

 Technology peripheralsAIAI imitates the memory model of the human brain, and game scores soared by 29.9%
Technology peripheralsAIAI imitates the memory model of the human brain, and game scores soared by 29.9%AI imitates the memory model of the human brain, and game scores soared by 29.9%

We are often taught to "think twice before acting" and make full use of accumulated experience. Now this sentence has also inspired AI.
Traditional decision-making AI models cannot effectively accumulate experience due to the existence of the forgetting effect, but a Chinese-led research has changed the memory method of AI.
The new memory method imitates the human brain, effectively improving the efficiency of AI in accumulating experience, thereby increasing AI's game performance by 29.9%.
The research team consists of six people, respectively from Mira-Québec AI Research Institute and Microsoft Montreal Research Institute, four of whom are Chinese.
They named the result Decision Transformer with Memory (DT-Mem).
Compared with traditional decision-making models, DT-Mem is more widely applicable and the efficiency of model operation is also higher.
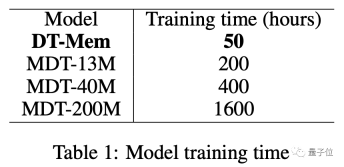
In addition to the application effect, the training time of DT-Mem has also been shortened from a minimum of 200 hours to 50 hours.
At the same time, the team also proposed a fine-tuning method to allow DT-Mem to adapt to new scenarios that have not been trained.
The fine-tuned model can also perform well in games that it has not learned before.
The working mechanism is inspired by humans
The traditional decision-making model is designed based on LLM and uses implicit memory, and its performance depends on data and calculation.
Implicit memories are generated unconsciously rather than deliberately remembered, and therefore cannot be recalled consciously.
To put it more simply, the relevant content is obviously stored there, but the model does not know its existence.
This characteristic of implicit memory determines the forgetting phenomenon in traditional models, resulting in low work efficiency.
The forgetting phenomenon is manifested in that after learning a new way to solve a problem, the model may forget the old content, even if the old and new problems are of the same type.
The human brain adopts a distributed memory storage method, and the memory content is dispersedly stored in multiple different areas of the brain.
This approach helps to effectively manage and organize multiple skills, thereby mitigating the phenomenon of forgetting.
Inspired by this, the research team proposed an internal working memory module to store, mix and retrieve information for different downstream tasks.
Specifically, DT-Mem consists of three parts: Transformer, memory module and multi-layer perception (MLP) module.

DT-Mem’s Transformer imitates the architecture of GPT-2, but deletes the feed-forward layer after the attention mechanism.
At the same time, the MLP module in GPT-2 is split into independent components as part of DT-Mem.
Between the two, the research team introduced a working memory module to store and process intermediate information.
This structure is inspired by neural Turing machines, in which the memory is used to infer various algorithms.
The memory module analyzes the information output by the Transformer and determines its storage location and how to integrate it with existing information.
In addition, this module also considers how this information will be used in future decision-making processes.
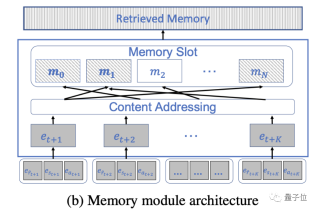
These tasks are roughly completed in five steps. The memory module is first initialized as a random matrix.
Then comes the sorting of the input information. This step is not to pass the information to the Transformer, but to store it in the same space in the form of tuples.
After that, you need to determine the storage location. Humans usually store related information in the same location, and DT-Mem is also based on this principle.
The last two steps - memory update and retrieval are the core of the memory module and the most important link in the entire DT-Mem.
Memory update means editing and replacing existing information to ensure that the information can be updated in time according to the needs of the task.
In this step, DT-Mem will calculate the erase and write vectors to determine how to mix them with existing data.
Memory retrieval is the access and recovery of existing information, and timely retrieval of relevant and useful information when decisions need to be made.
Before being put into actual use, DT-Mem still needs to go through a pre-training process.

As for the fine-tuning of DT-Mem, the team also proposed a new method.
Since it uses data labeled based on tasks, this kind of fine-tuning can help DT-Mem adapt to new tasks.
This process is based on low-rank adaptation (LoRA), adding low-rank elements to the existing matrix.

Training time is shortened by up to 32 times
To test DT-Mem’s decision-making ability, the research team let it play several games game.
There are 5 games in total, all from Atari.
At the same time, the team also tested the performance of the traditional model M[ulti-game]DT as a reference.
As a result, DT-Mem’s best results in 4 of the games were all better than MDT.
Specifically, DT-Mem improves the DQN normalized score by 29.9% compared to MDT.
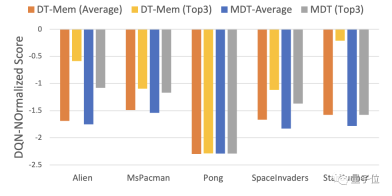
However, the parameter amount of DT-Mem is only 20M, which is only 10% of MDT (200M parameters).
Such a performance is not an exaggeration to say that it is a big deal.
In addition to its excellent performance, DT-Mem’s training efficiency also surpasses MDT.
The 13M parameter version of MDT takes 200 hours to train, while the 20M DT-Mem only takes 50 hours.
Compared with the 200M version, the training time is shortened by 32 times, but the performance is even better.
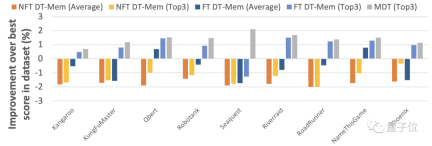
#The test results of the fine-tuning method proposed by the team also show that this fine-tuning enhances DT-Mem's ability to adapt to unknown scenarios.
It should be noted that the games used for testing in the table below are known to MDT, so MDT's performance is not used as a basis for measurement in this round.
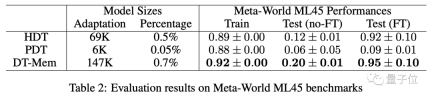
In addition to playing games, the team also tested DT-Mem using the Meta-World ML45 benchmark.
The ones used as reference this time are H[yper]DT and P[romot]DT.
The results show that among the models without fine-tuning, DT-Mem scores are 8 percentage points higher than HDT.
It should be noted that although the HDT tested here has only 69K parameters, it relies on a pre-trained model with 2.3M parameters, so the actual parameter number is more than 10 times that of DT-Mem (147K). times.
Paper address: https://arxiv.org/ abs/2305.16338
The above is the detailed content of AI imitates the memory model of the human brain, and game scores soared by 29.9%. For more information, please follow other related articles on the PHP Chinese website!

 Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AM
Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AMThis article explores the growing concern of "AI agency decay"—the gradual decline in our ability to think and decide independently. This is especially crucial for business leaders navigating the increasingly automated world while retainin
 How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AM
How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AMEver wondered how AI agents like Siri and Alexa work? These intelligent systems are becoming more important in our daily lives. This article introduces the ReAct pattern, a method that enhances AI agents by combining reasoning an
 Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM
Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM"I think AI tools are changing the learning opportunities for college students. We believe in developing students in core courses, but more and more people also want to get a perspective of computational and statistical thinking," said University of Chicago President Paul Alivisatos in an interview with Deloitte Nitin Mittal at the Davos Forum in January. He believes that people will have to become creators and co-creators of AI, which means that learning and other aspects need to adapt to some major changes. Digital intelligence and critical thinking Professor Alexa Joubin of George Washington University described artificial intelligence as a “heuristic tool” in the humanities and explores how it changes
 Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AM
Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AMLangChain is a powerful toolkit for building sophisticated AI applications. Its agent architecture is particularly noteworthy, allowing developers to create intelligent systems capable of independent reasoning, decision-making, and action. This expl
 What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AM
What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AMRadial Basis Function Neural Networks (RBFNNs): A Comprehensive Guide Radial Basis Function Neural Networks (RBFNNs) are a powerful type of neural network architecture that leverages radial basis functions for activation. Their unique structure make
 The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AM
The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AMBrain-computer interfaces (BCIs) directly link the brain to external devices, translating brain impulses into actions without physical movement. This technology utilizes implanted sensors to capture brain signals, converting them into digital comman
 Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AM
Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AMThis "Leading with Data" episode features Ines Montani, co-founder and CEO of Explosion AI, and co-developer of spaCy and Prodigy. Ines offers expert insights into the evolution of these tools, Explosion's unique business model, and the tr
 A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AM
A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AMThis article explores Retrieval Augmented Generation (RAG) systems and how AI agents can enhance their capabilities. Traditional RAG systems, while useful for leveraging custom enterprise data, suffer from limitations such as a lack of real-time dat


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Zend Studio 13.0.1
Powerful PHP integrated development environment

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

