
 Technology peripheralsAIThe crazy open source plans of the four post-00s generation: the entire Internet is converted into a large model corpus, and the cost of embedding 100 million tokens is only US$1.
Technology peripheralsAIThe crazy open source plans of the four post-00s generation: the entire Internet is converted into a large model corpus, and the cost of embedding 100 million tokens is only US$1.
All the papers on Arxiv are converted into tokens, and the total amount is only 14.1GB.
This is the feat accomplished by Alexander, the latest hot open source project.
In fact, this is only the first step.
Ultimately, they want to turn the entire Internet into Tokens, in other words, transform everything into the way large models such as ChatGPT understand the world.
Once such a data set is born, wouldn't it be a new powerful tool for developing large models like GPT-4, and it will be possible to understand astronomy and geography just around the corner? !
As soon as the news came out, it immediately attracted huge attention.

Netizens praised, epic.


More than 4 million projects, 600 million tokens, and 3.07 billion vector dimensions.This open source project called Alexander starts with each paper on Arxiv. The chosen method is embedding. Simply put, it is to visualize various objects in the real world into vectors that the computer can understand.


(such as classification, retrieval, clustering, etc.) by simply providing task instructions without any fine-tuning. Text evaluation, etc.) and fields (such as science, finance, medicine, etc.) 》
Next week they will release Arxiv search. The process so far is to first perform a similarity search on the 100 closest articles, then calculate the embeddings of these on the fly and conduct a second, more complex search. The ultimate goal is an entire Internet embedded plan. Crazy open source plan of a 20-year-old boyThere are two main reasons why we want to launch such a crazy open source plan. On the one hand, it is to embed huge value. Many problems in the world are just search, clustering, recommendation or classification, and these are things that embeddings are very good at. And as mentioned before, some complex puzzles can be solved. On the other hand the cost is one time and very cheap. In most cases there is no need to perform a second calculation on the same file. Currently, every 100 million Tokens only cost $1$.
But they didn’t find any open embedded data sets, so this organization came into being. They will also open more data sets in the future, and these will be selected by these users. In addition to the public data sets on the official website, the remaining open source projects have opened voting channels.

And their team name is also very domineering, Macrocosm (Macro World) Alliance.
As long as you zoom in far enough, humans become a single creature.
According to the official introduction, they are committed to building plug-ins for ChatGPT and other similar products. They are also developing core products, personal research assistants based on large models to help learning, teaching and scientific research.
Interested friends can click on the link below to learn more~
https://alex.macrocosm.so/download
The above is the detailed content of The crazy open source plans of the four post-00s generation: the entire Internet is converted into a large model corpus, and the cost of embedding 100 million tokens is only US$1.. For more information, please follow other related articles on the PHP Chinese website!

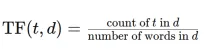 Convert Text Documents to a TF-IDF Matrix with tfidfvectorizerApr 18, 2025 am 10:26 AM
Convert Text Documents to a TF-IDF Matrix with tfidfvectorizerApr 18, 2025 am 10:26 AMThis article explains the Term Frequency-Inverse Document Frequency (TF-IDF) technique, a crucial tool in Natural Language Processing (NLP) for analyzing textual data. TF-IDF surpasses the limitations of basic bag-of-words approaches by weighting te
 Building Smart AI Agents with LangChain: A Practical GuideApr 18, 2025 am 10:18 AM
Building Smart AI Agents with LangChain: A Practical GuideApr 18, 2025 am 10:18 AMUnleash the Power of AI Agents with LangChain: A Beginner's Guide Imagine showing your grandmother the wonders of artificial intelligence by letting her chat with ChatGPT – the excitement on her face as the AI effortlessly engages in conversation! Th
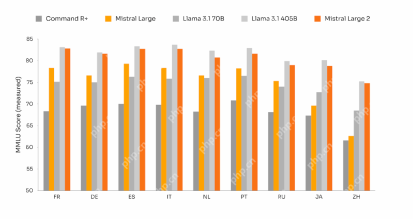 Mistral Large 2: Powerful Enough to Challenge Llama 3.1 405B?Apr 18, 2025 am 10:16 AM
Mistral Large 2: Powerful Enough to Challenge Llama 3.1 405B?Apr 18, 2025 am 10:16 AMMistral Large 2: A Deep Dive into Mistral AI's Powerful Open-Source LLM Meta AI's recent release of the Llama 3.1 family of models was quickly followed by Mistral AI's unveiling of its largest model to date: Mistral Large 2. This 123-billion paramet
 What is Noise Schedules in Stable Diffusion? - Analytics VidhyaApr 18, 2025 am 10:15 AM
What is Noise Schedules in Stable Diffusion? - Analytics VidhyaApr 18, 2025 am 10:15 AMUnderstanding Noise Schedules in Diffusion Models: A Comprehensive Guide Have you ever been captivated by the stunning visuals of digital art generated by AI and wondered about the underlying mechanics? A key element is the "noise schedule,&quo
 How to Build a Conversational Chatbot with GPT-4o? - Analytics VidhyaApr 18, 2025 am 10:06 AM
How to Build a Conversational Chatbot with GPT-4o? - Analytics VidhyaApr 18, 2025 am 10:06 AMBuilding a Contextual Chatbot with GPT-4o: A Comprehensive Guide In the rapidly evolving landscape of AI and NLP, chatbots have become indispensable tools for developers and organizations. A key aspect of creating truly engaging and intelligent chat
 Top 7 Frameworks for Building AI Agents in 2025Apr 18, 2025 am 10:00 AM
Top 7 Frameworks for Building AI Agents in 2025Apr 18, 2025 am 10:00 AMThis article explores seven leading frameworks for building AI agents – autonomous software entities that perceive, decide, and act to achieve goals. These agents, surpassing traditional reinforcement learning, leverage advanced planning and reasoni
 What's the Difference Between Type I and Type II Errors ? - Analytics VidhyaApr 18, 2025 am 09:48 AM
What's the Difference Between Type I and Type II Errors ? - Analytics VidhyaApr 18, 2025 am 09:48 AMUnderstanding Type I and Type II Errors in Statistical Hypothesis Testing Imagine a clinical trial testing a new blood pressure medication. The trial concludes the drug significantly lowers blood pressure, but in reality, it doesn't. This is a Type
 Automated Text Summarization with Sumy LibraryApr 18, 2025 am 09:37 AM
Automated Text Summarization with Sumy LibraryApr 18, 2025 am 09:37 AMSumy: Your AI-Powered Summarization Assistant Tired of sifting through endless documents? Sumy, a powerful Python library, offers a streamlined solution for automatic text summarization. This article explores Sumy's capabilities, guiding you throug


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 English version
Recommended: Win version, supports code prompts!

SublimeText3 Chinese version
Chinese version, very easy to use

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

