
Home >Technology peripherals >AI >The iPhone takes two seconds to produce a picture, and the fastest known mobile Stable Diffusion model is here.
The iPhone takes two seconds to produce a picture, and the fastest known mobile Stable Diffusion model is here.

- 王林forward
- 2023-06-12 11:15:481453browse
Stable Diffusion (SD) is currently the most popular text to image (text to image) generation diffusion model. Although its powerful image generation capabilities are shocking, an obvious shortcoming is that it requires huge computing resources and the inference speed is very slow: taking SD-v1.5 as an example, even using half-precision storage, its model size is 1.7GB. With 1 billion parameters, the on-device inference time is often close to 2 minutes.
In order to solve the problem of inference speed, academia and industry have begun research on SD acceleration, mainly focusing on two routes: (1) reducing the number of inference steps, this route can Divided into two sub-routes, one is to reduce the number of steps by proposing a better noise scheduler, representative works are DDIM [1], PNDM [2], DPM [3], etc.; the second is to reduce the number of steps through progressive distillation (Progressive Distillation) The number of steps, representative works are Progressive Distillation [4] and w-conditioning [5], etc. (2) Engineering skills optimization. The representative work is that Qualcomm uses int8 quantified full-stack optimization to achieve SD-v1.5 on Android phones in 15 seconds [6], and Google uses on-end GPU optimization to achieve SD-v1.4 on Samsung phones. Accelerate to 12s [7].
While these efforts have come a long way, it’s still not happening fast enough.
Recently, Snap Research Institute launched the latest high-performance Stable Diffusion model. Through comprehensive optimization of the network structure, training process, and loss function, it can produce images in 2 seconds on iPhone 14 Pro. (512x512), and achieves a better CLIP score than SD-v1.5. This is the fastest known end-to-end Stable Diffusion model!

- Paper address: https://arxiv.org/pdf/2306.00980.pdf
- Webpage: https://snap-research.github.io/SnapFusion
Core Method
The Stable Diffusion model is divided into three parts: VAE encoder/decoder, text encoder, and UNet. Among them, UNet accounts for the absolute majority in terms of parameter amount and calculation amount, so SnapFusion mainly optimizes UNet. . It is divided into two parts: (1) Optimization of the UNet structure: By analyzing the speed bottleneck of the original UNet, this article proposes a set of automatic evaluation and evolution processes for the UNet structure, and obtains a more efficient UNet structure (called Efficient UNet) . (2) Optimization of the number of inference steps: As we all know, the diffusion model is an iterative denoising process during inference. The more iteration steps, the higher the quality of the generated images, but the time cost also increases linearly with the number of iteration steps. . In order to reduce the number of steps and maintain image quality, we propose a CFG-aware distillation loss function that explicitly considers the role of CFG (Classifier-Free Guidance) during the training process. This loss function is proven to be the key to improving CLIP score!
The following table is an overview comparison between SD-v1.5 and SnapFusion models. It can be seen that the speed improvement comes from the two parts of UNet and VAE decoder, and the UNet part is the big one. There are two aspects to the improvement of the UNet part. One is the reduction of single latency (1700ms -> 230ms, 7.4x acceleration), which is obtained through the proposed Efficient UNet structure; the other is the reduction of Inference steps (50 -> 8, 6.25 x acceleration), which is obtained through the proposed CFG-aware Distillation. VAE decoder is accelerated through structured pruning.

The following focuses on the design of Efficient UNet and the design of CFG-aware Distillation loss function.
(1) Efficient UNet
We locate the speed by analyzing the Cross-Attention and ResNet modules in UNet The bottleneck lies in the Cross-Attention module (especially the Cross-Attention in the first Downsample stage), as shown in the figure below. The root cause of this problem is that the complexity of the attention module has a square relationship with the spatial size of the feature map. In the first Downsample stage, the spatial size of the feature map is still large, resulting in high computational complexity.
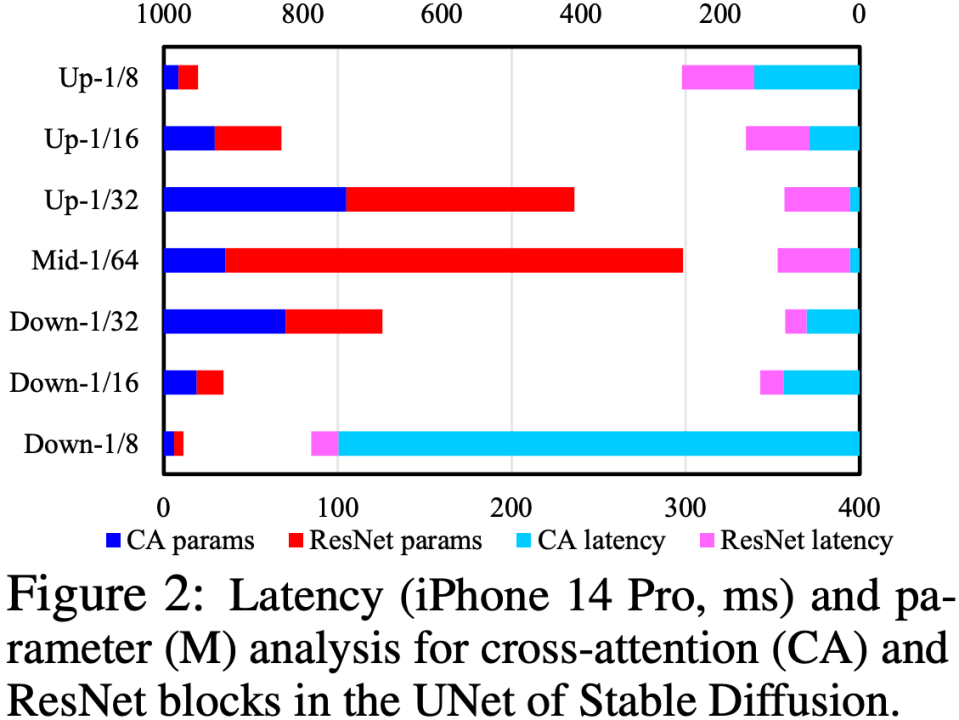
In order to optimize the UNet structure, we propose a set of UNet structure automatic evaluation and evolution processes: first conduct robust training (Robust Training) on UNet, and randomly drop some modules during training to test each The real impact of each module on performance is constructed to construct a lookup table of "impact on CLIP score vs. latency"; and then based on the lookup table, priority is given to removing modules that have little impact on CLIP score and are very time-consuming. This set of processes is performed automatically online. After completion, we will get a brand new UNet structure called Efficient UNet. Compared with the original UNet, it achieves 7.4x acceleration without performance degradation.
(2) CFG-aware Step Distillation
CFG (Classifier-Free Guidance) is the SD inference stage Essential skills that can greatly improve picture quality, very crucial! Although there have been works on the diffusion model using step distillation to accelerate [4], they did not include CFG as an optimization goal in distillation training. That is to say, the distillation loss function does not know that CFG will be used later. According to our observation, this will seriously affect the CLIP score when the number of steps is small.
In order to solve this problem, we propose to let both the teacher and student models perform CFG before calculating the distillation loss function, so that the loss function is calculated on the features after CFG, thus The effects of different CFG scales are explicitly considered. In the experiment, we found that although the CLIP score can be improved by completely using CFG-aware Distillation, the FID also becomes significantly worse. We then proposed a random sampling scheme to mix the original Step Distillation loss function and the CFG-aware Distillation loss function, achieving the coexistence of the advantages of the two, which not only significantly improved the CLIP score, but also did not worsen the FID. This step achieves an acceleration of 6.25 times in the further inference stage, achieving a total acceleration of approximately 46 times.
In addition to the above two main contributions, the article also includes the pruning acceleration of VAE decoder and the careful design of the distillation process. Please refer to the paper for specific content.
Experimental results
SnapFusion benchmarks SD-v1.5 text to image function, the goal is to significantly reduce inference time and maintain image quality without degradation, which best illustrates This is shown in the figure below:
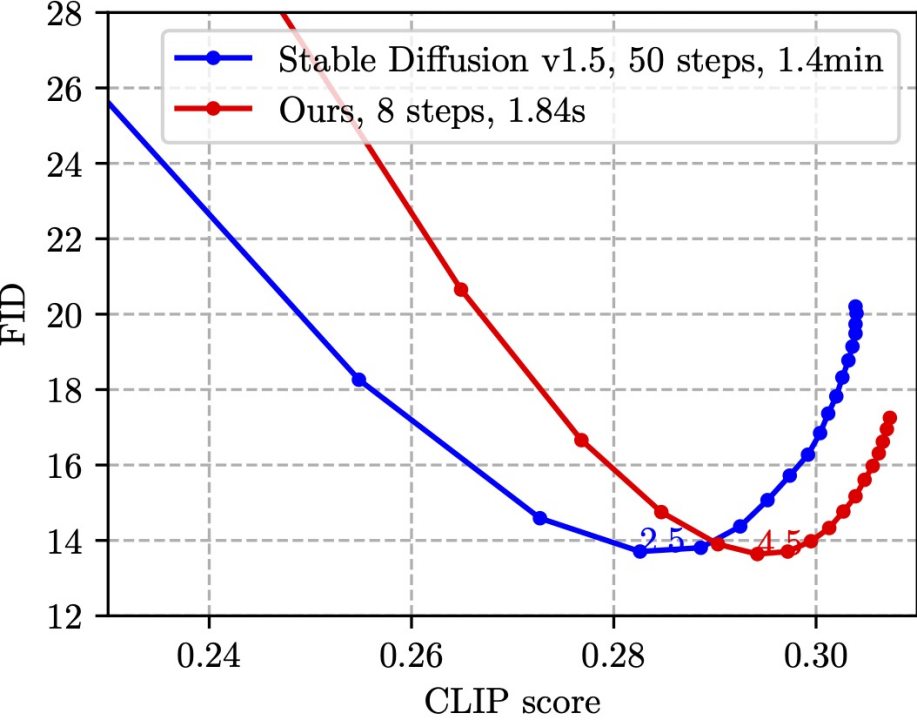
This figure randomly selects 30K caption-image pairs on the MS COCO'14 verification set to calculate the CLIP score and FID. CLIP score measures the semantic consistency between pictures and text, the bigger the better; FID measures the distribution distance between generated pictures and real pictures (generally considered a measure of the diversity of generated pictures), the smaller the better. Different points in the graph are obtained using different CFG scales, and each CFG scale corresponds to a data point. As can be seen from the figure, our method (red line) can achieve the same lowest FID as SD-v1.5 (blue line), and at the same time, the CLIP score of our method is better. It is worth noting that SD-v1.5 takes 1.4min to generate an image, while SnapFusion only takes 1.84s. This is also the fastest mobile Stable Diffusion model we know of!
Here are some samples generated by SnapFusion:

More samples Please refer to the article appendix.
In addition to these main results, the article also shows numerous ablation analysis (Ablation Study) experiments, hoping to provide reference experience for the development of efficient SD models:
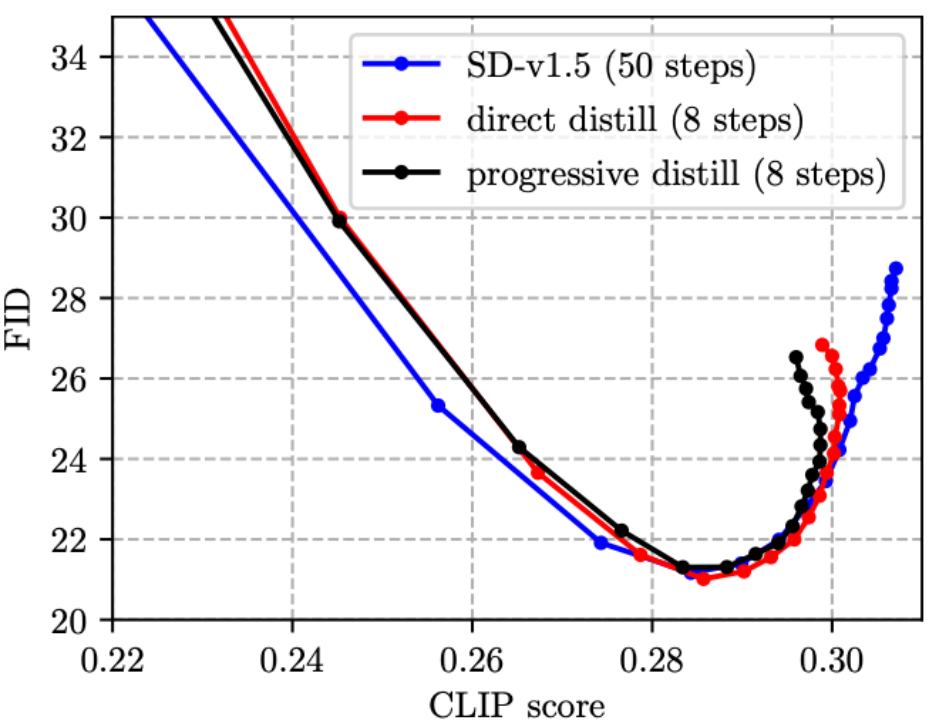
(1) Previous work on Step Distillation usually used progressive schemes [4, 5], but we found that progressive distillation has no advantages over direct distillation on the SD model, and the process is cumbersome, so we The direct distillation scheme is used in this article.
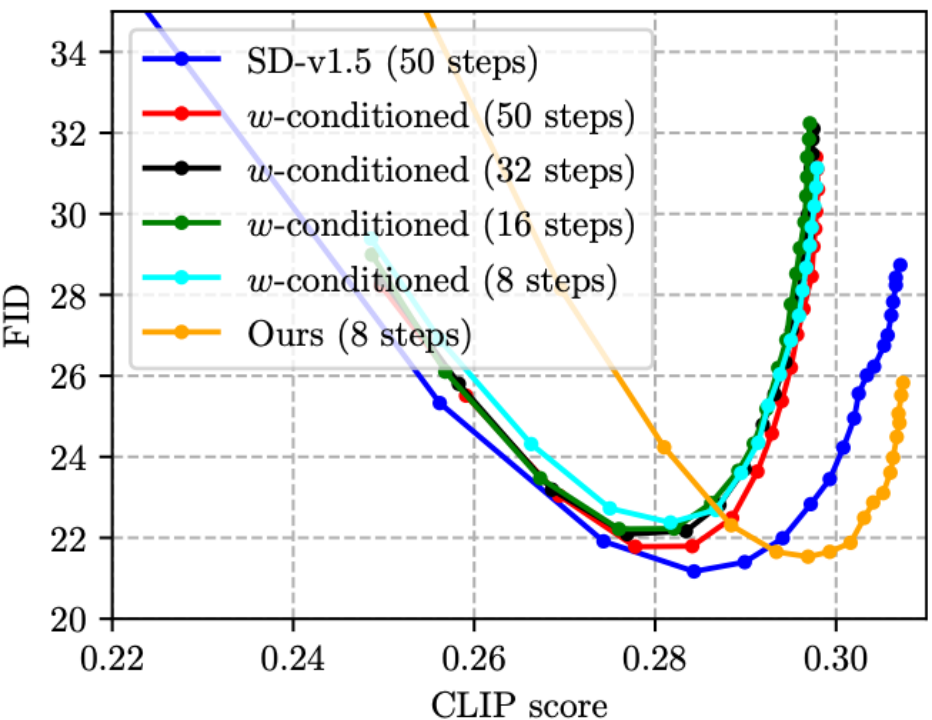
(2) Although CFG can greatly improve image quality, the cost is doubling the inference cost. This year's CVPR'23 Award Candidate's On Distillation article [5] proposed w-conditioning, which uses CFG parameters as input to UNet for distillation (the resulting model is called w-conditioned UNet), thereby eliminating the CFG step during reasoning and realizing reasoning costs. Halved. However, we found that doing so will actually cause the image quality to decrease and the CLIP score to decrease (as shown in the figure below, the CLIP score of the four w-conditioned lines does not exceed 0.30, which is worse than SD-v1.5). Our method can reduce the number of steps and improve the CLIP score at the same time, thanks to the proposed CFG-aware distillation loss function! What is particularly noteworthy is that the inference cost of the green line (w-conditioned, 16 steps) and the orange line (Ours, 8 steps) in the figure below are the same, but the orange line is obviously better, indicating that our technical route is better than w-conditioned conditioning [5] is more effective on the distilled CFG guided SD model.
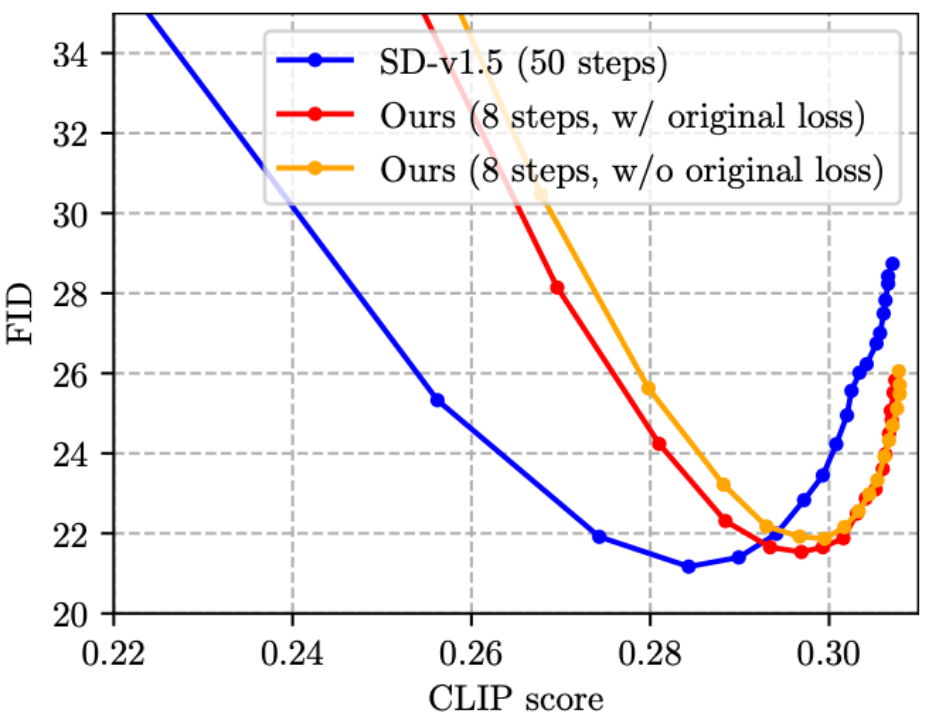
(3) The existing work on Step Distillation [4, 5] did not combine the original loss function and distillation The loss functions are added together. Friends who are familiar with image classification knowledge distillation should know that this design is intuitively suboptimal. So we proposed to add the original loss function to the training, as shown in the figure below, which is indeed effective (slightly reducing FID).
Summary and future work
This paper proposes SnapFusion, a high-performance Stable Diffusion model for mobile terminals . SnapFusion has two core contributions: (1) Through layer-by-layer analysis of the existing UNet, it locates the speed bottleneck and proposes a new efficient UNet structure (Efficient UNet), which can effectively replace the UNet in the original Stable Diffusion and achieve 7.4 x acceleration; (2) Optimize the number of iteration steps in the inference phase and propose a new step distillation scheme (CFG-aware Step Distillation), which can significantly improve the CLIP score while reducing the number of steps, achieving 6.25x acceleration. Overall, SnapFusion achieves image output within 2 seconds on iPhone 14 Pro, which is currently the fastest known mobile Stable Diffusion model.
Future work:
1. The SD model can be used in a variety of image generation scenarios. This article is limited to Due to time constraints, we are currently only focusing on the core task of text to image, and other tasks (such as inpainting, ControlNet, etc.) will be followed later.
2. This article mainly focuses on speed improvement and does not optimize model storage. We believe that the proposed Efficient UNet still has room for compression. Combined with other high-performance optimization methods (such as pruning, quantization), it is expected to shrink storage and reduce the time to less than 1 second, making real-time SD on the off-end a step further.
The above is the detailed content of The iPhone takes two seconds to produce a picture, and the fastest known mobile Stable Diffusion model is here.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology