
Home >Technology peripherals >AI >AI industry application: Data weaving helps AI application training breakthroughs
AI industry application: Data weaving helps AI application training breakthroughs

- PHPzforward
- 2023-06-08 11:38:451282browse
#This article is produced by Everyone is a Product Manager’s “Original Incentive Plan”.
Although large-scale AI models are now very popular, and every enterprise wants a piece of it, the algorithms and data involved in realizing this process are not easy to grasp. Among them, data transmission and management is a big problem. This article focuses on the bottleneck of AI application training, summarizes the difficulties of AI training, and combines it with IDC analysis reports to conclude that "data" is the biggest bottleneck, and considers solutions to this problem.

1. Product background
"Recently, there have been voices discussing AI again. Different from the wait-and-see attitude towards AI in the past two years, many people say that with the application of ChatGPT, the AI era has really arrived, and students in product and operation are busy We understand what ChatGPT is, what Stable Diffusion is, etc., but the algorithm engineers are having crazy headaches and complaining crazily. The leaders ask them to build a large model as soon as possible, improve the algorithm model indicators as soon as possible, and serve the business. Passing by the algorithm team, I heard Zhang Gong and Hu The following dialogue of the worker:
Gong Zhang: Brother Hu, how is your model training going?
Hu Gong: Oh, it’s hard to explain in one sentence. There is no data. I finally submitted the data to the business department, but either they couldn’t collect it or the data they collected were all different and couldn’t be used?
Zhang Gong: Who is not? It’s the same for me. Recently, the customer’s pictures and videos added up to more than 10 T. We were asked to send them ourselves. It took our team a long time just to import the data.
Hu Gong said that if the company can build a data platform that allows us to quickly obtain data and manage the data, it will be more convenient for us to use data in our daily work. ”
After hearing the above conversation, I had an idea. The data management platform I recently built for customers based on the idea of data weaving can just solve their problems, so I quickly gave them a detailed product introduction and told them how to pass it. The design concept of "data weaving" builds a data management platform to help users break through the data bottleneck in AI application training.
2. Difficulties in AI training application
Excluding the subjective issues of personnel, we summarize the objective difficulties of AI application training, which can be summarized into the following three points:

High-quality data: To achieve good results in algorithm training, the first condition is high-quality data. However, how to obtain high-quality data has the following difficulties:
- Data diversity: There are structured/unstructured data in many formats, and the data provided by different systems lacks unified standards.
- Data distribution: Many business data are stored discretely and lack a unified data management platform. It is difficult to obtain data before application training.
- Data annotation: Data can be obtained instantly, but a large amount of business data needs to be annotated before it can be applied, and annotation is time-consuming and labor-intensive.
Efficient computing power: refers to the fact that when training a model, a large amount of computing power is usually required. At the same time, it is difficult to use the computing power efficiently
- At any time, large models are gradually promoted, the model size is getting larger and larger, and the demand for computing power is also increasing rapidly.
- When data storage is discrete, access to data will slow down. Even with cluster computing power, when parallelism is not possible, computing power will not be efficiently applied.
Mature framework: refers to the algorithm application that requires mature, stable, and highly scalable algorithm framework
- Application framework: There are currently many deep learning algorithm frameworks at home and abroad. For algorithm research (Pytorch) and industrial applications (Tensorflow), you need to choose different frameworks.
- Data conversion: Due to different frameworks and different languages used, even if high-quality data is prepared, it needs to be quickly adapted to different languages and training frameworks.
Summary: From the analysis of the three difficulties in AI application training, they are all related to data. Therefore, if the data problem can be solved, it can effectively help AI application training break through the bottleneck.
3. Is data the bottleneck of AI applications?
Although summarizing data from the application side is the bottleneck of AI application training, how many users think so? A piece of data is needed to illustrate.

Ranking of main challenges in artificial intelligence applications
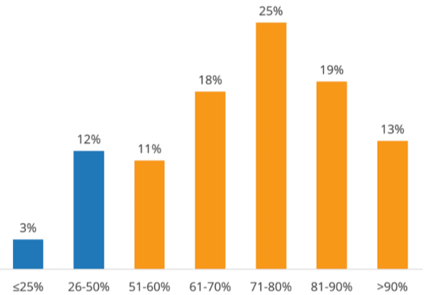
How much work is invested in data preparation during the development of artificial intelligence models
Note: The data comes from IDC statistical report
It can be seen from the statistics that 29% of users believe that the application of artificial intelligence lacks training and testing data, and 85% of users believe that at least half of the workload is spent on preparing data.
Summary: Since data has been confirmed to be the bottleneck of AI applications, we can consider looking for entry points from data to provide unified standards and fast access to large batches of highly available data sources. Carry out product planning for positioning.
4. Product Design
After finding data as the entry point, we think about how to build data-based products. Based on the above analysis, we can find that we need to solve three data-based problems in our products:
- Question 1:Data storage, try not to change the storage location of source data, and minimize the cost of data storage.
- Question 2: Fast access, it is best to change from early data query to data reasoning, and quickly search for the required data.
- Question 3:Unify standards to standardize complex data for easy application.
Based on the traditional data management platform, we adopt the concept of "data weaving and knowledge graph" to carry out transformation design to deal with the above problems. The breakthrough points of each issue are as follows:
- Question 1: Design based on data weaving ideas
- Question 2: Design based on the idea of knowledge graph
- Question 3: Providing external services based on a unified data platform
The next step is the detailed design of the product, which will be introduced from product positioning, application architecture, differentiated competitiveness and construction path.
1. Product Architecture
1) Product positioning
Provides a knowledge graph-style data management platform based on the idea of data weaving to serve customers who need high-quality data.
Note: Although the main goal is to solve the data bottleneck of AI application training, from the perspective of product planning, we have expanded the user scenarios, and anyone who needs data services is the target user of this product.
2) Product application architecture
From the data layer to the product application layer, we design the following product architecture:

Data layer: Supports access to different types of data, as well as structured data and unstructured data. There are many types of data for AI training, especially multi-modal applications that require multiple types of data.
Storage layer: In view of the discrete nature of data, it is necessary to support the storage of data in different locations, and support access from cloud data to local data.
Data management platform: The core product to be designed this time mainly includes four parts:
- Data governance: A common module that all traditional data management platforms have, providing functions such as data analysis, cleaning, and rule definition.
- Data security: It also belongs to the traditional module and provides functions related to data security, such as data desensitization, secure data transmission, etc.
- Data virtualization storage & distributed cache: Here, the idea of data weaving is used to grid-weave data from different platforms to form a data view. At the same time, only the logical information of the stored data is virtualized without metadata. Data migration and copying reduce storage costs; however, in order to obtain data quickly, a distributed cache is provided in the design to cache frequently accessed data, improve the I/O speed and parallelism of data for AI algorithm training, and maximize Improve computing cluster efficiency.
- Knowledge graph: Clean the data, define the rules, store it in the form of knowledge graph triples, and provide external query services in the form of knowledge graph. The knowledge graph is conducive to search reasoning, which can be done through a certain One entity data is related to another entity data. For example, if you query movie video data, you can search for "People are on the road to embarrassment". Through the actors "Wang Baoqiang" and "Xu Zheng", "Tai囧" will be associated. Querying through association reasoning can help users Quickly extract the required data from the platform.
Data service: After designing the platform, it is necessary to reserve an outlet for external services. Starting from the positioning of the product, it is mainly focused on toB customers, so it is necessary to consider both visual services and API services.
- API/SDK service: For companies or users with technical capabilities, such as the AI training application bottleneck that this article wants to solve, you can directly integrate the AI platform with the API service of the data platform to obtain the required data and clean it. The data is used for model training. Note: Generally, AI training platforms require annotated data, so you can first connect the annotation platform and then directly transmit the data to the AI training platform.
- Visual query: In addition to considering the technical level docking, of course, we also need to consider the behavior of business users such as querying data and downloading data on the platform, such as product managers and operations managers. They need to rely on the visual query provided by the platform itself. After retrieving and downloading data, , imported into other business platforms for processing and production, in which the visual query adopts a graph structure and uses the Tianyancha style as a reference. By searching for a certain data, the associated data is presented at the same time to facilitate user inference and query.

Illustration: The screenshots of Tianyancha are only for learning reference
2. Commercialization
Once the product is launched, commercialization is not available, so the commercialization direction needs to be clearly considered during the product planning stage, and the following three key aspects should be considered:
1) Selling content
For B-end customers, we provide two types of sales content, including "data management platform" standard products and "technical solutions".
- Standard products: For users without a data management platform, users only need to buy our standard products, access the data, and then apply them in their business, so that they can be used out of the box.
- Technical solutions: After the impact of the digital transformation trend, many B-side enterprise customers will more or less have their own data management platforms. Therefore, another selling point of toB is to sell mature technical solutions, which will be beneficial to existing enterprises. At this time, we need to transform the customer's products from the bottom layer to the service layer based on the "data weaving knowledge graph" design idea.
2) Sales method
The two common sales models for B-end products are "channel cooperation" and "direct sales", and these methods are also used in this product.
- Channel cooperation: Choose two types of channel cooperation, one is agents in prefectures and cities, who will promote them locally; the other is ISV model, find centralized agents with technical capabilities, and integrate the data management platform with their products Cooperation can complement each other's advantages and promote them to the outside world.
- Direct sales: Direct sales of products through product launches, advertising promotions, customer visits, etc.
3) Differentiation advantages
Since it is a data management platform based on new design ideas, during the product sales process, it needs to reflect the differentiated advantages from traditional data management platforms in order to catch up and attract users. We can summarize it as the following 3 Advantages:
- Data weaving: This product adopts the idea of data weaving for data management and uses data virtualization storage to reduce the physical storage cost of data; at the same time, it uses data caching to reduce the access delay of obtaining data during AI application training.
- AI capabilities: Different from the traditional data platform retrieval method through various conditions, this product is directly presented in the form of knowledge graph view. The user can only enter a simple condition, and the system can return the relevant data relationship topology. , to realize “finding people through data”.
- Mature standard products: Although you can sell technical solutions, it is difficult to impress customers without mature standard products. Therefore, unlike traditional manufacturers who sell large and comprehensive data management platforms, we sell "small but refined" one-stop services. An intelligent data management platform.
The maturity of the product also requires a continuous construction path. During the construction process of this product, it is based on "project polishing products" and is constructed in two major stages.
- Project delivery, technology precipitation: By undertaking 1/2 privatized data projects, the ideas of data weaving and knowledge graph construction are precipitated in the project, and technology precipitation is achieved.
- Product implementation and brand promotion: abstract products from actual projects and implement them iteratively. After product construction, branding and external promotion are carried out.
This article focuses on the bottleneck of AI application training, summarizes the difficulties of AI training, and combines it with IDC analysis reports to conclude that "data" is the biggest bottleneck, and considers solutions to this problem.
Based on the concepts of data weaving and knowledge graph, product transformation design is carried out. An intelligent data management platform for "data-finding" is introduced in detail from the perspectives of product positioning, product architecture, application scenarios, etc., and the follow-up of the product is also introduced. Business promotion ideas and construction paths can help customers with data application scenarios, such as AI training platforms, data annotation platforms, and even customers who need to transform and upgrade traditional data management products.
In the future, we will further explore the idea of expanding data weaving into the actual process of model parallel training to seek more feasibility of data efficiency.
Columnist
Eric_d, everyone is a product manager columnist. I am passionate about AI, big data and other fields. I have excellent requirements analysis, product process and architecture design skills. I also like hiking.
This article is produced by Everyone is a Product Manager's "Original Incentive Plan".
The title picture comes from Unsplash, based on the CC0 agreement.
The above is the detailed content of AI industry application: Data weaving helps AI application training breakthroughs. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology