
 Technology peripheralsAINetEase Yidun AI Lab paper selected for ICASSP 2023! Black technology makes speech recognition more 'listening' and more accurate
Technology peripheralsAINetEase Yidun AI Lab paper selected for ICASSP 2023! Black technology makes speech recognition more 'listening' and more accurate
2023-06-07 17:42:41 Author: Li Wenwen
Every science fiction fan longs for the future to be able to launch an interstellar spaceship and conquer the stars and sea with just a few words, just like talking to an old friend; or to have Iron Man’s artificial intelligence butler Jarvis, who can make a Come up with a set of nano battle armor. In fact, this picture is not far away from us - it is as close to us as Siri in the iPhone. Behind it is Automatic Speech Recognition technology. This key technology can convert speech into text or commands that can be recognized by computers, achieving a convenient, efficient, and intelligent human-computer interaction experience.
With the development of AI technologies such as deep learning, speech recognition technology has made tremendous progress - not only the recognition accuracy has been greatly improved, but also it can better handle issues such as accents, noise and background sounds. However, as technology continues to be applied in life and business, it will still encounter some bottlenecks. After all, there are too many practical factors to consider from theoretical research to practical applications, from papers to products. How to make speech recognition better assist content review? How can the recognition action itself be like the human brain, based on the understanding of the context, and give more accurate answers at a lower cost? Yidun AI Lab, a subsidiary of NetEase Intelligence, has given a new approach.
Yidun comes out with black technology again, and smart companies are heading towards the world!
Recently, the global speech and acoustics conference ICASSP 2023 announced the list of selected papers, and the paper submitted by Yidun AI Lab, a subsidiary of NetEase Intelligence Enterprise, was successfully accepted. This year is the 48th ICASSP conference, and it is also the first offline conference after the epidemic. Although the conference officials have not announced the final number of papers accepted, the number of papers submitted has increased by 50% compared to previous years, reaching an astonishing 6,000 .
Faced with such fierce competition, the NetEase Zhiqi Yidun AILab team relied on a paper on speech recognition "Improving CTC-based ASRModels with Gated Interplayer Collaboration (CTC-based model improvement to achieve a stronger model)" Structure)》 stood out and successfully got tickets to attend the offline conference in Rhodes Island, Greece.
“GIC”, helps speech recognition go further
Speech recognition is essentially the conversion of speech sequences into text sequences. To complete such a conversion, generally use three types of models, CTC, Attention-based and RNN-Transducer, they are completing Different paths were used during the task:
CTC: Based on the neural network model, the model parameters are updated through backpropagation during the training process to minimize the loss function. This algorithm introduces "whitespace characters" to represent meaningless characters or space symbols. CTC is suitable for processing data with large differences in input and output lengths, such as mapping acoustic features to text in speech recognition;
Attention-based: The attention mechanism is also based on the neural network model and uses a technology called "attention" to weight the input. At each time step, the model calculates a distributed weight vector based on the current state and all inputs, and applies it to all inputs to produce a weighted average as the output. This method can make the model better focus on some information related to the current prediction;
RNN-Transducer: Transcriptor, this algorithm combines the encoder-decoder framework and autoregressive modeling ideas, and considers the interaction between the source language sentences and the generated partial target language sentences when generating the target sequence. Unlike the other two methods, RNN-Transducer does not clearly distinguish between the encoder and decoder stages, and converts directly from source language to target language, so it can simultaneously consider between source language sentences and generated partial target language sentences. interaction.
Compared with the latter two, although CTC has natural non-autoregressive decoding properties, the decoding speed is relatively faster, but it still has performance disadvantages:
1. The CTC algorithm sets the conditional independence assumption, that is, CTC assumes that the outputs of each time step are independent. This is not reasonable for speech recognition tasks. If the pronunciation "ji rou" is pronounced, the predicted text content should be different in different contexts. If the above sentence is "I like to eat", the probability of "chicken" should be higher. Similarly, if the sentence above is "He has arms", the probability of "muscle" should be higher. If you pass CTC training, it is easy to output funny text like "I like to eat muscles" while ignoring the above;
2. From a modeling perspective, the Attention-based model and the RNN-Transducer model predict the output of the current time step based on the input and the output of the previous time step, while the CTC model only uses the input to predict the current output. During the modeling process of the CTC model, text information is only passed back to the network as a supervision signal, and does not serve as an input to the network to explicitly promote the prediction of the model.
We hope to solve the above two disadvantages as much as possible while retaining the CTC decoding efficiency. Therefore, we want to start from the CTC model itself and design a lightweight module to introduce text information to the CTC-based model, so that the model can integrate acoustic and text information, learn the interaction between text sequence context, and alleviate Conditional independence assumption of CTC algorithm. But in the process, we encountered two problems: How to inject text information into the CTC model (Encoder CTC structure)? How to adaptively fuse text features and acoustic features?
In order to achieve the above goals, We designed the Gated Interlayer Collaboration (abbreviated as GIC) mechanism. The GIC module mainly includes an embedding layer and a gate unit. Among them, the embedding layer is used to generate text information for each audio input frame, and the gating unit is used to adaptively fuse text information and acoustic information.
Specifically, our method is based on the multi-task learning (Multi-taskLearning) framework, using the output of the middle layer of the encoder module (Encoder) to calculate the auxiliary CTC loss. The objective function of the entire network is the CTC loss of the last layer and the middle layer. Weighted sum of layer-assisted CTC losses. GIC uses the prediction of the middle layer of the network, that is, the probability distribution of the Softmax output, as the soft label of each frame, and the sum of the dot product embedding layer matrices as the text representation of each frame. Finally, the generated text representation and acoustic representation are adaptively fused through a gate control unit and become a new feature input to the next layer. The new features at this time combine text features and acoustic features, allowing the next-level Encoder module to learn acoustic sequence context information and text sequence context information. The framework of the entire model is shown in the figure below:
Experiments on the Conformer and Transformer models show:
1. GIC Supports scene recognition in both Chinese and English, and has achieved significant performance improvements in accuracy;
2. The performance of the GIC model exceeds the Attention-based and RNN-transducer models of the same parameter scale, and has the advantage of non-autoregressive decoding, brings several times the decoding speed improvement;
3. Compared with the original CTC model, GIC has a relative performance improvement of far more than 10% in multiple open source data sets.
Conformer Conclusion under the model
Transformer Conclusion under the model
GIC brings great improvements to the performance of CTC models. Compared with the original CTC model, the GIC module brings approximately 2M additional parameters. Among them, the linear layer used to calculate the auxiliary CTC loss of the middle layer is shared with the last layer and does not bring additional parameters. Multiple middle layers share the embedding layer, bringing 256*5000 parameters which is approximately equal to 1.3M. In addition, the amount of additional parameters required for multiple control gate units is 256*256*2*k, totaling about 0.6M.
Leading technology creates advanced business
The GIC in the paper has been applied in the content review business of NetEase Yidun.
As a one-stop digital content risk control brand under NetEase Intelligence, Yidun has long been focused on technology research and development and innovation in digital content security risk control and anti-spam information. Among them, for digital content that uses sound as a carrier, Yidun provides a variety of audio content audit engines, including various types of audio content such as songs, radio, TV programs, live broadcasts, etc., to promptly detect and filter content that contains sensitive, illegal, and vulgar content. Advertising content voice, thereby reducing the social impact of bad content and creating a good network environment.
For audio with specific semantic content, Yidun uses speech recognition technology to transcribe the speech content in the audio file into text content, and then uses the detection module to analyze and process the text, thereby realizing automated review and filtering of the audio content. Therefore, the accuracy of speech recognition is closely related to the efficiency and accuracy of audio content review, and will directly affect the safety and stability of customers' business operations.
The application of GIC in content review in the paper has achieved significant improvement. In the actual application process, there are two hyperparameters that need to be debugged, namely the multi-task learning coefficient lambda and the number of intermediate layers k. In the 18-layer encoder structure, we found that k=5 and lambda=0.5 have better experimental results. We then start with this setting and fine-tune it to determine the optimal hyperparameters.
?
Hero behind the scenes: NetEase Zhiqi Yidun AI Lab
This is not the first time that the Yidun AI Lab team has received such an honor.
As a technical team under NetEase Intelligent Enterprise that has always been at the forefront of artificial intelligence research, Yidun AI Lab is committed to building comprehensive, rigorous, safe and trustworthy AI technical capabilities around refinement, lightweighting, and agility, and continuously improving Digital content risk control service level. Prior to this, the team had won multiple AI algorithm competition championships and important awards:
The First China Artificial Intelligence Competition in 2019 The most advanced A-level certificate in the flag recognition track
The Second China Artificial Intelligence Competition in 2020 The most advanced A-level certificate in the video deep forgery detection track
The 3rd China Artificial Intelligence Competition in 2021 The two most advanced A-level certificates for video deep forgery detection and audio deep forgery detection tracks
2021 "Innovation Star" and "Innovative Figure" of China Artificial Intelligence Industry Development Alliance
2021 The 16th National Human-Computer Speech Communication Academic Conference (NCMMSC2021) "Long and Short Video Multilingual Multimodal Recognition Competition" - Chinese Long and Short Video Live Voice Keyword (VKW) Double Track Champion
Won the first prize of the Science and Technology Progress Award issued by the Zhejiang Provincial Government in 2021
2022 ICPR Multimodal Subtitle Recognition Competition (MSR Competition, the first multi-modal subtitle recognition competition in China) Track Three "Multimodal Subtitle Recognition System that Integrate Vision and Audio" Champion
The future is here, and the time for AI’s iPhone has arrived. Yidun has successfully entered the academic hall of phonetics today, and in the future, technology will bring achievements and progress to all aspects of business, and Yidun will always be by your side.






The above is the detailed content of NetEase Yidun AI Lab paper selected for ICASSP 2023! Black technology makes speech recognition more 'listening' and more accurate. For more information, please follow other related articles on the PHP Chinese website!

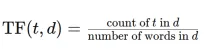 Convert Text Documents to a TF-IDF Matrix with tfidfvectorizerApr 18, 2025 am 10:26 AM
Convert Text Documents to a TF-IDF Matrix with tfidfvectorizerApr 18, 2025 am 10:26 AMThis article explains the Term Frequency-Inverse Document Frequency (TF-IDF) technique, a crucial tool in Natural Language Processing (NLP) for analyzing textual data. TF-IDF surpasses the limitations of basic bag-of-words approaches by weighting te
 Building Smart AI Agents with LangChain: A Practical GuideApr 18, 2025 am 10:18 AM
Building Smart AI Agents with LangChain: A Practical GuideApr 18, 2025 am 10:18 AMUnleash the Power of AI Agents with LangChain: A Beginner's Guide Imagine showing your grandmother the wonders of artificial intelligence by letting her chat with ChatGPT – the excitement on her face as the AI effortlessly engages in conversation! Th
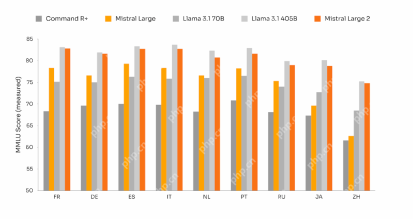 Mistral Large 2: Powerful Enough to Challenge Llama 3.1 405B?Apr 18, 2025 am 10:16 AM
Mistral Large 2: Powerful Enough to Challenge Llama 3.1 405B?Apr 18, 2025 am 10:16 AMMistral Large 2: A Deep Dive into Mistral AI's Powerful Open-Source LLM Meta AI's recent release of the Llama 3.1 family of models was quickly followed by Mistral AI's unveiling of its largest model to date: Mistral Large 2. This 123-billion paramet
 What is Noise Schedules in Stable Diffusion? - Analytics VidhyaApr 18, 2025 am 10:15 AM
What is Noise Schedules in Stable Diffusion? - Analytics VidhyaApr 18, 2025 am 10:15 AMUnderstanding Noise Schedules in Diffusion Models: A Comprehensive Guide Have you ever been captivated by the stunning visuals of digital art generated by AI and wondered about the underlying mechanics? A key element is the "noise schedule,&quo
 How to Build a Conversational Chatbot with GPT-4o? - Analytics VidhyaApr 18, 2025 am 10:06 AM
How to Build a Conversational Chatbot with GPT-4o? - Analytics VidhyaApr 18, 2025 am 10:06 AMBuilding a Contextual Chatbot with GPT-4o: A Comprehensive Guide In the rapidly evolving landscape of AI and NLP, chatbots have become indispensable tools for developers and organizations. A key aspect of creating truly engaging and intelligent chat
 Top 7 Frameworks for Building AI Agents in 2025Apr 18, 2025 am 10:00 AM
Top 7 Frameworks for Building AI Agents in 2025Apr 18, 2025 am 10:00 AMThis article explores seven leading frameworks for building AI agents – autonomous software entities that perceive, decide, and act to achieve goals. These agents, surpassing traditional reinforcement learning, leverage advanced planning and reasoni
 What's the Difference Between Type I and Type II Errors ? - Analytics VidhyaApr 18, 2025 am 09:48 AM
What's the Difference Between Type I and Type II Errors ? - Analytics VidhyaApr 18, 2025 am 09:48 AMUnderstanding Type I and Type II Errors in Statistical Hypothesis Testing Imagine a clinical trial testing a new blood pressure medication. The trial concludes the drug significantly lowers blood pressure, but in reality, it doesn't. This is a Type
 Automated Text Summarization with Sumy LibraryApr 18, 2025 am 09:37 AM
Automated Text Summarization with Sumy LibraryApr 18, 2025 am 09:37 AMSumy: Your AI-Powered Summarization Assistant Tired of sifting through endless documents? Sumy, a powerful Python library, offers a streamlined solution for automatic text summarization. This article explores Sumy's capabilities, guiding you throug


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 English version
Recommended: Win version, supports code prompts!

SublimeText3 Chinese version
Chinese version, very easy to use

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

