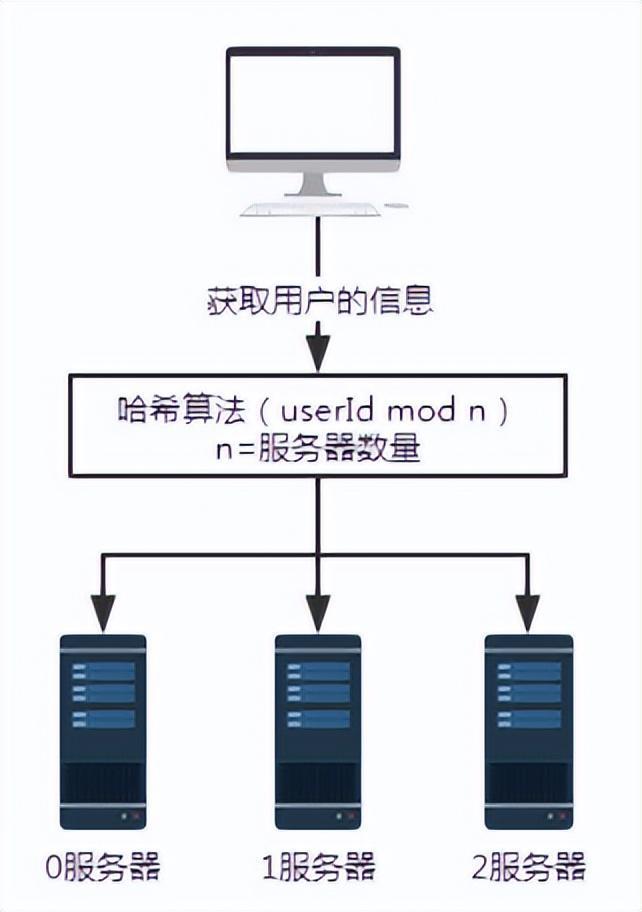
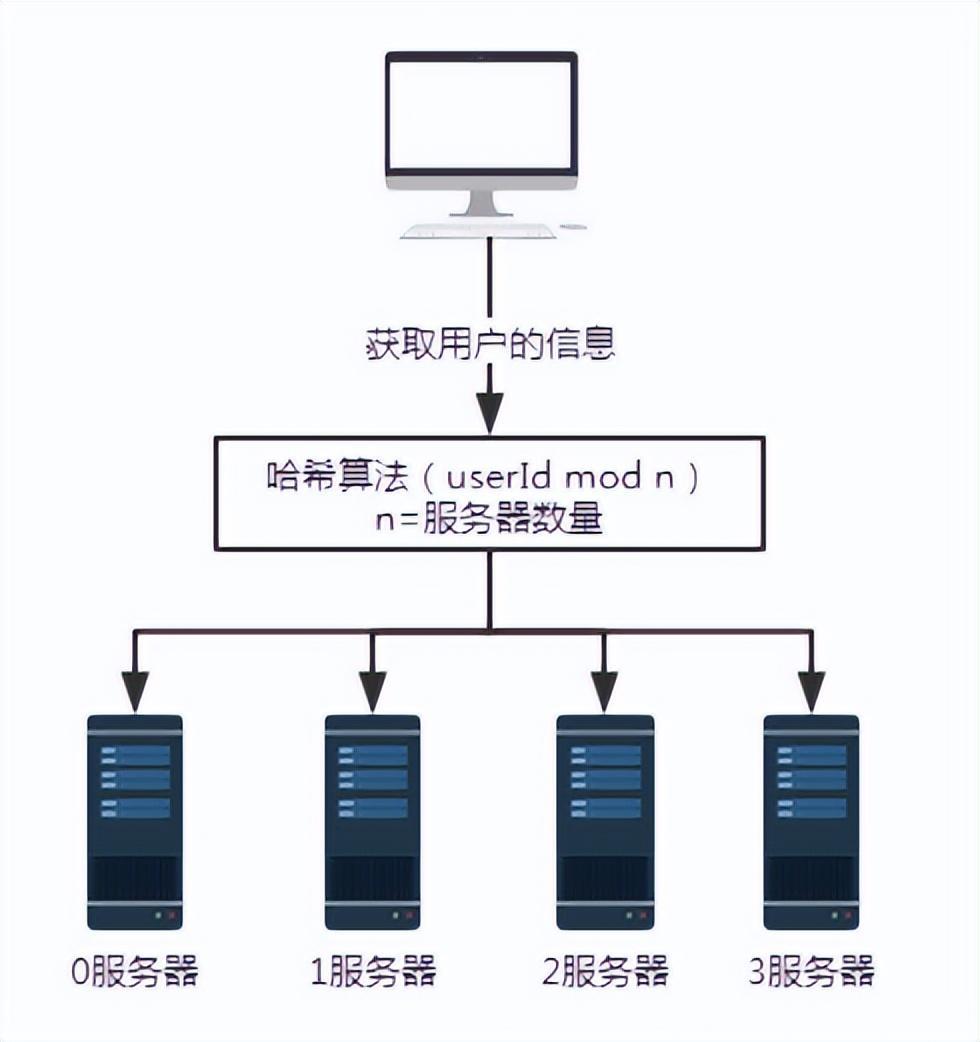
- When the number of servers is 3, the request with user number 100 will be processed by server No. 1.
- When the number of servers is 4, the request with user number 100 will be processed by server 0.
3. Consistent Hash Algorithm
** The consistent hash algorithm was proposed by Karger and his collaborators at MIT in 1997. The algorithm was originally proposed for large-scale cache systems. load balancing. ** Its working process is as follows. First, a hash is generated for the cache node based on IP or other information, and this hash is projected onto the ring of [0, 232 - 1]. Whenever there is a query or write request, a hash value is generated for the cache item's key. Next, you need to find the first node in the cache node with a hash value greater than or equal to the given value, and perform a cache query or write operation on this node. When the current node expires, on the next cache query or write, another cache node with a hash greater than the current cache entry can be looked up. The general effect is as shown in the figure below. Each cache node occupies a position on the ring. When the hash value of the cache item's key is less than the hash value of the cache node, the cache item will be stored or read from the cache node. The cache item corresponding to the green mark below will be stored in node cache-2. The cache items were originally supposed to be stored in the cache-3 node, but due to the downtime of this node, they were eventually stored in the cache-4 node.
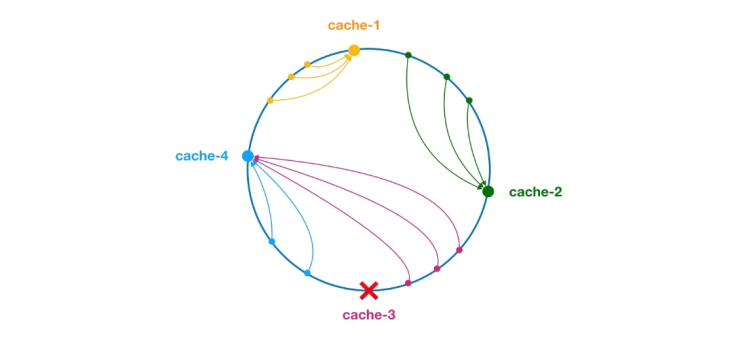
Figure 4 Consistent Hash Algorithm
In the consistent hash algorithm, whether it is adding nodes or downtime nodes, the affected interval It only increases or crashes the interval between the first server encountered in the counterclockwise direction in the hash ring space, and other intervals will not be affected.
But consistent hashing also has problems:
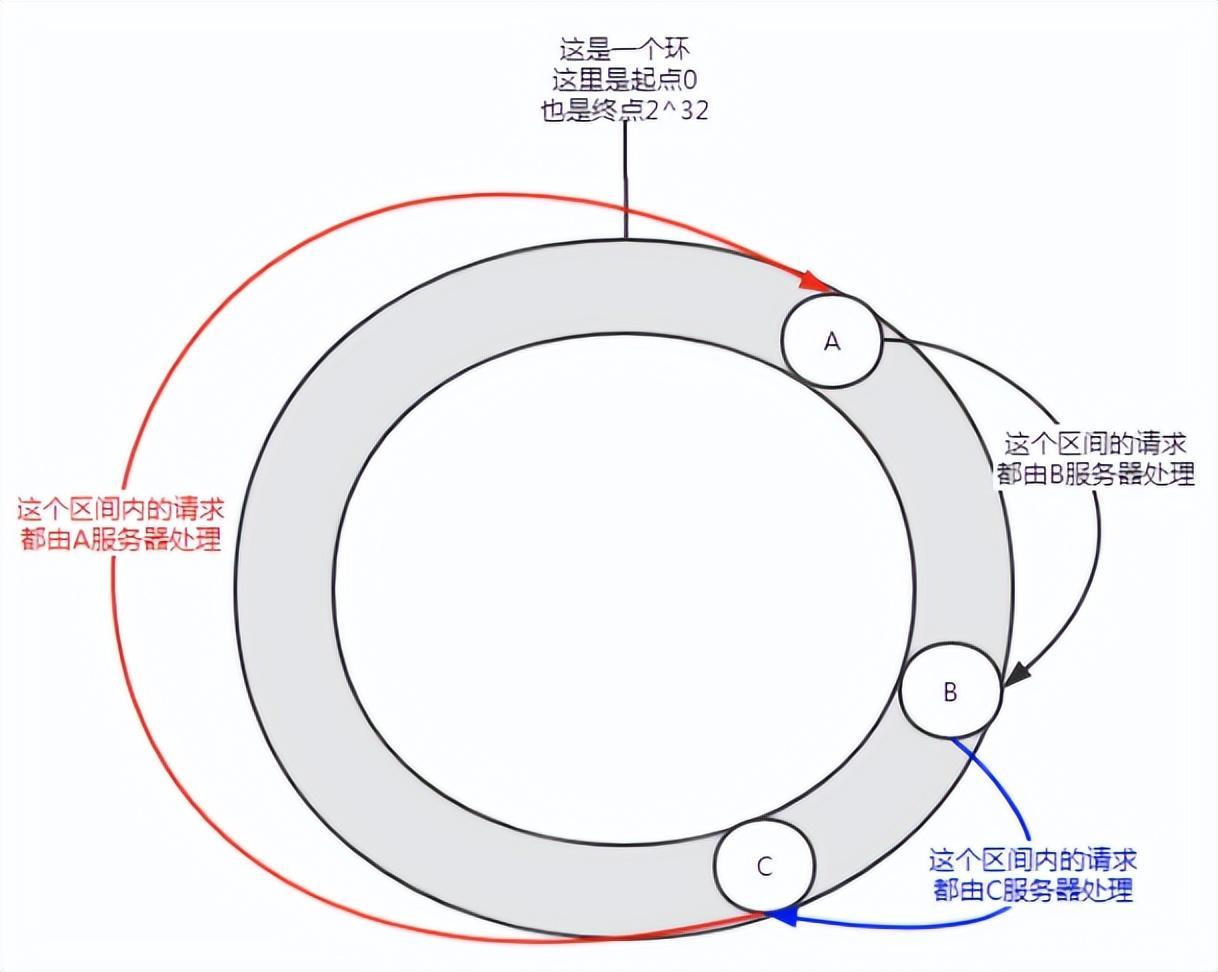
Figure 5 Data skew
May occur when there are few nodes In this distribution situation, service A will bear most of the requests. This situation is called data skew.
So how to solve the problem of data skew?
Join virtual node.
First of all, a server can have multiple virtual nodes as needed. Suppose a server has n virtual nodes. In a hash calculation, a combination of IP address, port number, and number can be used to calculate the hash value. The number is a number from 0 to n. These n nodes all point to the same machine because they share the same IP address and port number.
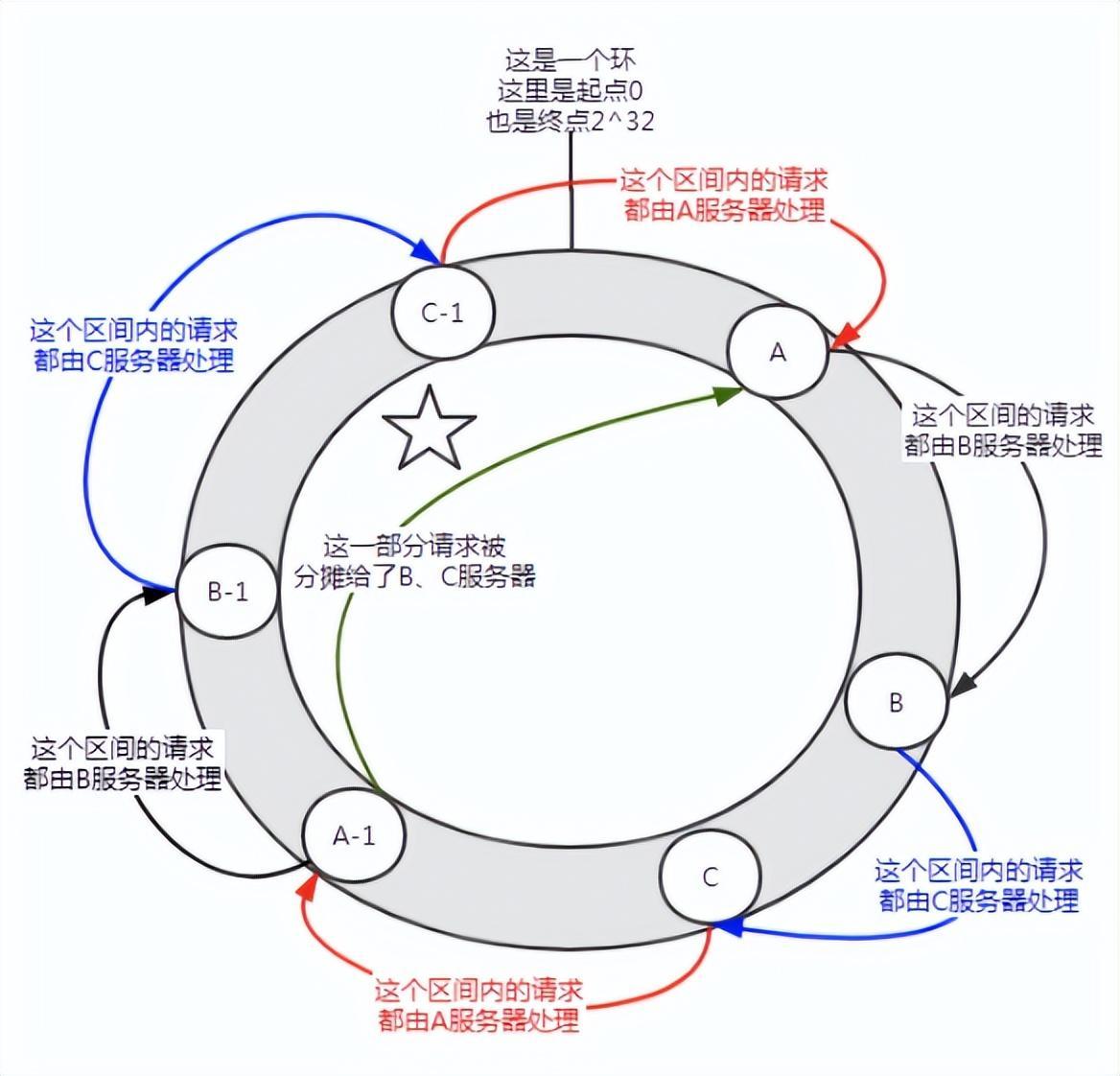
Figure 6 Introducing a virtual node
Before joining the virtual node, server A shouldered the vast majority of requests. If each server has a virtual node (A-1, B-1, C-1) and is assigned to the location shown in the figure above through hash calculation. Then the requests undertaken by server A are allocated to the B-1 and C-1 virtual nodes to a certain extent (the part marked with a five-pointed star in the figure), which is actually allocated to the B and C servers.
In the consistent hash algorithm, adding virtual nodes can solve the problem of data skew.
4. Application of consistent hashing in DUBBO
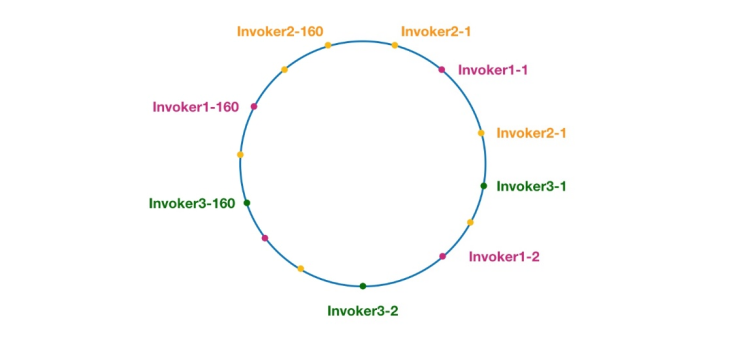
Figure 7 Consistent hashing ring in Dubbo
The same color here The nodes all belong to the same service provider, such as Invoker1-1, Invoker1-2,..., Invoker1-160. By adding virtual nodes, we can spread the Invoker over the hash ring, thus avoiding the data skew problem. The so-called data skew refers to the situation where a large number of requests fall on the same node because the nodes are not dispersed enough, while other nodes only receive a small number of requests. For example:
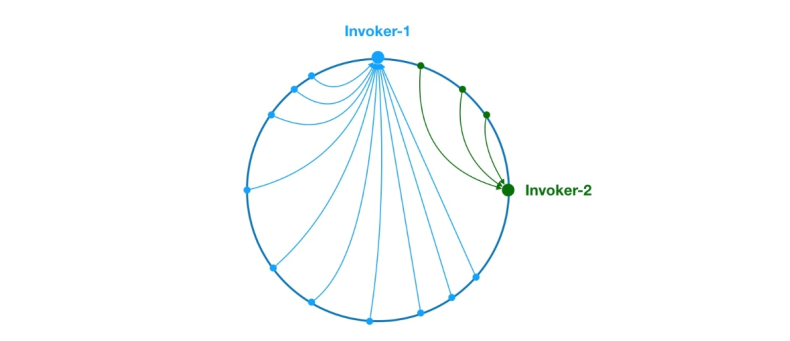
Figure 8 Data skew problem
As above, due to the uneven distribution of Invoker-1 and Invoker-2 on the ring, 75 in the system % of the requests will fall on Invoker-1, and only 25% of the requests will fall on Invoker-2. In order to solve this problem, virtual nodes can be introduced to balance the request volume of each node.
Now that the background knowledge has been popularized, let’s start analyzing the source code. Let's start with the doSelect method of ConsistentHashLoadBalance, as follows:
public class ConsistentHashLoadBalance extends AbstractLoadBalance {private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String methodName = RpcUtils.getMethodName(invocation);String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;// 获取 invokers 原始的 hashcodeint identityHashCode = System.identityHashCode(invokers);ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);// 如果 invokers 是一个新的 List 对象,意味着服务提供者数量发生了变化,可能新增也可能减少了。// 此时 selector.identityHashCode != identityHashCode 条件成立if (selector == null || selector.identityHashCode != identityHashCode) {// 创建新的 ConsistentHashSelectorselectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));selector = (ConsistentHashSelector<T>) selectors.get(key);}// 调用 ConsistentHashSelector 的 select 方法选择 Invokerreturn selector.select(invocation);}private static final class ConsistentHashSelector<T> {...}}
As above, the doSelect method mainly does some preparatory work, such as detecting whether the invokers list has changed, and creating a ConsistentHashSelector. After these tasks are completed, the select method of ConsistentHashSelector is called to execute the load balancing logic. Before analyzing the select method, let's first take a look at the initialization process of the consistent hash selector ConsistentHashSelector, as follows:
private static final class ConsistentHashSelector<T> {// 使用 TreeMap 存储 Invoker 虚拟节点private final TreeMap<Long, Invoker<T>> virtualInvokers;private final int replicaNumber;private final int identityHashCode;private final int[] argumentIndex;ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {this.virtualInvokers = new TreeMap<Long, Invoker<T>>();this.identityHashCode = identityHashCode;URL url = invokers.get(0).getUrl();// 获取虚拟节点数,默认为160this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);// 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));argumentIndex = new int[index.length];for (int i = 0; i < index.length; i++) {argumentIndex[i] = Integer.parseInt(index[i]);}for (Invoker<T> invoker : invokers) {String address = invoker.getUrl().getAddress();for (int i = 0; i < replicaNumber / 4; i++) {// 对 address + i 进行 md5 运算,得到一个长度为16的字节数组byte[] digest = md5(address + i);// 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数for (int h = 0; h < 4; h++) {// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算// h = 2, h = 3 时过程同上long m = hash(digest, h);// 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,// virtualInvokers 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构virtualInvokers.put(m, invoker);}}}}}
ConsistentHashSelector 的构造方法执行了一系列的初始化逻辑,比如从配置中获取虚拟节点数以及参与 hash 计算的参数下标,默认情况下只使用第一个参数进行 hash。需要特别说明的是,ConsistentHashLoadBalance 的负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。注意到 ConsistentHashLoadBalance 无需考虑权重的影响。
在获取虚拟节点数和参数下标配置后,接下来要做的事情是计算虚拟节点 hash 值,并将虚拟节点存储到 TreeMap 中。ConsistentHashSelector的初始化工作在此完成。接下来,我们来看看 select 方法的逻辑。
public Invoker<T> select(Invocation invocation) {// 将参数转为 keyString key = toKey(invocation.getArguments());// 对参数 key 进行 md5 运算byte[] digest = md5(key);// 取 digest 数组的前四个字节进行 hash 运算,再将 hash 值传给 selectForKey 方法,// 寻找合适的 Invokerreturn selectForKey(hash(digest, 0));}private Invoker<T> selectForKey(long hash) {// 到 TreeMap 中查找第一个节点值大于或等于当前 hash 的 InvokerMap.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();// 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,// 需要将 TreeMap 的头节点赋值给 entryif (entry == null) {entry = virtualInvokers.firstEntry();}// 返回 Invokerreturn entry.getValue();}
如上,选择的过程相对比较简单了。首先,需要对参数进行 md5 和 hash 运算,以生成一个哈希值。接着使用这个值去 TreeMap 中查找需要的 Invoker。
到此关于 ConsistentHashLoadBalance 就分析完了。
在阅读 ConsistentHashLoadBalance 源码之前,建议读者先补充背景知识,不然看懂代码逻辑会有很大难度。
五、应用场景
- DNS 负载均衡最早的负载均衡技术是通过 DNS 来实现的,在 DNS 中为多个地址配置同一个名字,因而查询这个名字的客户机将得到其中一个地址,从而使得不同的客户访问不同的服务器,达到负载均衡的目的。DNS 负载均衡是一种简单而有效的方法,但是它不能区分服务器的差异,也不能反映服务器的当前运行状态。
- 代理服务器负载均衡使用代理服务器,可以将请求转发给内部的服务器,使用这种加速模式显然可以提升静态网页的访问速度。然而,也可以考虑这样一种技术,使用代理服务器将请求均匀转发给多台服务器,从而达到负载均衡的目的。
- 地址转换网关负载均衡支持负载均衡的地址转换网关,可以将一个外部 IP 地址映射为多个内部 IP 地址,对每次 TCP 连接请求动态使用其中一个内部地址,达到负载均衡的目的。
- 协议内部支持负载均衡除了这三种负载均衡方式之外,有的协议内部支持与负载均衡相关的功能,例如 HTTP 协议中的重定向能力等,HTTP 运行于 TCP 连接的最高层。
- NAT 负载均衡 NAT(Network Address Translation 网络地址转换)简单地说就是将一个 IP 地址转换为另一个 IP 地址,一般用于未经注册的内部地址与合法的、已获注册的 Internet IP 地址间进行转换。适用于解决 Internet IP 地址紧张、不想让网络外部知道内部网络结构等的场合下。
- 反向代理负载均衡普通代理方式是代理内部网络用户访问 internet 上服务器的连接请求,客户端必须指定代理服务器,并将本来要直接发送到 internet 上服务器的连接请求发送给代理服务器处理。反向代理(Reverse Proxy)方式是指以代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器。反向代理负载均衡技术是把将来自 internet 上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
- 混合型负载均衡在有些大型网络,由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。
作者:京东物流 乔杰
来源:京东云开发者社区
The above is the detailed content of Dubbo load balancing strategy consistent hashing. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology