
Home >Technology peripherals >AI >DeepMind rewrites the sorting algorithm with AI; crams 33B large model into a single consumer GPU
DeepMind rewrites the sorting algorithm with AI; crams 33B large model into a single consumer GPU

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-06-12 18:49:571525browse
Directory:
- #Faster sorting algorithms discovered using deep reinforcement learning
- Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding ##Patch-based 3D Natural Scene Generation from a Single Example
- Spatio-temporal Diffusion Point Processes
- SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
- UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Paper 1: Faster sorting algorithms discovered using deep reinforcement learning
- ##Author: Daniel J. Mankowitz et al
- Paper address: https://www.nature.com/articles/s41586-023-06004-9
"By swapping and copy-moving, AlphaDev skips a step and connects projects in a way that seems wrong but is actually a shortcut." This former Unprecedented and counterintuitive thoughts remind people of the spring of 2016. Seven years ago, AlphaGo defeated the human world champion at Go, and now AI has taught us another lesson in programming. Two sentences from Google DeepMind CEO Hassabis set off the computer field: "AlphaDev discovered a new and faster sorting algorithm, and we have open sourced it into the main C library for developers to use. This is just AI improving code efficiency. The beginning of progress."
AI rewrites the sorting algorithm, 70% faster :DeepMind AlphaDev innovates the basis of computing, and the library called trillions of times every day is updated
Paper 2: Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
- Author: Hang Zhang et al
- Paper address: https:/ /arxiv.org/abs/2306.02858
Recently, large language models have demonstrated impressive capabilities. Can we equip large models with “eyes” and “ears” so that they can understand videos and interact with users? Starting from this problem, researchers from DAMO Academy proposed Video-LLaMA, a large model with comprehensive audio-visual capabilities. Video-LLaMA can perceive and understand video and audio signals in videos, and can understand user input instructions to complete a series of complex tasks based on audio and video, such as audio/video description, writing, question and answer, etc. Currently, papers, codes, and interactive demos are all open. In addition, on the Video-LLaMA project homepage, the research team also provides a Chinese version of the model to make the experience of Chinese users smoother.
The following two examples demonstrate the comprehensive audio-visual perception capabilities of Video-LLaMA. The conversations in the examples revolve around audio videos.
 Recommendation:
Recommendation:
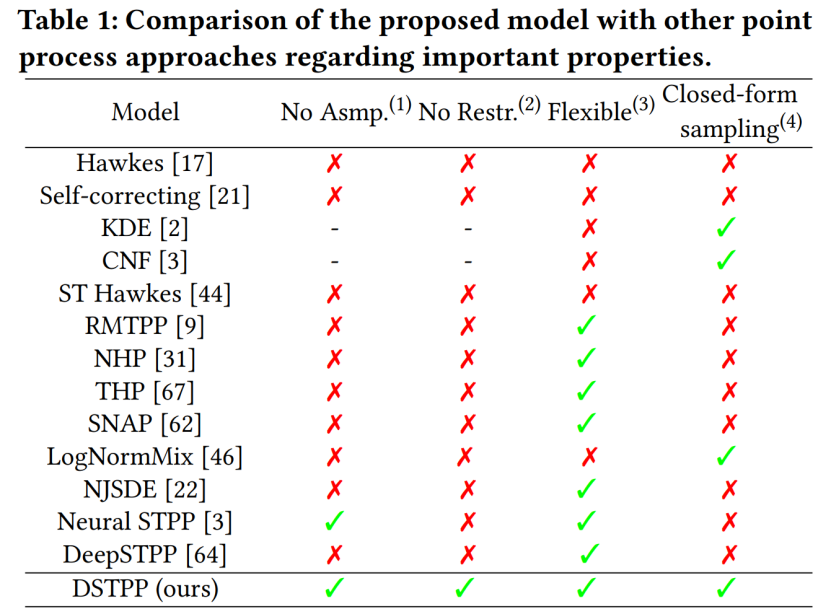
Abstract: Peking University’s Chen Baoquan team, together with researchers from Shandong University and Tencent AI Lab, proposed the first single-sample scenario without A method that can generate a variety of high-quality 3D scenes through training. Recommended: CVPR 2023 | 3D scene generation: Generate diverse results from a single sample without any neural network training. Paper 4: Spatio-temporal Diffusion Point Processes Abstract:The Urban Science and Computing Research Center of the Department of Electronic Engineering of Tsinghua University recently proposed a spatiotemporal diffusion point process, which breaks through the limitations of existing methods such as restricted probabilistic forms and high sampling costs for modeling spatiotemporal point processes, and achieves a flexible, The efficient and easy-to-compute spatio-temporal point process model can be widely used in the modeling and prediction of spatio-temporal events such as urban natural disasters, emergencies, and resident activities, and promotes the intelligent development of urban planning and management. The table below demonstrates the advantages of DSTPP over existing point-process solutions. Recommendation: Can the diffusion model predict earthquakes and crime? The latest research by the Tsinghua team proposes a space-time diffusion point process. Paper 5: SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression Abstract: In order to solve the accuracy problem, researchers from the University of Washington, ETH Zurich and other institutions proposed a new compression format and quantization technology SpQR ( Sparse - quantized representation), achieving near-lossless compression of LLM across model scales for the first time, while achieving similar compression levels to previous methods. SpQR works by identifying and isolating anomalous weights that cause particularly large quantization errors, storing them with higher precision while compressing all other weights. To position 3-4, less than 1% perplexity relative accuracy loss is achieved in LLaMA and Falcon LLMs. Run a 33B parameter LLM on a single 24GB consumer GPU without any performance degradation while being 15% faster. Figure 3 below shows the overall architecture of SpQR.

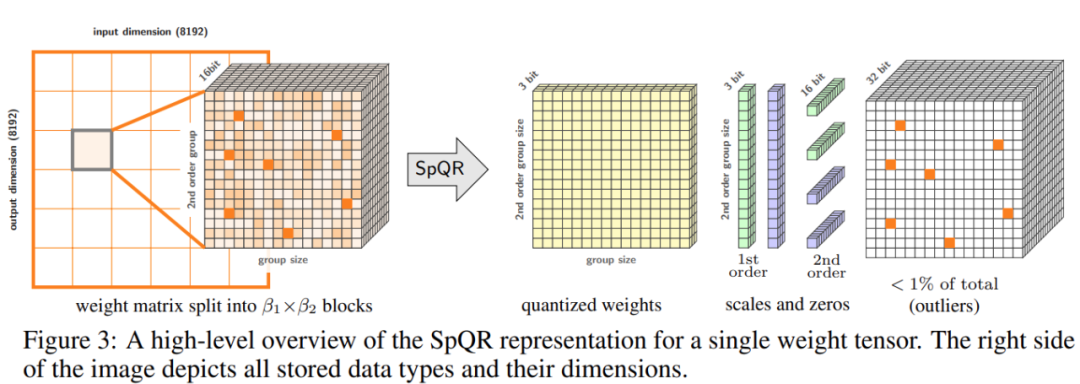
Recommendation: "Put a 33 billion parameter large model into a single consumer-grade GPU, 15% acceleration without loss of performance.
Paper 6: UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild
- Author: Can Qin et al
- Paper address: https://arxiv.org/abs/2305.11147
Abstract: In this article, researchers from Salesforce AI, Northeastern University, and Stanford University proposed MOE-style Adapter and Task-aware HyperNet To realize the multi-modal condition generation capability in UniControl. UniControl is trained on nine different C2I tasks, demonstrating strong visual generation capabilities and zero-shot generalization capabilities. The UniControl model consists of multiple pre-training tasks and zero-shot tasks.

Recommended: A unified model for multi-modal controllable image generation is here, and the model parameters and inference code are all open source.
Paper 7: FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
- Author: Lingjiao Chen et al
- Paper address: https://arxiv.org/pdf/2305.05176.pdf
Abstract: The balance between cost and accuracy is a key factor in decision-making, especially when adopting new technologies. How to effectively and efficiently utilize LLM is a key challenge for practitioners: if the task is relatively simple, then aggregating multiple responses from GPT-J (which is 30 times smaller than GPT-3) can achieve similar performance to GPT-3 , thereby achieving a cost and environmental trade-off. However, on more difficult tasks, GPT-J's performance may degrade significantly. Therefore, new approaches are needed to use LLM cost-effectively.
A recent study attempted to propose a solution to this cost problem. The researchers experimentally showed that FrugalGPT can compete with the performance of the best individual LLM (such as GPT-4) , the cost is reduced by up to 98%, or the accuracy of the best individual LLM is improved by 4% at the same cost. This study discusses three cost reduction strategies, namely prompt adaptation, LLM approximation, and LLM cascading.
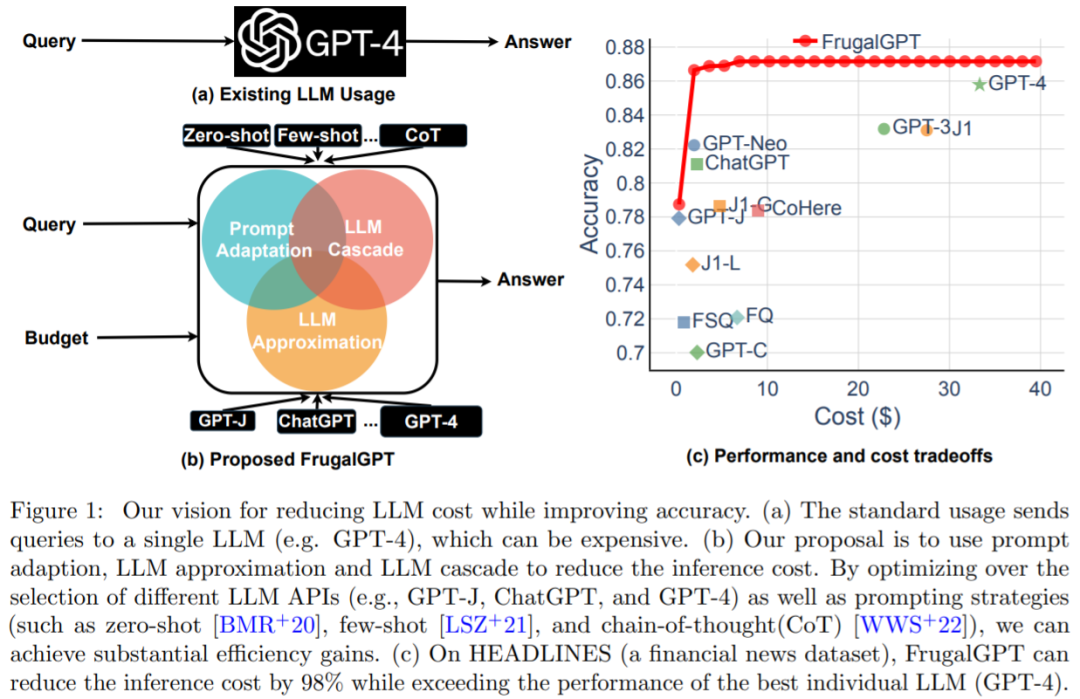
Recommended: GPT-4 API replacement? The performance is comparable and the cost is reduced by 98%. Stanford proposed FrugalGPT, but the research was controversial.
The above is the detailed content of DeepMind rewrites the sorting algorithm with AI; crams 33B large model into a single consumer GPU. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology