

 Technology peripheralsAIMidjourney's rival is here! Google's StyleDrop ace 'Customization Master' detonates the AI art circle
Technology peripheralsAIMidjourney's rival is here! Google's StyleDrop ace 'Customization Master' detonates the AI art circleMidjourney's rival is here! Google's StyleDrop ace 'Customization Master' detonates the AI art circle

As soon as Google StyleDrop came out, it instantly hit the internet.
Given Van Gogh’s Starry Night, AI transformed into Master Van Gogh, and after a top-level understanding of this abstract style, it created countless similar paintings.

Another cartoon style, the objects I want to draw are much more cute.

Even, it can accurately control the details and design an original style logo.

The charm of StyleDrop is that you only need one picture as a reference, and you can deconstruct and recreate the artistic style no matter how complex it is.
Netizens expressed that this is another AI tool that eliminates designers.
StyleDrop hot research is the latest product from the Google research team.

##Paper address: https://arxiv.org/pdf/2306.00983.pdf
Now, with tools like StyleDrop, not only can you draw with more control, but you can also complete previously unimaginable fine work, such as drawing a logo.
Even NVIDIA scientists called it a "phenomenal" result.

The author of the paper introduced that the source of inspiration for StyleDrop is Eyedropper (color absorption) /color picker tool).
Similarly, StyleDrop also hopes that everyone can quickly and effortlessly "pick" a style from a single/few reference images to generate an image of that style.



I have to say, it’s too strong.

 ## are also the letters of Van Gogh style.
## are also the letters of Van Gogh style.

There are also line drawings. Line drawing is a highly abstract image and requires very high rationality in the composition of the picture. Past methods have been difficult to succeed.

The strokes of the cheese shadow in the original image are restored to the objects in each image.

Refer to Android LOGO creation.

In addition, the researchers also expanded the capabilities of StyleDrop, not only to customize the style, combined with DreamBooth, but also to customize the content.
For example, still in the Van Gogh style, generate a similar style painting for the little Corgi:

Here’s another one. The corgi below feels like the “Sphinx” on the Egyptian pyramids.

how to work?
StyleDrop is built on Muse and consists of two key parts:
One is the effective fine-tuning of the parameters that generate the visual Transformer, and the other is iteration with feedback train.
The researchers then synthesized images from the two fine-tuned models.
Muse is the latest text-to-image synthesis model based on mask-generated image Transformer. It contains two synthesis modules for base image generation (256 × 256) and super-resolution (512 × 512 or 1024 × 1024).

Each module consists of a text encoder T, a transformer G, a sampler S, and an image encoder It consists of decoder E and decoder D.
T maps the textual prompt t∈T to the continuous embedding space E. G processes text embeddings e ∈ E to generate logarithms of visual token sequences l ∈ L. S extracts a sequence of visual tokens v ∈ V from the logarithm through iterative decoding that runs several steps of transformer inference conditioned on the text embedding e and the visual token decoded from the previous step.
Finally, D maps the discrete token sequence to the pixel space I. In summary, given a text prompt t, the composition of image I is as follows:

Figure 2 is a simplified Muse transformer layer architecture, which was partially modified to support Parameter Efficient Fine-tuning (PEFT) and adapters.
Use the transformer of the L layer to process the visual token sequence displayed in green under the condition of text embedding e. The learned parameters θ are used to construct weights for adapter tuning.

In order to train θ, in many cases, researchers may only give pictures as style references.
Researchers need to manually attach text prompts. They proposed a simple, templated approach to constructing text prompts consisting of a description of the content followed by a description-style phrase.
For example, the researcher uses "cat" to describe an object in Table 1 and appends "watercolor painting" as a style description.

Including a description of content and style in a text prompt is critical because it helps separate content from style, which is the research The main goal of the personnel.
Figure 3 shows iterative training with feedback.
When training on a single style reference image (orange box), some images generated by StyleDrop may exhibit content extracted from the style reference image (red box, image The background contains a house similar to the style image).
Other images (blue boxes) better separate the style from the content. Iterative training of StyleDrop on good samples (blue box) results in a better balance between style and text fidelity (green box).

##The researchers also used two methods here:
-CLIP score
#This method is used to measure the alignment of images and text. Therefore, it can evaluate the quality of the generated images by measuring the CLIP score (i.e., the cosine similarity of visual and textual CLIP embeddings).
Researchers can select the CLIP image with the highest score. They call this method CLIP-feedback iterative training (CF).
In experiments, the researchers found that using CLIP scores to evaluate the quality of synthetic images is an effective way to improve recall (i.e., text fidelity) without excessive loss Style fidelity.
On the other hand, however, CLIP scores may not fully align with human intent, nor capture subtle stylistic attributes.
-HF
Human feedback (HF) is a method that injects user intent directly into synthetic image quality assessment in a more direct way.
In LLM fine-tuning for reinforcement learning, HF has proven its power and effectiveness.
HF can be used to compensate for the inability of CLIP scores to capture subtle style attributes.
Currently, a large amount of research has focused on the personalization problem of text-to-image diffusion models to synthesize images containing multiple personal styles.
Researchers show how DreamBooth and StyleDrop can be combined in a simple way to personalize both style and content.
This is accomplished by sampling from two modified generative distributions, guided by θs for style and θc for content, independently on the style and content reference images respectively. Trained adapter parameters.
Unlike existing products, the team’s approach does not require joint training of learnable parameters on multiple concepts, which leads to greater combinatorial capabilities. Because pre-trained adapters are trained on individual topics and styles separately.
The researchers’ overall sampling process follows the iterative decoding of Equation (1), with the logarithms sampled differently in each decoding step.
Suppose t is a text prompt, c is a text prompt without style descriptor, and the logarithm is calculated in step k as follows:


Where: γ is used to balance StyleDrop and DreamBooth - if γ is 0, we get StyleDrop, if it is 1, we get DreamBooth.
By setting γ appropriately, we can get a suitable image.
Experimental settings
So far, there is no Style adjustment of text-image generative models has been extensively studied.
Therefore, the researchers proposed a new experimental plan:
-Data collection
The researchers collected dozens of pictures in different styles, from watercolor and oil paintings, flat illustrations, 3D renderings to sculptures of different materials.
-Model Configuration
Researchers use adapters to tune Muse-based StyleDrop. For all experiments, the Adam optimizer was used to update the adapter weights for 1000 steps with a learning rate of 0.00003. Unless otherwise stated, the researchers use StyleDrop to represent the second round of the model, which was trained on more than 10 synthetic images with human feedback.
- Evaluation
Quantitative evaluation of research reports based on CLIP, measuring style consistency and textual alignment. Additionally, the researchers conducted user preference studies to assess style consistency and text alignment.
As shown in the picture, the results of StyleDrop processing of 18 pictures of different styles collected by the researchers.
As you can see, StyleDrop is able to capture the nuances of texture, shading and structure of various styles, giving you better control over style than before.

For comparison, the researchers also introduced the results of DreamBooth on Imagen, DreamBooth on Stable Diffusion and LoRA Realization and text inversion results.

#The specific results are shown in the table, human image-text alignment (Text) and visual style alignment (Style) Evaluation metrics for score (top) and CLIP score (bottom).

## Qualitative comparison of (a) DreamBooth, (b) StyleDrop, and (c) DreamBooth StyleDrop:

Here, the researchers applied the two metrics of the CLIP score mentioned above - text and style scores.
For text score, researchers measure the cosine similarity between image and text embeddings. For the style score, the researchers measure the cosine similarity between the style reference and the synthetic image embedding.
The researchers generated a total of 1520 images for 190 text prompts. While the researchers hoped the final score would be higher, the metrics are not perfect.
And iterative training (IT) improved text scores, which was in line with the researchers’ goals.
However, as a trade-off, their style scores on the first-round model are reduced because they are trained on synthetic images and the style may be biased by selection bias.
DreamBooth on Imagen is not as good as StyleDrop in style score (HF's 0.644 vs. 0.694).
The researchers noticed that the increase in style score of DreamBooth on Imagen was not obvious (0.569 → 0.644), while the increase of StyleDrop on Muse was more obvious (0.556 → 0.694).
Researchers analyzed that the style fine-tuning on Muse is more effective than that on Imagen.
In addition, for fine-grained control, StyleDrop captures subtle style differences, such as color offset, gradation, or sharp angle control.

Netizens’ hot comments
If designers have StyleDrop, their work efficiency will be 10 times faster and it has already taken off. .

One day of AI, 10 years of human life, AIGC is developing at the speed of light, the kind of light speed that blinds people's eyes!

Tools just follow the trend, and those that should be eliminated have already been eliminated long ago.

This tool is much easier to use than Midjourney for making logos.

The above is the detailed content of Midjourney's rival is here! Google's StyleDrop ace 'Customization Master' detonates the AI art circle. For more information, please follow other related articles on the PHP Chinese website!

 Gemini 2.5 Pro vs GPT 4.5: Can Google Beat OpenAI's Best?Apr 24, 2025 am 09:39 AM
Gemini 2.5 Pro vs GPT 4.5: Can Google Beat OpenAI's Best?Apr 24, 2025 am 09:39 AMThe AI race is heating up with newer, competing models launched every other day. Amid this rapid innovation, Google Gemini 2.5 Pro challenges OpenAI GPT-4.5, both offering cutting-edge advancements in AI capabilities. In this Gem
 Karun Thanks's bluepring for data science successApr 24, 2025 am 09:38 AM
Karun Thanks's bluepring for data science successApr 24, 2025 am 09:38 AMKarun Thankachan: A Data Science Journey from Software Engineer to Walmart Senior Data Scientist Karun Thankachan, a senior data scientist specializing in recommender systems and information retrieval, shares his career path, insights on scaling syst
 We Tried Gemini 2.5 Pro Experimental and It's Mind-Blowing!Apr 24, 2025 am 09:36 AM
We Tried Gemini 2.5 Pro Experimental and It's Mind-Blowing!Apr 24, 2025 am 09:36 AMGoogle DeepMind's Gemini 2.5 Pro (experimental): A Powerful New AI Model Google DeepMind has released Gemini 2.5 Pro (experimental), a groundbreaking AI model that has quickly ascended to the top of the LMArena Leaderboard. Building on its predecess
 Top 5 Code Editors to Vibe Code in 2025Apr 24, 2025 am 09:31 AM
Top 5 Code Editors to Vibe Code in 2025Apr 24, 2025 am 09:31 AMRevolutionizing Software Development: A Deep Dive into AI Code Editors Tired of endless coding, constant tab-switching, and frustrating troubleshooting? The future of coding is here, and it's powered by AI. AI code editors understand your project f
 5 Jobs AI Can't Replace According to Bill GatesApr 24, 2025 am 09:26 AM
5 Jobs AI Can't Replace According to Bill GatesApr 24, 2025 am 09:26 AMBill Gates recently visited Jimmy Fallon's Tonight Show, talking about his new book "Source Code", his childhood and Microsoft's 50-year journey. But the most striking thing in the conversation is about the future, especially the rise of artificial intelligence and its impact on our work. Gates shared his thoughts in a hopeful yet honest way. He believes that AI will revolutionize the world at an unexpected rate and talks about work that AI cannot replace in the near future. Let's take a look at these tasks together. Table of contents A new era of abundant intelligence Solve global shortages in healthcare and education Will artificial intelligence replace jobs? Gates said: For some jobs, it will Work that artificial intelligence (currently) cannot replace: human touch remains important Conclusion
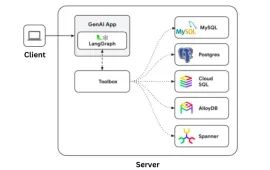 Google Gen AI Toolbox: A Python Library for SQL DatabasesApr 24, 2025 am 09:23 AM
Google Gen AI Toolbox: A Python Library for SQL DatabasesApr 24, 2025 am 09:23 AMGoogle's Gen AI Toolbox for Databases: Revolutionizing Database Interaction with Natural Language Google has unveiled the Gen AI Toolbox for Databases, a revolutionary open-source Python library designed to simplify database interactions using natura
 OpenAI's GPT 4o Image Generation is SUPER COOLApr 24, 2025 am 09:21 AM
OpenAI's GPT 4o Image Generation is SUPER COOLApr 24, 2025 am 09:21 AMOpenAI's ChatGPT Now Boasts Native Image Generation: A Game Changer ChatGPT's latest update has sent ripples through the tech world with the introduction of native image generation, powered by GPT-4o. Sam Altman himself hailed it as "one of the
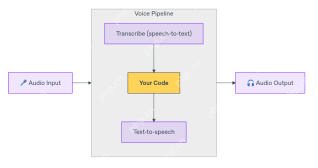 How to Build Multilingual Voice Agent Using OpenAI Agent SDK? - Analytics VidhyaApr 24, 2025 am 09:16 AM
How to Build Multilingual Voice Agent Using OpenAI Agent SDK? - Analytics VidhyaApr 24, 2025 am 09:16 AMOpenAI's Agent SDK now offers a Voice Agent feature, revolutionizing the creation of intelligent, real-time, speech-driven applications. This allows developers to build interactive experiences like language tutors, virtual assistants, and support bo


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

