
Home >Technology peripherals >AI >New research results from Yann LeCun's team: Reverse engineering of self-supervised learning, it turns out that clustering is implemented like this
New research results from Yann LeCun's team: Reverse engineering of self-supervised learning, it turns out that clustering is implemented like this

- 王林forward
- 2023-06-15 11:27:541035browse
Self-supervised learning (SSL) has made great progress in recent years and has almost reached the level of supervised learning methods on many downstream tasks. However, due to the complexity of the model and the lack of annotated training data sets, it has been difficult to understand the learned representations and their underlying working mechanisms. Furthermore, pretext tasks used in self-supervised learning are often not directly related to specific downstream tasks, which further increases the complexity of interpreting the learned representations. In supervised classification, the structure of the learned representation is often very simple.
Compared with traditional classification tasks (the goal is to accurately classify samples into specific categories), the goal of modern SSL algorithms is usually to minimize a loss function containing two major components: First, Cluster the enhanced samples (invariance constraints), and the second is to prevent representation collapse (regularization constraints). For example, for the same sample after different enhancements, the goal of the contrastive learning method is to make the classification results of these samples the same, while at the same time being able to distinguish different enhanced samples. On the other hand, non-contrastive methods use regularizers to avoid representation collapse.
Self-supervised learning can use the auxiliary task (pretext) unsupervised data to mine its own supervision information, and train the network through this constructed supervision information, so that it can learn to downstream Representation that the task is valuable. Recently, several researchers, including Turing Award winner Yann LeCun, released a study claiming to have reverse-engineered self-supervised learning, allowing us to understand the internal behavior of its training process.

##Paper address: https://arxiv.org/abs/2305.15614v2
This paper provides an in-depth analysis of representation learning using SLL through a series of carefully designed experiments to help people understand the clustering process during training. Specifically, we reveal that augmented samples exhibit highly clustered behavior, forming centroids around the meaning embeddings of augmented samples that share the same image. Even more unexpectedly, the researchers observed that samples clustered based on semantic labels even in the absence of explicit information about the target task. This demonstrates the ability of SSL to group samples based on semantic similarity.
Problem SettingSince self-supervised learning (SSL) is often used for pre-training to prepare the model to adapt to downstream tasks, this brings up a key question: What impact does SSL training have on learned representations? Specifically, how does SSL work under the hood during training, and what categories can these representation functions learn?
To investigate these issues, researchers trained SSL networks on multiple settings and analyzed their behavior using different techniques.
Data and Augmentation: All experiments mentioned in this article used the CIFAR100 image classification dataset. To train the model, the researchers used the image enhancement protocol proposed in SimCLR. Each SSL training session is executed for 1000 epochs, using the SGD optimizer with momentum.
Backbone architecture: All experiments used the RES-L-H architecture as the backbone, coupled with two layers of multi-layer perceptron (MLP) projection heads.
Linear probing: To evaluate the effectiveness of extracting a given discrete function (e.g. category) from a representation function, the method used here is linear probing. This requires training a linear classifier (also called a linear probe) based on this representation, which requires some training samples.
Sample-level classification: To assess sample-level separability, the researchers created a specialized new dataset.
The training data set contains 500 random images from the CIFAR-100 training set. Each image represents a specific category and is enhanced in 100 different ways. Therefore, the training dataset contains a total of 50,000 samples of 500 categories. The test set still uses these 500 images, but uses 20 different enhancements, all from the same distribution. Therefore, the results in the test set consist of 10,000 samples. In order to measure the linear or NCC (nearest class-center/nearest class center) accuracy of a given representation function at the sample level, the method adopted here is to first use the training data to calculate a relevant classifier, and then calculate it on the corresponding test set Evaluate its accuracy.
Revealing the clustering process of self-supervised learning
The clustering process has always played an important role in helping analyze deep learning models. In order to intuitively understand SSL training, Figure 1 visualizes the embedding space of the training samples of the network through UMAP, which includes the situation before and after training and is divided into different levels.
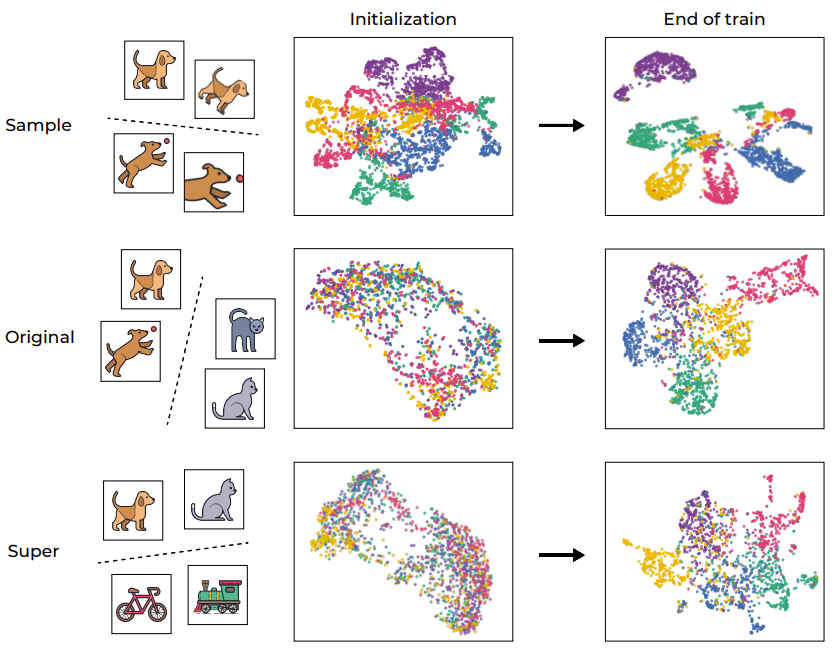
Figure 1: Semantic clustering induced by SSL training
As expected, the training process successfully clustered the samples at the sample level, mapping different enhancements of the same image (as shown in the first row of figure Show). This result is not unexpected given that the objective function itself encourages this behavior (via the invariance loss term). More notably, however, this training process also clusters based on the original "semantic categories" of the standard CIFAR-100 dataset, even though there is a lack of labels during the training process. Interestingly, higher levels (supercategories) can also be efficiently clustered. This example shows that although the training process directly encourages clustering at the sample level, the data representation of SSL training also clusters according to semantic categories at different levels.
To further quantify this clustering process, the researchers used VICReg to train a RES-10-250. The researchers measured NCC training accuracy, both at the sample level and based on original categories. It is worth noting that the representations trained by SSL exhibit neural collapse at the sample level (NCC training accuracy is close to 1.0), but the clustering in terms of semantic categories is also significant (approximately 1.0 on the original target) 0.41).
As shown in the left picture of Figure 2, most of the clustering processes involving enhancement (on which the network is directly trained) occur in the early stages of the training process and then stagnate; while in semantic Category-wise clustering (not specified in the training objective) will continue to improve during training.
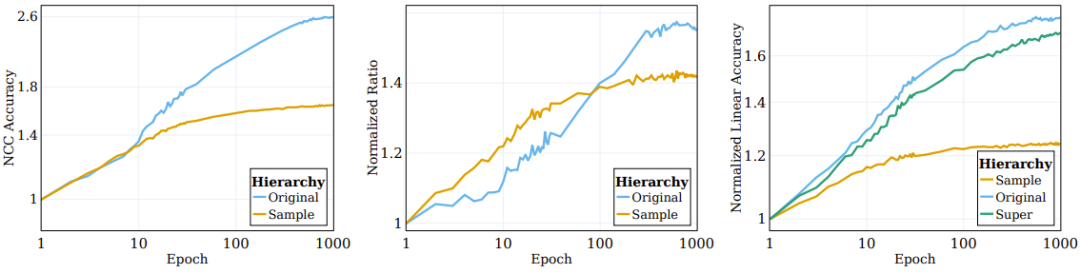
Figure 2: SSL algorithm clusters data according to semantic target pairs
Previous researchers have observed that the top-level embeddings of supervised training samples will gradually converge towards a centroid-like structure. To better understand the clustering nature of SSL-trained representation functions, we investigated similar situations during SSL. Its NCC classifier is a linear classifier and does not perform better than the best linear classifier. Data clustering can be studied at different levels of granularity by evaluating the accuracy of the NCC classifier compared to a linear classifier trained on the same data. The middle panel of Figure 2 shows the evolution of this ratio across sample-level categories and original target categories, with values normalized to the initialized values. As SSL training proceeds, the gap between NCC accuracy and linear accuracy becomes smaller, indicating that the augmented samples gradually improve the clustering level based on their sample identities and semantic properties.
Additionally, the figure also illustrates that the sample-level ratios are initially higher, indicating that the augmented samples are clustered according to their identities until they converge to the centroid (NCC accurate The ratio of precision and linearity accuracy is ≥ 0.9 at 100 epochs). However, as training continues, the sample-level ratios saturate, while the class-level ratios continue to grow and converge to around 0.75. This shows that the enhanced samples will first be clustered according to the sample identity, and after implementation, they will be clustered according to high-level semantic categories.
Implicit information compression in SSL training
If compression can be performed effectively, beneficial and useful representations can be obtained. However, whether such compression occurs during SSL training is still a topic that few people have studied.
To understand this, the researchers used Mutual Information Neural Estimation (MINE), a method that estimates the relationship between the input and its corresponding embedded representation during training. mutual information. This metric can be used to effectively measure the complexity level of a representation by showing how much information (number of bits) it encodes.
The middle panel of Figure 3 reports the average mutual information calculated on 5 different MINE initialization seeds. As shown in the figure, there is significant compression during the training process, resulting in a highly compact training representation.
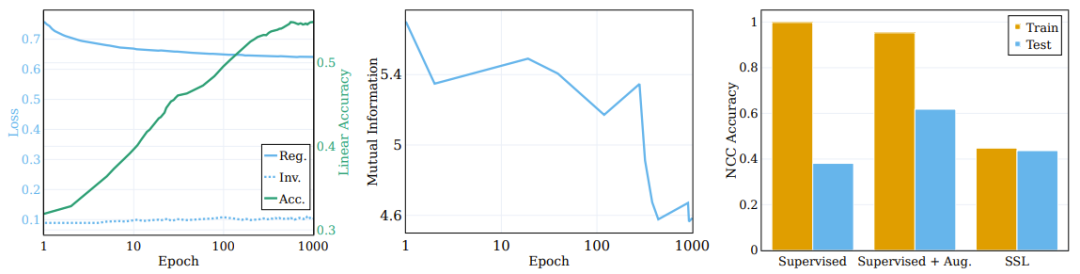
The chart on the left shows the regularization and invariance of the SSL training model during the training process Changes in loss and original target linearity test accuracy. (Center) Compression of mutual information between input and representation during training. (Right) SSL training learns representations of clusters.
The role of regularization loss
The objective function contains two items: invariance and Regularization. The main function of the invariance term is to reinforce the similarity between differently enhanced representations of the same sample. The goal of the regularization term is to help prevent representation collapse.
In order to explore the role of these components on the clustering process, the researchers decomposed the objective function into invariance terms and regularization terms and observed their behavior during the training process. The comparison results are shown in the left panel of Figure 3, where the evolution of the loss term on the original semantic target and the linear test accuracy are given. Contrary to popular belief, the invariance loss term does not improve significantly during training. Instead, improvements in loss (and downstream semantic accuracy) are achieved by reducing the regularization loss.
It can be concluded that most of the training process of SSL is to improve the semantic accuracy and clustering of learned representations, rather than the sample-level classification accuracy and clustering. kind.
Essentially, the findings here show that although the direct goal of self-supervised learning is sample-level classification, most of the training time is actually spent on different levels of semantic categories. data clustering. This observation demonstrates the ability of SSL methods to generate semantically meaningful representations through clustering, which also allows us to understand its underlying mechanisms.
Comparison of supervised learning and SSL clustering
Deep network classifiers are often based on the categories of training samples. They are clustered to individual centroids. However, in order for the learned function to truly cluster, this property must still be valid for the test sample; this is the effect we expect, but the effect will be slightly worse.
An interesting question here: to what extent can SSL perform clustering based on the semantic categories of samples compared to clustering by supervised learning? The right panel of Figure 3 reports the NCC training and test accuracy ratio at the end of training for different scenarios (with and without enhanced supervised learning and SSL).
Although the NCC training accuracy of the supervised classifier is 1.0, which is significantly higher than the NCC training accuracy of the SSL-trained model, the NCC test accuracy of the SSL model is slightly higher NCC test accuracy for supervised models. This shows that the clustering behavior of the two models according to semantic categories is similar to a certain extent. Interestingly, using augmented samples to train a supervised model slightly reduces NCC training accuracy, but significantly improves NCC test accuracy.
Exploring the impact of semantic category learning and randomness
Semantic categories define the relationship between the input and the target based on the intrinsic pattern of the input. On the other hand, if you map inputs to random targets, you will see a lack of discernible patterns, which results in the connection between input and target looking arbitrary.
The researchers also explored the impact of randomness on the proficiency of the target required for model learning. To do this, they constructed a series of target systems with varying degrees of randomness and then examined the effect of randomness on the learned representations. They trained a neural network classifier on the same dataset used for classification and then used its target predictions from different epochs as targets with different degrees of randomness. At epoch 0, the network is completely random and gets deterministic but seemingly arbitrary labels. As training proceeds, the randomness of its function decreases, and eventually a target is obtained that is aligned with the ground truth target (which can be considered to be completely non-random). The degree of randomness is normalized here to range from 0 (not at all random, at the end of training) to 1 (completely random, at initialization).
Figure 4 The left figure shows the linear test accuracy for different randomness targets. Each line corresponds to the accuracy of different training stages of SSL with different degrees of randomness. It can be seen that during training, the model will more efficiently capture categories that are closer to the "semantic" target (lower randomness), while showing no significant performance improvement on high-randomness targets.
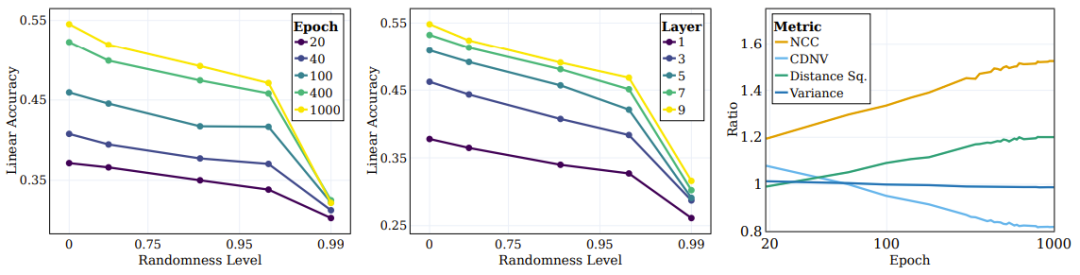
Figure 4: SSL continuously learns semantic targets instead of random targets
#A key issue in deep learning is understanding the role and impact of intermediate layers on classifying different types of categories. For example, will different layers learn different types of categories? Researchers have also explored this issue by evaluating the linear test accuracy of different layers of representations at the end of training at different levels of target randomness. As shown in the middle panel of Figure 4, linear test accuracy continues to improve as randomness decreases, with deeper layers performing better across all category types, and the performance gap becomes larger for classifications close to semantic categories.
The researchers also used several other metrics to evaluate the quality of clustering: NCC accuracy, CDNV, average per-class variance, and average squared distance between class means. To measure how representations improve over training, we calculated the ratio of these metrics for semantic and random targets. The right panel of Figure 4 illustrates these ratios, which show that the representation favors clustering data based on semantic goals rather than random goals. Interestingly, one can see that CDNV (variance divided by squared distance) decreases simply by the decrease in squared distance. The variance ratio is fairly stable during training. This encourages greater spacing between clusters, a phenomenon that has been shown to lead to performance improvements.
Understanding the category hierarchy and intermediate layers
Previous research has demonstrated that in supervised learning, intermediate layers gradually capture features at different levels of abstraction. Initial layers tend toward low-level features, while deeper layers capture more abstract features. Next, the researchers explored whether SSL networks can learn hierarchical attributes at higher levels and which levels are better correlated with these attributes.
In the experiment, they calculated the linear test accuracy at three levels: sample level, original 100 categories, and 20 super categories. The right panel of Figure 2 gives the quantities calculated for these three different sets of categories. It can be observed that during the training process, the performance improvement at the original category and super-category levels is more significant than that at the sample level.
What follows is the behavior of the intermediate layers of SSL-trained models and their ability to capture objectives at different levels. The left and middle panels of Figure 5 give the linear test accuracy on all intermediate layers at different training stages, where the original target and super target are measured. The right panel of Figure 5 gives the ratio between supercategories and original categories.
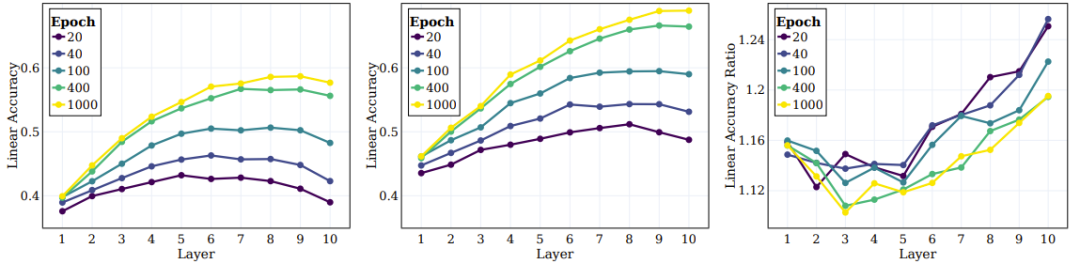
## Figure 5: SSL can be effective in the overall middle layer Learning semantic categories
The researchers reached several conclusions based on these results. First, it can be observed that as the layer goes deeper, the clustering effect will continue to improve. Furthermore, similar to the case of supervised learning, the researchers found that the linear accuracy of each layer of the network improved during SSL training. Notably, they found that the final layer was not the optimal layer for the original class. Some recent SSL research shows that downstream tasks can highly impact the performance of different algorithms. Our work extends this observation and suggests that different parts of the network may be suitable for different downstream tasks and task levels. According to the right panel of Figure 5, it can be seen that in deeper layers of the network, the accuracy of super categories improves more than that of original categories.
The above is the detailed content of New research results from Yann LeCun's team: Reverse engineering of self-supervised learning, it turns out that clustering is implemented like this. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology