
Home >Database >Mysql Tutorial >What are the situations in which MySQL index optimization is suitable for building indexes?
What are the situations in which MySQL index optimization is suitable for building indexes?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-06-02 21:08:411516browse
Conclusion
Create an index on the filter field behind where (the where behind select/update/delete are all applicable), use the index to speed up filtering efficiency, without the need for the entire table Scan
and add unique indexes on fields with unique requirements to speed up query efficiency. If found, you can directly return
group by or order Add an index to the field after by. Since the index is sorted, establishing the index is equivalent to sorting it before querying (here you need to pay attention to the order of the fields in the joint index establishment, which can be combined with specific case scenarios 7 Learn)
Add an index to the field after DISTINCT (deduplication field). Since the index is established, the same data is next to each other, so you can quickly remove it. Repeat the operation, otherwise you may need to find the same data and perform the deduplication operation
When joining multiple tables, create an index on the connected field (small table drives large table )
Take a certain prefix of the string to create an index (not use the entire string as the index, otherwise it will take up too much space)
Create indexes on frequently used columns (joint indexes can be built, and the most frequently used fields should be on the leftmost side of the joint index, leftmost principle)
When the distinction is high Create an index on the column (the primary key has the highest distinction, because all keys are unique)
Scenario of creating an index
Scenario 1: Behind the where field Establishing an index on the field
-- 描述:当where中有多个条件需要进行匹配的时候,那么可以创建联合索引,这样所有的条件都可以使用索引,大大提高了检索的效率 select * from student_info where student_id = 1; -- 当然数据量比较大的时候给where后面的字段添加索引 create index student_id_index on student_info (student_id)
Before adding the index, it took 0.383 seconds, basically traversing the entire table

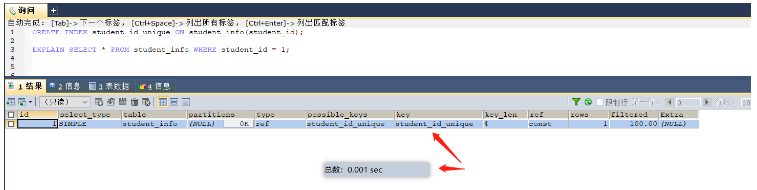
select * from student_info where id = 1001; -- 因为学号是唯一的,所以可以在学号这个字段上添加唯一所用 create index id_unique on student_info(id);On a field with unique constraints You can create a unique index. Although establishing a unique index will have a certain impact on the insert operation (you need to determine whether the newly added data is already in the table), establishing a unique index will significantly improve the efficiency of the query. For example, in the above example, Because a unique index is established, once the student information with ID 1001 is found, there is no need to determine whether there is another student with ID equal to 1001 in the database (there is only one copy), and the information can be returned directly. If no index is established, then A full table scan is requiredScenario 3: Indexes are often created on the fields of group by and order by (because the index itself is sorted, which is equivalent to sorting before the query)
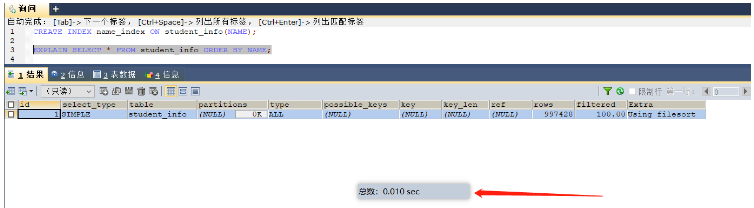
select * from student_info order by name; -- 这里就可以给name字段进行索引的添加 select * from student_info group by class_id; -- 这里就可以给class_id字段添加索引Before indexing, it took 0.501 seconds. All data is sorted in memory.
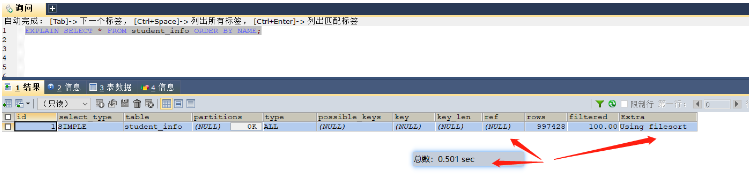 ##After indexing, it took 0.01 seconds
##After indexing, it took 0.01 seconds
 Scenario 4: Add an index to the field after DISTINCT (the index has already sorted the same fields, and the deduplication efficiency is higher)
Scenario 4: Add an index to the field after DISTINCT (the index has already sorted the same fields, and the deduplication efficiency is higher)
select distinct(student_id) from student_info; -- 这里就可以根据student_id字段建立索引 create index student_id_index on student_info;
The index is established, then the default is based on If the index fields are arranged in ascending order, fields with the same value will be arranged together, and deduplication will become simple and efficient
Scenario 5: Establishing join fields in join multi-table joins in large tables Index
SELECT s.course_id,NAME,s.student_id,c.course_name FROM student_info s JOIN course c ON s.`course_id` = c.`course_id` WHERE NAME = 'xiaoyuanhao'; -- 根据大表驱动小表的原则需要在student_info表的course_id字段上建立索引
Before indexing, it took 0.697s. Without indexing
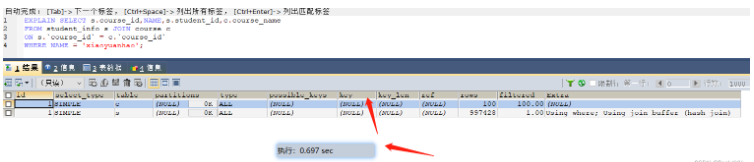 After indexing, it took 0.003s
After indexing, it took 0.003s
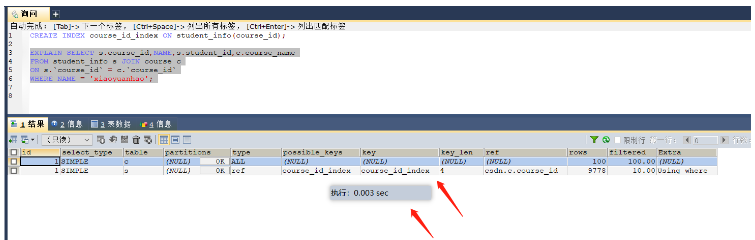 Small tables drive large tables:
Small tables drive large tables:
By traversing the small tables one by one and indexing the connection fields in the large table, you can speed up the query. In this case , each time the course_id in the course table and the student's course_id in the student table are taken out for connection operation, and the course_id is indexed in the student table.
Scenario 6: Use the prefix of the string to create an index
create table shop(address varchar(120) not null); alter table shop add index(address(12)); --这里只是对表中的address的前12个字符建立了索引,而不是整个字符串建立索引
Reasons for prefix indexing:
- Because some strings are very long, if the entire string is indexed, the index will take up a lot of space
- Since the entire string needs to be stored, the data items will be large, the depth of the index tree will be deepened, and the retrieval speed will decrease
- Although it may appear in the index The two strings are the same, but the efficiency of the table return operation based on the primary key is still relatively high
如何确定前缀索引中前缀的长度呢?(也就是如果前缀的长度太短,那么索引的区分度就很低,从多个字符串截取的前缀数据可能都是一样的,但是如果前缀索引的前缀过长,那么前缀索引的优点就消失了)
引入了区别度的概念,select count(distinct left(索引字段,前缀索引长度) / count(*) from xxx),该值越接近1,那么区分度就越明显,那么该索引长度就是所求的前缀索引长度
场景七:在频繁使用的列上建立索引或联合索引(频繁使用的字段应该在索引的左侧)
select * from xiaoyuanhao where age = 18; select * from xiaoyuanhao where age = 19 and sex = 'man'; select * from xiaoyuanhao where age = 10 and sex = 'man' and password = '123456'; -- 在这里实际上就可以建立age,sex,password的联合索引,只需要建立一个索引,这三个查询都是可以使用的 create index age_sex_password_index on xiaoyuanhao(age,sex,password); select * from student_info group by class_id order by name; -- 在这里可以建立class_id和name的联合索引,但是一定要注意索引的顺序,一定是要class_id在前,name在后,因为在select语句中执行的顺序是先group by 之后才是 order by 索引如果索引的字段顺序是相反的,那么就无法使用索引 create index class_id_name_index on student(class_id,name);
索引建立需要符合顺序的原因:
索引字段的顺序如果是错误的,那么索引就会失效,因为索引实际上是排好序的,如果索引建立的时候是现根据name排好序之后在根据class_id进行排序,那么在面对需要先根据class_id排序再根据name排序的业务就无法进行使用
补充:
在select * from xxx where age = 19 and sex = ‘man’ and password = '123456’这里索引建立的顺序不一定是(age,sex,password)因为在实际执行的过程中,优化器会优化执行步骤会按照索引的顺序进行查询,但是group by 和 order by的执行顺序是无法改变的,索引必须严格的按照顺序建立索引,否则索引失效
The above is the detailed content of What are the situations in which MySQL index optimization is suitable for building indexes?. For more information, please follow other related articles on the PHP Chinese website!