
Home >Database >Mysql Tutorial >What are the rules for mysql gap lock locking?
What are the rules for mysql gap lock locking?

- PHPzforward
- 2023-06-03 20:41:491687browse
mysql 11 rules for gap lock locking
Gap lock will only take effect under the repeatable read isolation level: next-key lock is actually implemented by gap lock plus row lock. If you switch If you reach the read-committed isolation level (read-committed), it will be easy to understand. The gap lock part is removed in the process, that is, only the row lock part is left. Under the read-commit isolation level, there is no gap lock. In order to solve the possible inconsistency between data and logs, the binlog format needs to be set to row. In other words, many companies' configuration is: read commit isolation level plus binlog_format=row. The business does not need the guarantee of repeatable reading, so considering that the lock range of the operation data under read submission is smaller (no gap lock), this choice is reasonable.
Principle 1: The basic unit of locking is next-key lock. next-key lock is an open and closed interval.
Principle 2: Only objects accessed during the search process will be locked. Any lock on a secondary index, or a lock on a non-indexed column, will eventually be traced back to the primary key, and a lock will also be added to the primary key.
Optimization 1: For equivalent queries on the index, when locking the unique index, the next-key lock degenerates into a row lock. That is to say, if InnoDB scans a primary key or a unique index, InnoDB will only use row locks to lock
Optimization 2: Equivalent queries on indexes (not necessarily unique indexes), to During right traversal and when the last value does not satisfy the equality condition, next-keylock degenerates into a gap lock.
A bug: a range query on a unique index will access the first value that does not meet the condition.
CREATE TABLE `test` ( id` int(11) NOT NULL, col1` int(11) DEFAULT NULL, col2` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`col1`) ) ENGINE=InnoDB; insert into test values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);Case 1: Unique index equal value query gap Lock
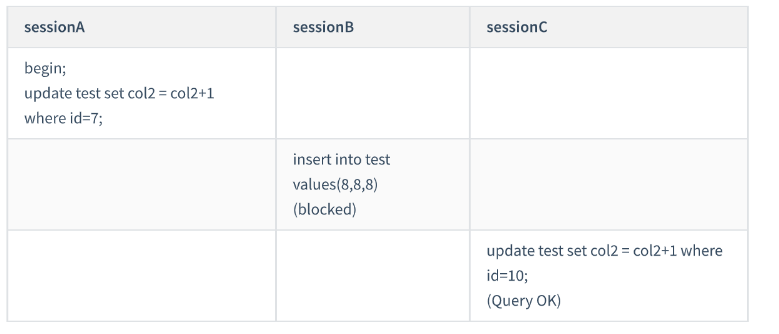

id is degenerated into a row lock, and only the row lock for the row id=10 is added.
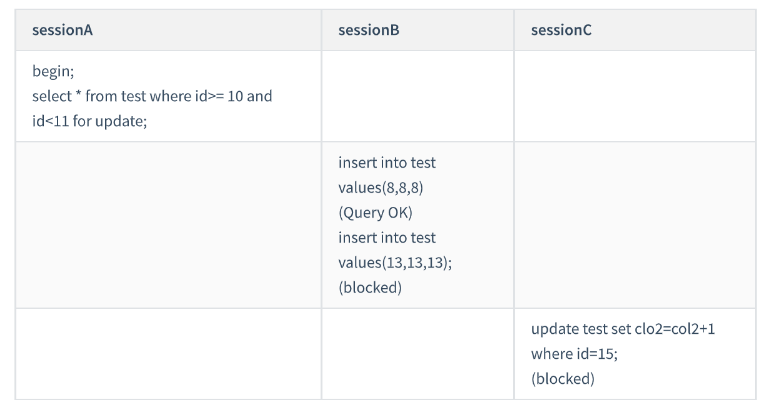
It is a range query. If you want to search within a range, continue searching until you find the line id=15 and stop. The condition is not met, so you need to add
next-key lock(10,15].
Session A At this time, the scope of the lock is the primary key index, row lock id=10 and next-key lock(10,15]. When session A locates the row with
id=10 for the first time, it is judged as an equivalent query. , and when scanning to the right to id=15, range query judgment is used.
Case 4: Non-unique index range query lock

When col1=10 is used to locate the record for the first time, (5,10] is added to index c After this next-key lock, since index col1 is a non-only index, there are no optimization rules, which means that it will not transform into a row lock. Therefore, the final lock added to session A is (5,10] on index c. and
(10,15] these two next-keylocks.
It is reasonable to scan to col1=15 before stopping the scan, because InnoDB needs to scan to col1=15 before knowing that there is no need to continue.
Found it.

is the unique key, the loop should stop when it reaches the row of id=15.
But in terms of implementation, InnoDB will Scan forward to the first behavior that does not meet the condition, that is, id=20. And since this is a range scan, the next-key lock of (15,20] on the index id will also be locked. Logically speaking, the behavior of locking the id=20 line here is actually
unnecessary. Because after scanning id=15, you can be sure that you don’t need to look for it later.
Case Six: Examples of " " Equivalent " " on non-unique indexes
Here, I insert a new record into table t: insert into t values(30,10,30); that is to say, now the table There are two rows with c=10
but their primary key value IDs are different (10 and 30 respectively), so there is a gap between the two records with c=10.
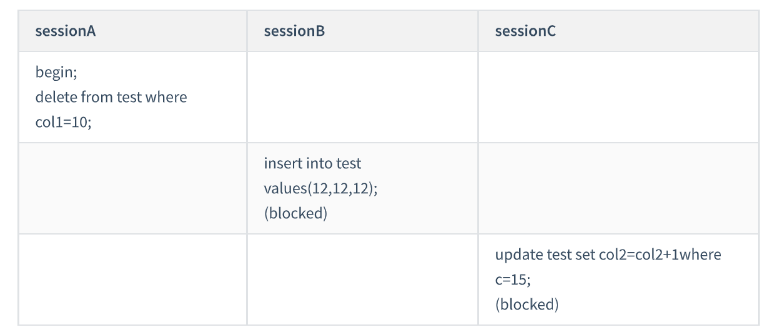 This time we use the delete statement to verify. Note that the locking logic of the delete statement is actually similar to select ... for update,
This time we use the delete statement to verify. Note that the locking logic of the delete statement is actually similar to select ... for update,
At this time, session A first accesses the first col1=10 record when traversing. Similarly, according to principle 1 , what is added here is the next-key lock from
(col1=5,id=5) to (col1=10,id=10).
Since c is an ordinary index, continue to search to the right until it hits The loop ends at the line (col1=15,id=15). According to optimization 2, this is
an equivalent query. Rows that do not meet the conditions are found to the right, so it will degenerate into a gap from (col1=10,id=10) to (col1=15,id=15)
Lock.
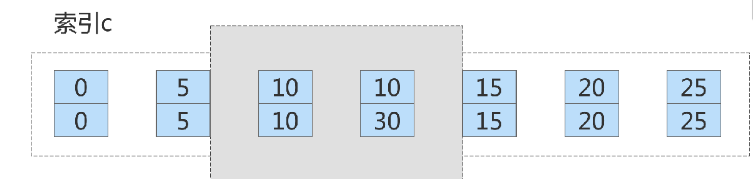 The locking range of this delete statement on index c is the part covered by the blue area in the figure above. There are
The locking range of this delete statement on index c is the part covered by the blue area in the figure above. There are
Case 7: The limit statement is locked
 The delete statement of session A is locked with limit 2. You know that there are actually only two records with c=10 in table t, so the effect of adding or deleting limit 2 is the same. But the locking effect is different
The delete statement of session A is locked with limit 2. You know that there are actually only two records with c=10 in table t, so the effect of adding or deleting limit 2 is the same. But the locking effect is different
satisfies the condition There are already two statements, and the loop ends. Therefore, the locking range on index col1 becomes the front-open and back-closed range from (col1=5,id=5)
to (col1=10,id=30), as shown in the following figure:
The guiding significance of this example to our practice is to try to add a limit when deleting data. 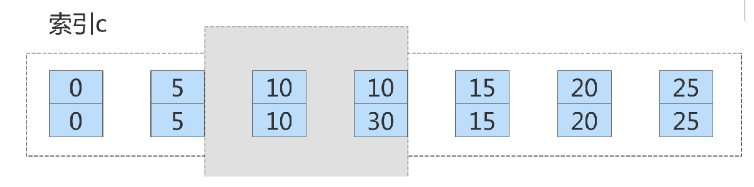 This not only controls the number of deleted data, making the operation safer, but also reduces the scope of locking.
This not only controls the number of deleted data, making the operation safer, but also reduces the scope of locking.
Case 8: An example of deadlock
Session A executes the query statement after starting the transaction and adds lock in share mode, and adds next to the index col1 -keylock(5,10] and 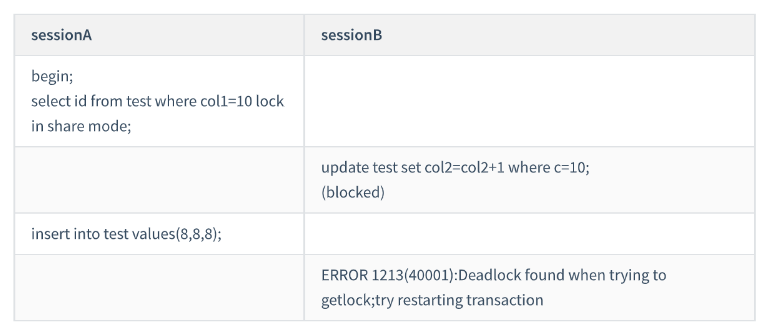 gap lock(10,15) (index traversal to the right degenerates into gap lock);
gap lock(10,15) (index traversal to the right degenerates into gap lock);
first add the gap lock of (5,10), the lock is successful; then add the row lock of col1=10, because this row has been added in sessionA The read
lock is locked. At this time, the deadlock application will be blocked
Then session A wants to insert the line (8,8,8) again, which is locked by the gap lock of session B. Due to the deadlock, , InnoDB lets
session B rollback
Case 9: Order by index sorting gap lock 1
Such as the following statement
The following figure is a schematic diagram of the index id of this table.
begin;
select * from test where id>9 and id

th id This process is obtained through the search process of the index tree. Inside the engine, we actually want to find the value of id=12, but in the end
was not found, but the gap (10,15) was found. (id=15 does not meet the conditions, so next-key lock degenerates into gap lock (10,
15).)
Then traverse to the left. During the traversal process, there is no equivalent query, and it will be scanned In the line id=5, and because the interval is open on the left and closed on the right, a next-key lock (0,5] will be added. In other words, during the execution process, the record is located through tree search
, the "equivalent query" method is used.
Case 10: Order by index sorting gap lock 2
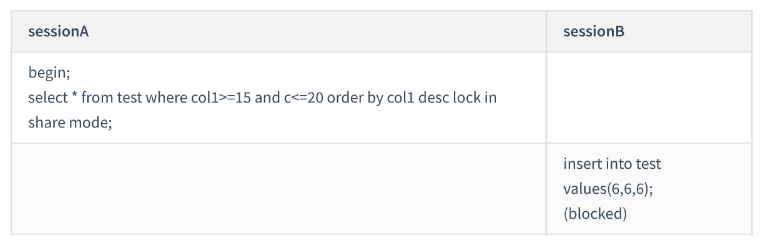 Since it is order by col1 desc, the first thing to be located is the "rightmost" col1=20 row on index col1. This is an equivalent query of a non-unique index:
Since it is order by col1 desc, the first thing to be located is the "rightmost" col1=20 row on index col1. This is an equivalent query of a non-unique index:
First join in the open interval on the left Next-key locks, forming the (15,20] interval. Traverse to the right, col1=25 does not meet the conditions, and degenerates into a gap lock, so gap lock (20,25) and next-key lock (15,20] will be added.
Stop scanning the index to the left when traversing to col1=10. The next key lock (next-keylock) will be applied to the right open left closed interval (5,10)
This is exactly The reason for blocking the insert statement of session B. During the scanning process, there are values in the three rows col1=20, col1=15, col1=10. Since it is select *, the primary key
id will be added. Three row locks. Therefore, the range of the select statement lock of session A is:
Index col1 on (5, 25); Two row locks on the primary key index id=15 and 20.
Case 11: Example of update modifying data - first insert and then delete
 Note: The first record found according to col1>5 is col1=10, so it is not The next-key lock of (0,5] will be added.
Note: The first record found according to col1>5 is col1=10, so it is not The next-key lock of (0,5] will be added.
After the first update statement of session B, you need to change col1=5 to col1=1. You can understand it as two steps:
Insert (col1=1, id=5 ) this record;
Delete the record (col1=5, id=5).
Through this operation, the locking range of session A becomes as shown in Figure 7:
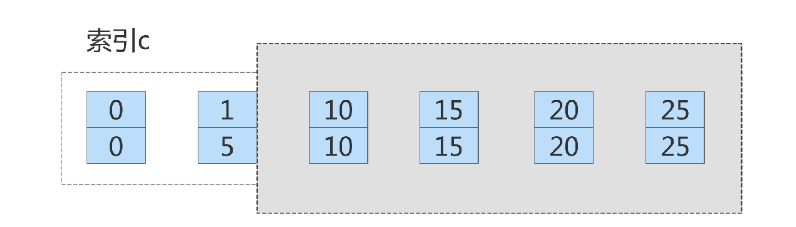 OK, next session B needs to execute update t set col1 = 5 where col1 = 1 This statement can be split into two steps:
OK, next session B needs to execute update t set col1 = 5 where col1 = 1 This statement can be split into two steps:
Delete the record (col1=1, id=5). The first step was to try to insert data into (1,10) that had a gap lock, so it was blocked
.
The above is the detailed content of What are the rules for mysql gap lock locking?. For more information, please follow other related articles on the PHP Chinese website!