
Home >Technology peripherals >AI >2.8 million multimodal command-response pairs, common in eight languages, the first command data set covering video content MIMIC-IT is here
2.8 million multimodal command-response pairs, common in eight languages, the first command data set covering video content MIMIC-IT is here

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-06-13 10:34:271480browse
In recent times, AI dialogue assistants have made considerable progress in language tasks. This significant improvement is not only based on the strong generalization ability of LLM, but also should be attributed to instruction tuning. This involves fine-tuning the LLM on a range of tasks through diverse and high-quality instruction.
One potential reason for achieving zero-shot performance with instruction tuning is that it internalizes context. This is important especially when user input skips common sense context. By incorporating instruction tuning, LLM gains a high level of understanding of user intent and exhibits better zero-shot capabilities even in previously unseen tasks.
However, an ideal AI conversational assistant should be able to solve tasks involving multiple modalities. This requires obtaining a diverse and high-quality multimodal instruction following dataset. For example, the LLaVAInstruct-150K dataset (also known as LLaVA) is a commonly used visual-verbal instruction following dataset, which uses COCO images, instructions and responses based on image captions and target bounding boxes obtained from GPT-4 Constructed. However, LLaVA-Instruct-150K has three limitations: limited visual diversity; using pictures as single visual data; and contextual information only containing language morphology.
In order to promote AI dialogue assistants to break through these limitations, scholars from Nanyang Technological University in Singapore and Microsoft Research Institute in Redmond proposed the multi-modal contextual instruction tuning data set MIMIC-IT , a dataset containing 2.8 million multimodal context instruction-response pairs, covering a variety of real-life scenarios.

Paper address: https://arxiv.org/pdf/2306.05425.pdf
In addition, in order to efficiently generate instruction-response pairs, the researchers also introduced "Sythus", an automated pipeline of instruction-response annotations inspired by the self-instruct method. Sythus uses system information, visual annotations, and examples in context to guide a language model (GPT-4 or ChatGPT) to generate command-response pairs based on visual context, targeting the three fundamental capabilities of visual language models: perception, reasoning, and planning. Additionally, English commands and responses are translated into seven languages to support multilingual use.
It is particularly noteworthy that the researchers trained the multi-modal model "Otter" based on OpenFlamingo on MIMIC-IT. Evaluated on both ChatGPT and humans, Otter's multimodal capabilities surpass other recent visual-language models.
In a series of demos, researchers demonstrated Otter's multi-modal question and answer capabilities:
Q: Which card will be played next? ?
A: Eight tubes. This way you can keep fours and fives waiting for a straight.

Q: I want to land, what should I do?
A: Press the lower left button once to turn left, and pull the handbrake on the right when you want to land.

Q: What next?
A: Pass the ball to the center, run to the goal, and look for scoring opportunities.

Next, let’s look at the study details.
MIMIC-IT Dataset
The MIMIC-IT dataset includes 2.8 million multimodal instruction-response pairs, covering basic capabilities: perception, reasoning, and planning. Each instruction is accompanied by a multimodal conversational context, enabling VLM trained on MIMIC-IT to demonstrate good proficiency in interactive instructions and perform zero-shot generalization.
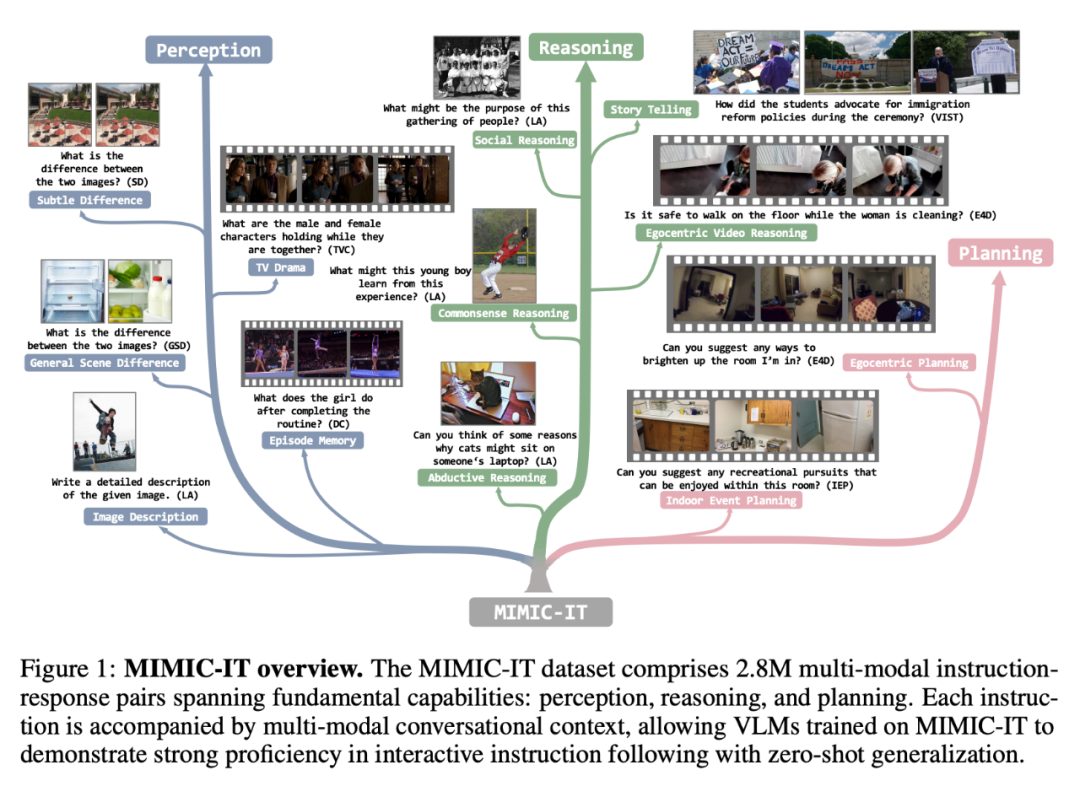
## Compared with LLaVA, the features of MIMIC-IT include:
(1) Diverse visual scenes, including images and videos from different data sets such as general scenes, egocentric perspective scenes and indoor RGB-D images;
(2) More An image (or a video) as visual data;
(3) Multi-modal context information, including multiple command-response pairs and multiple images or videos;
(4) Supports eight languages, including English, Chinese, Spanish, Japanese, French, German, Korean and Arabic.
The following figure further shows the command-response comparison of the two (the yellow box is LLaVA):

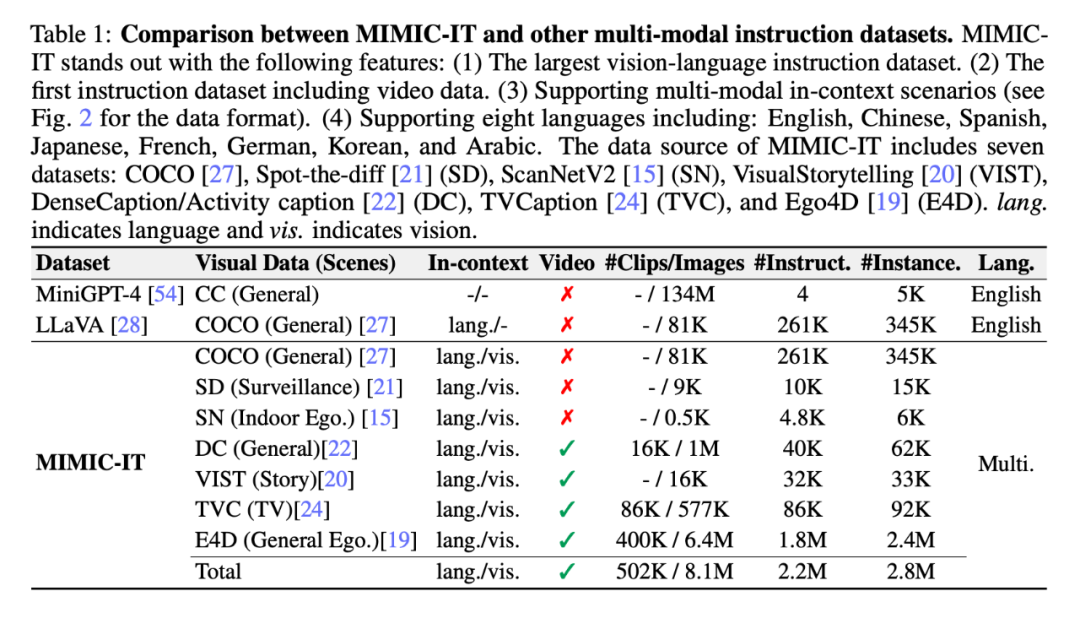
As shown in Table 1, the data sources of MIMIC-IT come from seven data sets: COCO, Spot-the-diff (SD), ScanNetV2 (SN), VisualStorytelling (VIST), DenseCaption /Activity caption (DC), TVCaption (TVC) and Ego4D (E4D). "lang." in the "Context" column represents language, and "vis." represents vision.
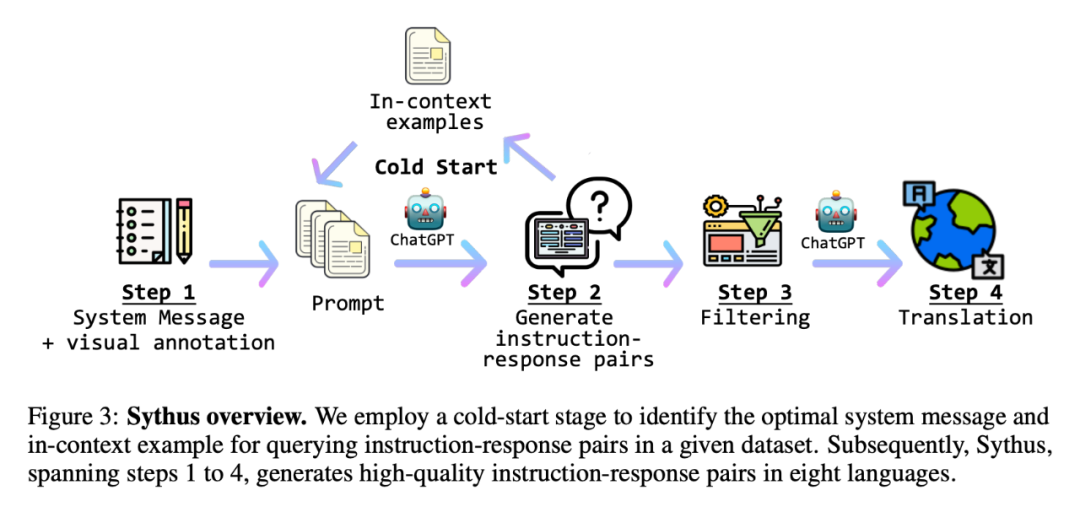
 Sythus: Automated command-response pair generation pipeline
Sythus: Automated command-response pair generation pipeline
At the same time, the researcher proposed Sythus (Figure 3), which is An automated pipeline for generating high-quality command-response pairs in multiple languages. Based on the framework proposed by LLaVA, researchers used ChatGPT to generate command-response pairs based on visual content. To ensure the quality of the generated command-response pairs, the pipeline uses system information, visual annotations, and samples in context as prompts for ChatGPT. System information defines the expected tone and style of the generated command-response pairs, while visual annotations provide basic image information such as bounding boxes and image descriptions. Examples in context help ChatGPT learn in context.
Since the quality of the core set will affect the subsequent data collection process, the researchers adopted a cold start strategy to strengthen the samples in context before large-scale querying. During the cold start phase, a heuristic approach is adopted to prompt ChatGPT to collect samples in context only through system information and visual annotations. This phase ends only after the samples in a satisfactory context have been identified. In the fourth step, once the command-response pairs are obtained, the pipeline expands them into Chinese (zh), Japanese (ja), Spanish (es), German (de), French (fr), Korean (ko) and Arabic (ar). Further details can be found in Appendix C, and specific task prompts can be found in Appendix D.
The researchers then demonstrated various applications and the potential capabilities of visual language models (VLMs) trained on them. First, the researchers introduced Otter, a contextual instruction tuning model developed using the MIMIC-IT dataset. The researchers then explored various methods of training Otter on the MIMIC-IT dataset and discussed the many scenarios in which Otter can be used effectively.
Figure 5 is an example of Otter’s response in different scenarios. Thanks to training on the MIMIC-IT dataset, Otter is capable of serving situational understanding and reasoning, contextual sample learning, and egocentric visual assistants.

Finally, the researchers conducted a comparative analysis of the performance of Otter and other VLMs in a series of benchmark tests.
ChatGPT Evaluation
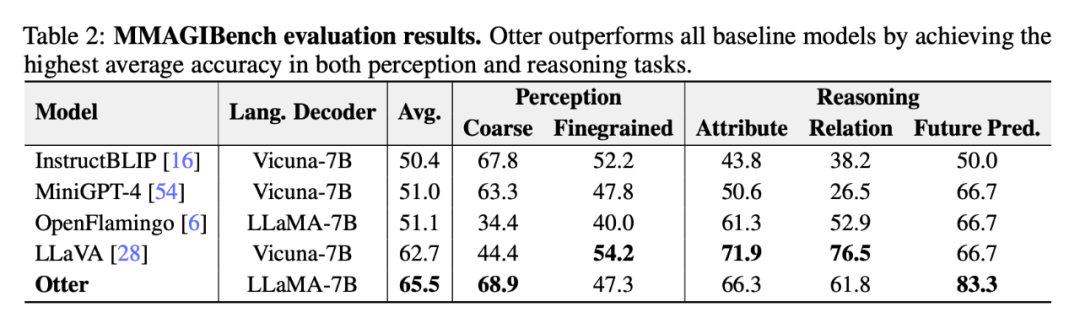
Table 2 below shows the researcher’s evaluation of the visual language model using the MMAGIBench framework [43] Perception and reasoning abilities are broadly assessed.
##Human Assessment
Multi-Modality Arena [32] uses the Elo rating system to evaluate the usefulness and consistency of VLM responses. Figure 6(b) shows that Otter demonstrates superior practicality and consistency, achieving the highest Elo rating in recent VLMs.
Few-shot contextual learning benchmark evaluation
Otter is fine-tuned based on OpenFlamingo, a multi-model An architecture designed for dynamic context learning. After fine-tuning using the MIMIC-IT dataset, Otter significantly outperforms OpenFlamingo on the COCO Captioning (CIDEr) [27] few-shot evaluation (see Figure 6 (c)). As expected, fine-tuning also brings marginal performance gains on zero-sample evaluation.

Figure 6: Evaluation of ChatGPT video understanding.
DiscussFlaws. Although researchers have iteratively improved system messages and command-response examples, ChatGPT is prone to language hallucinations, so it may generate erroneous responses. Often, more reliable language models require self-instruct data generation.
Future jobs. In the future, the researchers plan to support more specific AI datasets, such as LanguageTable and SayCan. Researchers are also considering using more trustworthy language models or generation techniques to improve the instruction set.
The above is the detailed content of 2.8 million multimodal command-response pairs, common in eight languages, the first command data set covering video content MIMIC-IT is here. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology