
Home >Technology peripherals >AI >An in-depth interpretation of the 3D visual perception algorithm for autonomous driving
An in-depth interpretation of the 3D visual perception algorithm for autonomous driving

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-06-02 15:42:141374browse
For autonomous driving applications, it is ultimately necessary to perceive 3D scenes. The reason is simple. A vehicle cannot drive based on the perception results obtained from an image. Even a human driver cannot drive based on an image. Because the distance of objects and the depth information of the scene cannot be reflected in the 2D perception results, this information is the key for the autonomous driving system to make correct judgments on the surrounding environment.
Generally speaking, the visual sensors (such as cameras) of autonomous vehicles are installed above the vehicle body or on the rearview mirror inside the vehicle. No matter where it is, what the camera gets is the projection of the real world in the perspective view (world coordinate system to image coordinate system). This view is similar to the human visual system and is therefore easily understood by human drivers. But a fatal problem with perspective views is that the scale of objects changes with distance. Therefore, when the perception system detects an obstacle ahead from the image, it does not know the distance of the obstacle from the vehicle, nor does it know the actual three-dimensional shape and size of the obstacle.
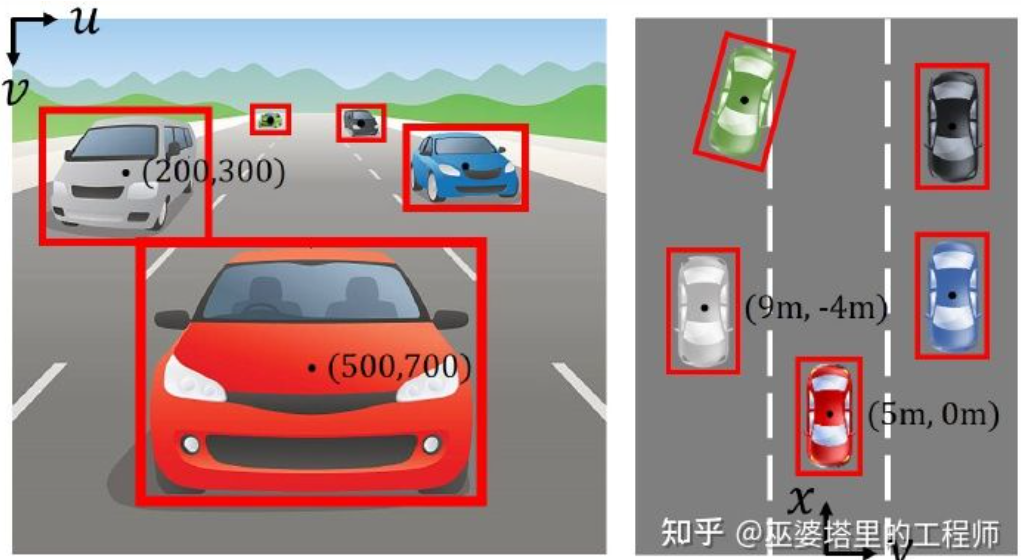
Image coordinate system (perspective view) vs. world coordinate system (bird's eye view) [IPM-BEV ]
One of the most direct ways to obtain information about 3D space is to use LiDAR. On the one hand, the 3D point cloud output by LiDAR can be directly used to obtain the distance and size of obstacles (3D object detection), as well as the depth of the scene (3D semantic segmentation). On the other hand, 3D point clouds can also be fused with 2D images to make full use of the different information provided by the two: the advantage of point clouds is accurate distance and depth perception, while the advantage of images is richer semantic information.
However, LiDAR also has its shortcomings, such as higher cost, difficulty in mass production of automotive-grade products, greater impact from weather, etc. Therefore, 3D perception based solely on cameras is still a very meaningful and valuable research direction. The following sections of this article will introduce in detail the 3D perception algorithms based on single and dual cameras.
#01
Monocular 3D Perception
Perceiving the 3D environment based on a single camera image is an ill problem, but it can Using some geometric constraints and prior knowledge to assist in completing this task, a deep neural network can also be used to learn end-to-end how to predict 3D information from image features.
Object detection

##Single camera 3D object detection ( Picture from M3D-RPN)
##Inverse image transformationAs mentioned earlier, the image is from the 3D coordinates of the real world to 2D Projection of plane coordinates, so a very straightforward idea for 3D object detection from images is to inversely transform the 2D image into 3D world coordinates, and then perform object detection in the world coordinate system. In theory, this is an ill-posed problem, but it can be solved with some additional information (such as depth estimation) or geometric assumptions (such as pixels located on the ground).
BEV-IPM [1] proposes to convert images from perspective view to bird's-eye view (BEV). There are two assumptions here: one is that the road surface is parallel to the world coordinate system and the height is zero, and the other is that the vehicle's own coordinate system is parallel to the world coordinate system. The former is not satisfied when the road surface is not flat, while the latter can be corrected through vehicle attitude parameters (Pitch and Roll), which is actually the Calibration of the vehicle coordinate system and the world coordinate system. Assuming that all pixels in the image have a height of zero in the real world, Homography transformation can be used to convert the image to a BEV view. In the BEV view, a method based on the YOLO network is used to detect the bottom box of the target, which is the rectangle in contact with the road surface. The height of the Bottom Box is zero, so it can be accurately projected onto the BEV view as a GroudTruth to train the neural network. At the same time, the Box predicted by the neural network can also accurately estimate its distance. The assumption here is that the target needs to be in contact with the road surface, which is generally sufficient for vehicle and pedestrian targets.
BEV-IPM ##Another inverse transformation method uses Orthographic Feature Transform (OFT) [2]. The idea is to use CNN to extract multi-scale image features, then transform these image features into BEV views, and finally perform 3D object detection on BEV features. First, it is necessary to construct a 3D grid from the BEV perspective (the grid range of the experiment in this article is 80 meters x 80 meters x 4 meters, and the grid size is 0.5m). Each grid corresponds to an area on the image (defined as a rectangular area for simplicity) through perspective transformation, and the mean value of the image features in this area is used as the feature of the grid, thus obtaining the 3D grid characteristics. In order to reduce the amount of calculation, the 3D grid features are compressed (weighted average) in the height dimension to obtain the 2D grid features. The final object detection is performed on 2D mesh features. The projection of 3D grids to 2D image pixels does not correspond one-to-one. Multiple grids will correspond to adjacent image areas, resulting in ambiguity in grid features. Therefore, it is also necessary to assume that the objects to be detected are all on the road, and the height range is very narrow. Therefore, the 3D grid used in the experiment is only 4 meters high, which is enough to cover vehicles and pedestrians on the ground. But if you want to detect traffic signs, this method of assuming that objects are close to the ground is not applicable. 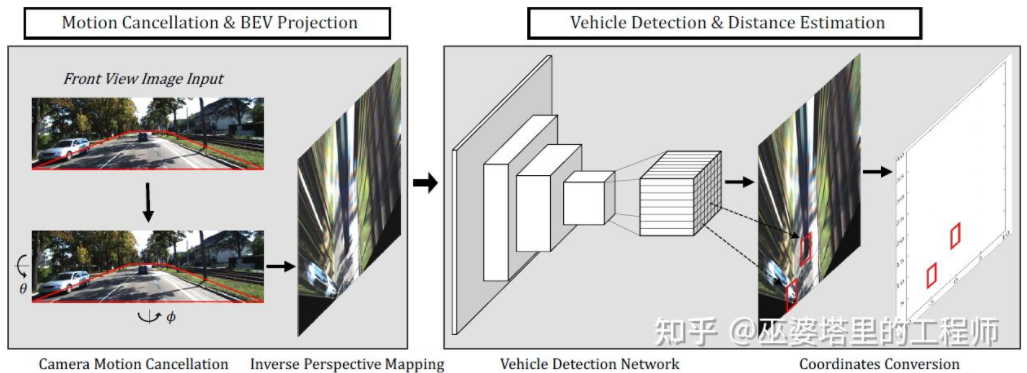
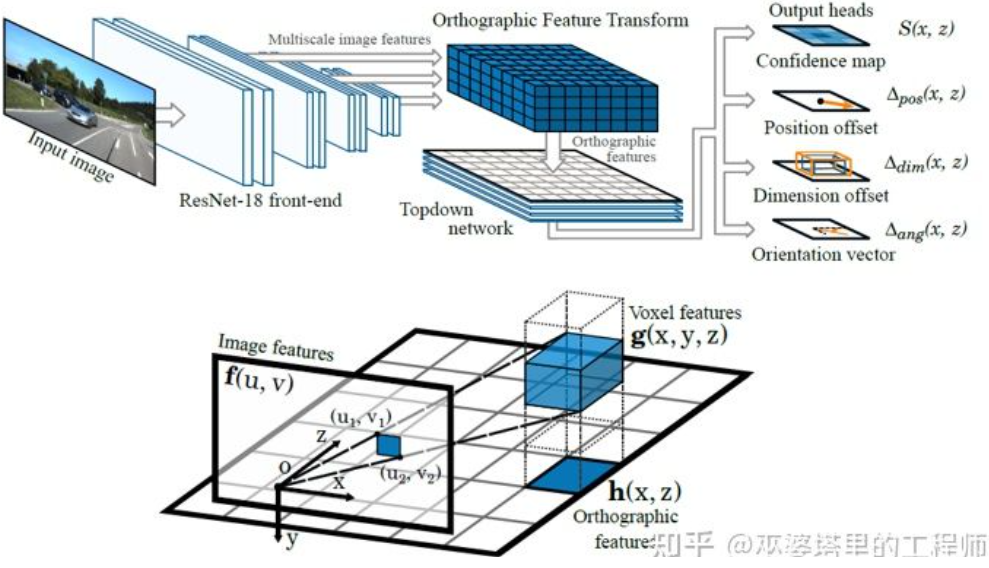
Orthographic Feature Transform
The above Both methods are based on the assumption that the object is located on the ground. In addition, another idea is to use the results of depth estimation to generate pseudo point cloud data. One typical work is Pseudo-LiDAR [3]. The results of depth estimation are generally treated as additional image channels (similar to RGB-D data), and image-based object detection networks are used directly to generate 3D object bounding boxes. The author pointed out in the article that the main reason why the accuracy of 3D object detection based on depth estimation is much worse than that of LiDAR-based methods is not that the accuracy of depth estimation is insufficient, but that there is a problem with the data representation method. First, on the image data, the area of distant objects is very small, which makes the detection of distant objects very inaccurate. Secondly, the depth difference between adjacent pixels in depth may be very large (such as at the edge of an object). In this case, there will be problems using convolution operations to extract features. Taking these two points into account, the author proposed to convert the input image into point cloud data similar to that generated by LiDAR based on the depth map, and then use point cloud and image fusion algorithms (such as AVOD and F-PointNet) to detect 3D objects. The Pseudo-LiDAR method does not rely on a specific depth estimation algorithm, and any depth estimation from monocular or binocular can be used directly. Through this special data representation method, Pseudo-LiDAR can increase the accuracy of object detection from 22% to 74% within a range of 30 meters.

Pseudo-LiDAR
Compared with real LiDAR point cloud , the Pseudo-LiDAR method still has a certain gap in the accuracy of 3D object detection. This is mainly due to the insufficient accuracy of depth estimation (binocular is better than monocular), especially the depth estimation error around the object. It has a great impact on detection. Therefore, Pseudo-LiDAR has also undergone many expansions since then. Pseudo-LiDAR [4] uses low-wireline LiDAR to enhance virtual point clouds. Pseudo-Lidar End2End[5] uses instance segmentation to replace the object frame in F-PointNet. RefinedMPL [6] only generates virtual point clouds on foreground points, reducing the number of point clouds to 10% of the original, which can effectively reduce the number of false detections and the calculation amount of the algorithm.
Key points and 3D models
In autonomous driving applications, the size and shape of many targets (such as vehicles and pedestrians) that need to be detected It is relatively fixed and known. These prior knowledge can be used to estimate the 3D information of the target.
DeepMANTA[7] is one of the pioneering works in this direction. First, traditional image object detection algorithms such as Faster RNN are used to obtain the 2D object frame and also detect key points on the vehicle. Then, these 2D object frames and key points are matched with various 3D vehicle CAD models in the database, and the model with the highest similarity is selected as the output of 3D object detection.
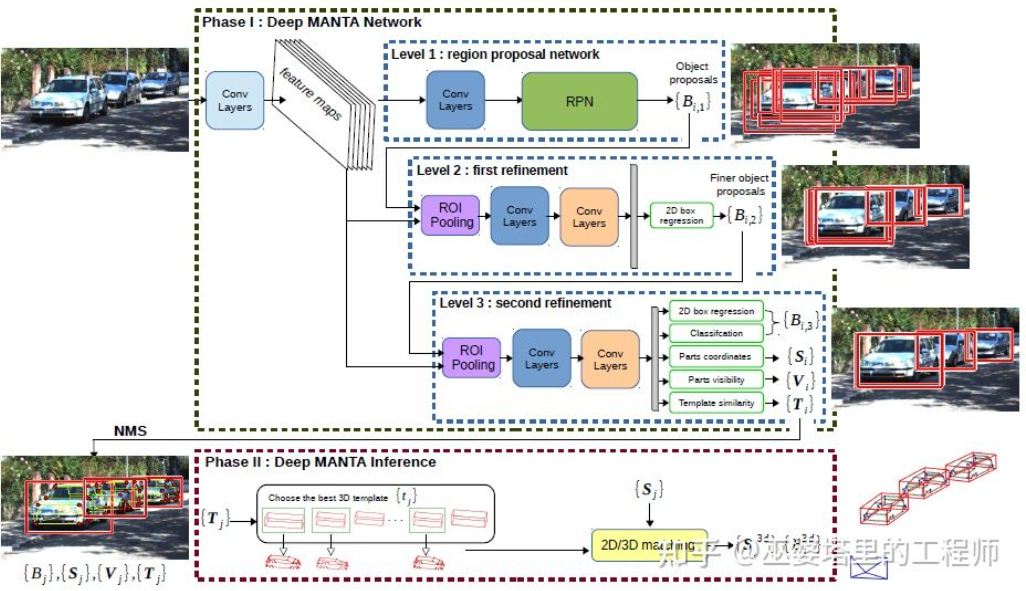
Deep MANTA
3D-RCNN[8] proposed to use Inverse -Graphics method, based on images, to recover the 3D shape and pose of each target in the scene. The basic idea is to start from the 3D model of the target and find the model that best matches the target in the image through parameter search. These 3D models usually have many control parameters and a large search space. Therefore, traditional methods do not have good results in searching for optimal results in high-dimensional parameter spaces. 3D-RCNN uses PCA to reduce the dimensionality of the parameter space (10-D), and uses a deep neural network (R-CNN) to predict the low-dimensional model parameters of each target. The predicted model parameters can be used to generate a two-dimensional image or depth map of each target, and the Loss obtained by comparing it with the GroudTruth data can be used to guide the learning of the neural network. This Loss is called Render-and-Compare Loss and is implemented based on OpenGL. The 3D-RCNN method requires a lot of input data, and the design of Loss is relatively complex, making it difficult to implement in engineering.
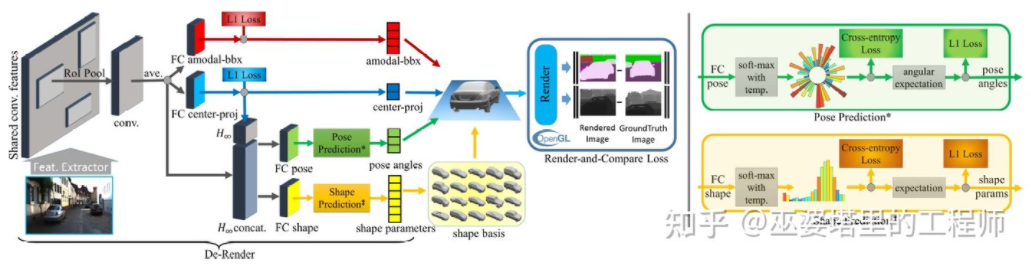
##3D-RCNN
MonoGRNet[ 9] proposed to divide monocular 3D object detection into four steps, which are used to predict the 2D object frame, the depth of the object's 3D center, the 2D projection position of the object's 3D center and the 3D positions of the eight corner points. First, the predicted 2D object frame in the image is operated by ROIAlign to obtain the visual characteristics of the object. These features are then used to predict the depth of the object's 3D center and the 2D projected position of the 3D center. With these two pieces of information, the position of the 3D center point of the object can be obtained. Finally, the relative positions of the eight corner points are predicted based on the position of the 3D center. MonoGRNet can be thought of as using only the center of the object as the key point, and the matching of 2D and 3D is the calculation of point distance. MonoGRNetV2 [10] extends the center point to multiple key points and uses a 3D CAD object model for depth estimation, which is very similar to the DeepMANTA and 3D-RCNN introduced previously.
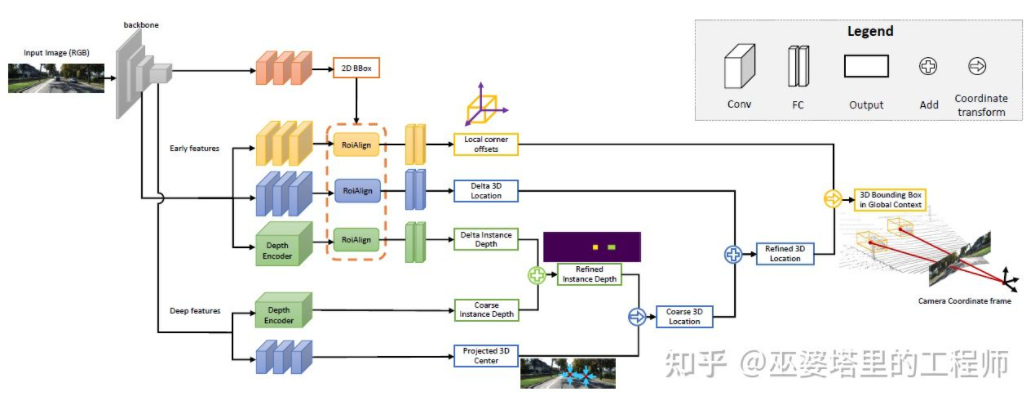
MonoGRNet
Monoloco[11] mainly solves the 3D detection of pedestrians question. Pedestrians are non-rigid objects with more diverse postures and deformations, making them more challenging than vehicle detection. Monoloco is also based on key point detection, and the relative 3D position of key points a priori can be used for depth estimation. For example, the distance of a pedestrian is estimated based on the length of 50 centimeters from the pedestrian's shoulder to the hip. The reason for using this length as a benchmark is that this part of the human body can produce the least deformation and can be used for depth estimation with the highest accuracy. Of course, other key points can also be used as auxiliaries to complete the task of in-depth estimation. Monoloco uses a multi-layer fully connected network to predict the distance of a pedestrian from the location of key points, while also giving the uncertainty of the prediction.
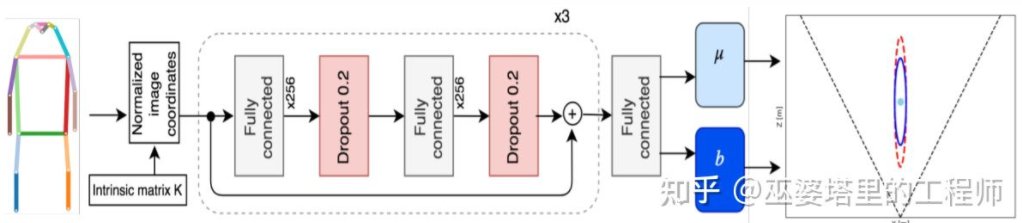
Monoloco
To summarize, the above methods all start from 2D images Key points are extracted and matched with the 3D model to obtain the 3D information of the target. This type of method assumes that the target has a relatively fixed shape model, which is generally satisfactory for vehicles, but is relatively difficult for pedestrians. In addition, this type of method requires marking multiple key points on the 2D image, which is also very time-consuming.
2D/3D geometric constraints
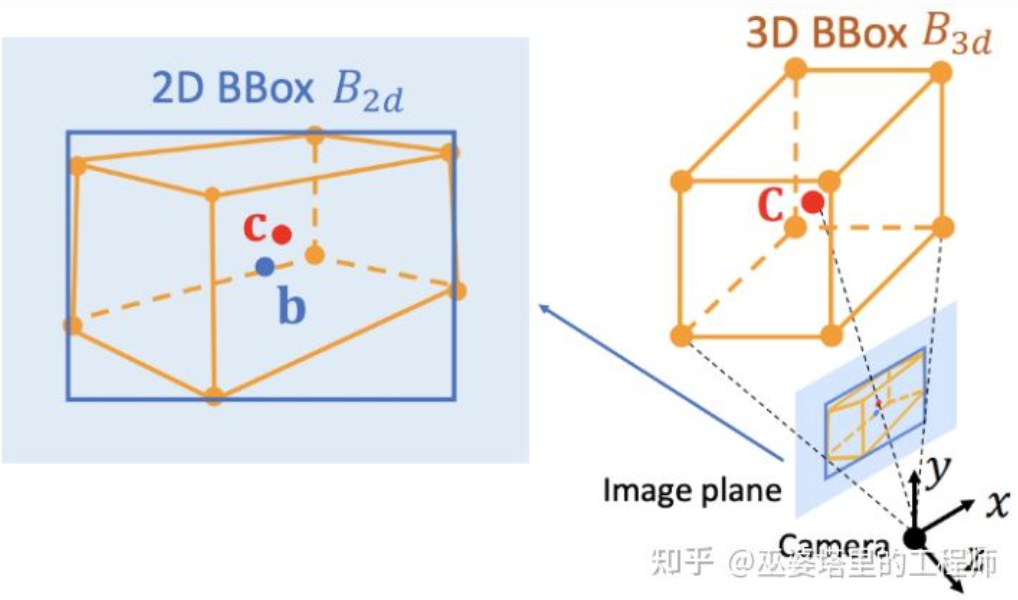
Deep3DBox[12] is an early and representative work in this direction. The 3D object frame requires 9-dimensional variables to represent, namely center, size and orientation (3D orientation can be simplified to Yaw, so it becomes a 7-dimensional variable). Image 2D object detection can provide a 2D object frame containing 4 known variables (2D center and 2D size), which is not enough to solve variables with 7 or 9 degrees of freedom. Among these three sets of variables, size and orientation are relatively closely related to visual features. For example, the 3D size of an object is closely related to its category (pedestrian, bicycle, car, bus, truck, etc.), and the object category can be predicted through visual features. For the 3D position of the center point, it is difficult to predict purely through visual features due to the ambiguity caused by perspective projection. Therefore, Deep3DBox proposes to first use image features within the 2D object box to estimate object size and orientation. Then, a 2D/3D geometric constraint is used to solve the 3D position of the center point. This constraint is that the projection of the 3D object frame on the image is closely surrounded by the 2D object frame, that is, at least one corner point of the 3D object frame can be found on each side of the 2D object frame. Through the previously predicted size and orientation, combined with the camera's Calibration parameters, the 3D position of the center point can be solved.
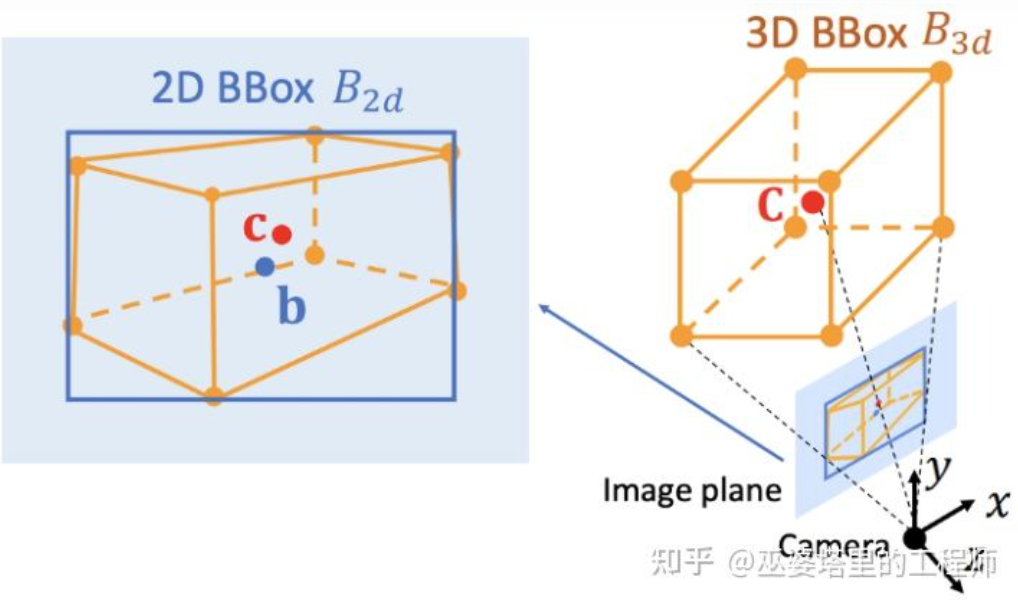
Geometric constraints between 2D and 3D object frames (picture from reference [9])
This method of utilizing 2D/3D constraints requires very accurate 2D object frame detection. Under the framework of Deep3DBox, a small error on the 2D object frame may cause the failure of the 3D object frame prediction. The first two stages of Shift R-CNN [13] are very similar to Deep3DBox. They predict the 3D size and orientation through 2D object boxes and visual features, and then solve the 3D position through geometric constraints. However, Shift R-CNN adds a third stage, which combines the 2D object frame, 3D object frame and camera parameters obtained in the first two stages as input, and uses a fully connected network to predict a more accurate 3D position.
##Shift R-CNN
Using 2D/3D geometric constraints At that time, the above methods all obtain the 3D position of the object by solving a set of super-constrained equations, and this process is used as a post-processing step and is not within the neural network. The first and third stages of Shift R-CNN are also trained separately. MVRA [14] built the solution process of this super-constrained equation into a network, and designed IoU Loss in image coordinates and L2 Loss in BEV coordinates to measure the error of object frame and distance estimation respectively to assist in completing end-to-end training. . In this way, the quality of the object's 3D position prediction will also have a feedback effect on the previous 3D size and orientation prediction.
Directly generate a 3D object frame
The three methods introduced before all start from 2D images, and some transform the images into BEV views , some detect 2D key points and match them with 3D models, and others use geometric constraints of 2D and 3D object frames. In addition, there is another type of method that starts from dense 3D object candidates and scores all candidate frames based on the features on the 2D image. The candidate frame with a high score is the final output. This strategy is somewhat similar to the traditional Sliding Window method in object detection.
Mono3D[15] is a representative of this type of method. First, a dense 3D candidate box is generated based on the target's prior position (z coordinate is on the ground) and size. On the KITTI dataset, approximately 40K (vehicles) or 70K (pedestrians and bicycles) candidate boxes are generated per frame. After these 3D candidate boxes are projected to image coordinates, they are scored by features on the 2D image. These features come from semantic segmentation, instance segmentation, context, shape, and location prior information. All these features are combined to score the candidate boxes, and then the one with a higher score is selected as the final candidate. These candidates are then passed through CNN for the next round of scoring to obtain the final 3D object frame.
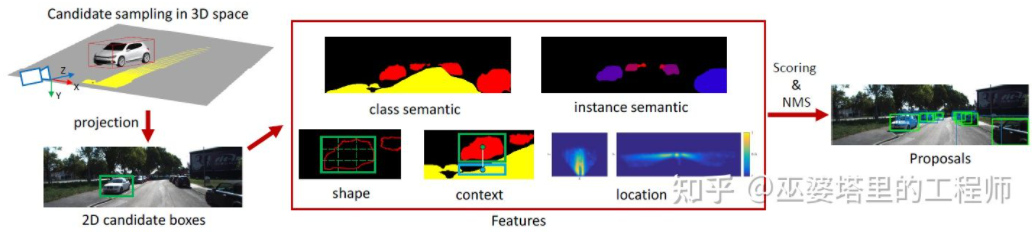
Mono3D
M3D-RPN[16] is an Anchor-based method. This method defines 2D and 3D Anchors, which represent 2D and 3D object frames respectively. The 2D Anchor is obtained through dense sampling on the image, while the parameters of the 3D Anchor are determined based on the prior knowledge obtained from the training set data. Specifically, each 2D Anchor is matched with the 2D object frame marked in the image according to IoU, and the mean value of the corresponding 3D object frame is used to define the parameters of the 3D Anchor. It is worth mentioning that both standard convolution operations (with spatial invariance) and Depth-Aware convolution are used in M3D-RPN. The latter divides the rows (Y coordinates) of the image into multiple groups. Each group corresponds to a different scene depth and is processed by different convolution kernels.
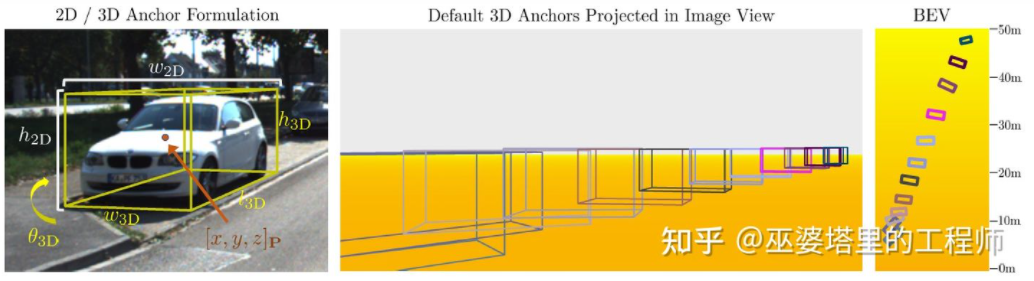
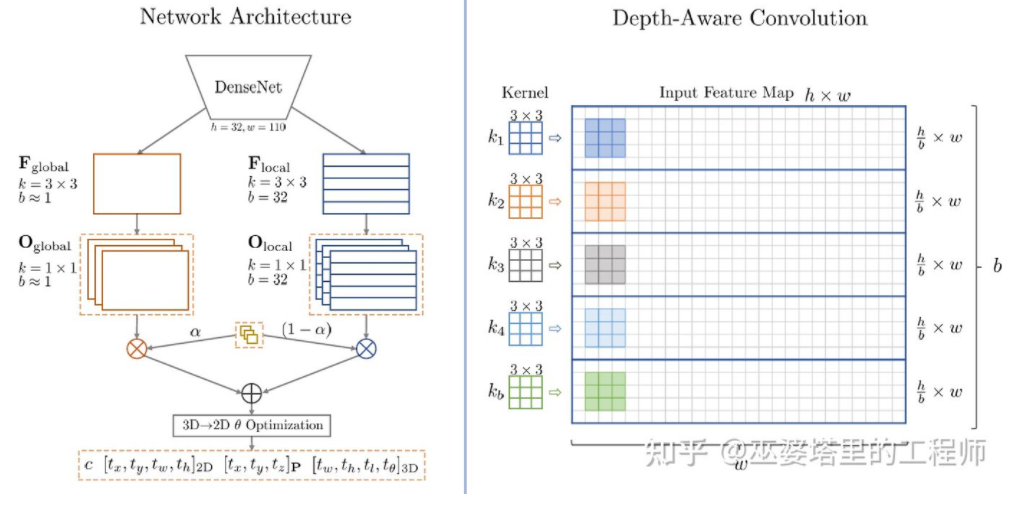
## in M3D-RPN Anchor design and Depth-Aware convolution
Although some prior knowledge is used, Mono3D and M3D-RPN are still based on dense sampling when generating object candidates or Anchors, so The amount of calculation required is very large, and the practicality is greatly affected. Some subsequent methods proposed using detection results on two-dimensional images to further reduce the search space.
TLNet[17] places Anchors densely on the two-dimensional plane. Anchor intervals are 0.25 meters, orientations are 0 degrees and 90 degrees, and sizes are the average of the targets. The two-dimensional detection results on the image form multiple viewing cones in the three-dimensional space. Through these viewing cones, a large number of anchors on the background can be filtered out, thereby improving the efficiency of the algorithm. The filtered Anchor is projected onto the image, and the features obtained after ROI Pooling are used to further refine the parameters of the 3D object frame.
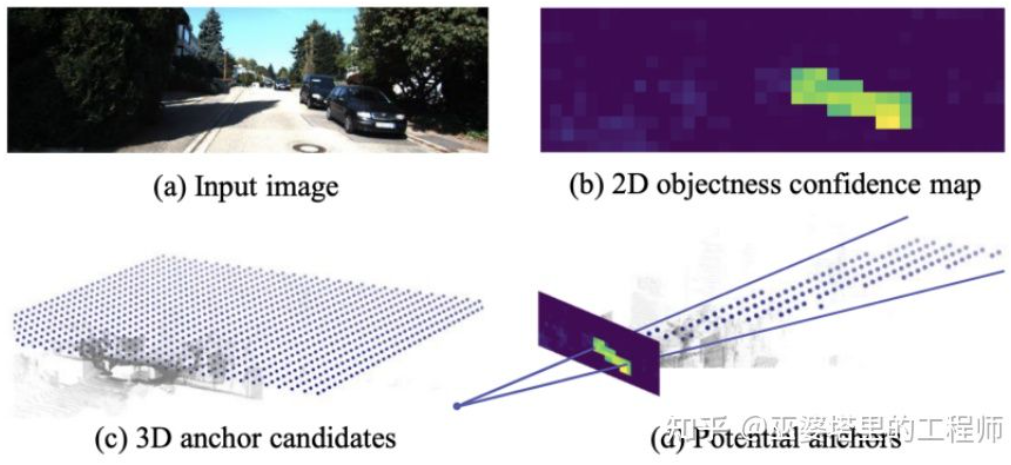
##TLTNet
SS3D[18] A more efficient single-stage detection is used, and a network similar to the CenterNet structure is used to directly output a variety of 2D and 3D information from the image, such as object category, 2D object frame, and 3D object frame. It should be noted that the 3D object frame here is not a general 9D or 7D representation (this representation is difficult to predict directly from the image), but a 2D representation that is easier to predict from the image and contains more redundancy, including distance. (1-d), orientation (2-d, sin and cos), size (3-d), image coordinates of 8 corner points (16-d). Coupled with the 4-D representation of the 2D object box, the total is 26D features. All these features are used to predict the 3D object frame. The prediction process is actually to find a 3D object frame that best matches the 26D features. A special point is that this solution process is performed inside the neural network, so it must be differentiable. This is also a major highlight of this article. Benefiting from the simple structure and implementation, SS3D can run at a speed of 20FPS.
SS3D##FCOS3D[19] is also a single-stage detection method, but more concise than SS3D. The center of the 3D object frame is projected onto the 2D image to obtain the 2.5D center (X, Y, Depth), which is used as one of the goals of regression. In addition, the regression targets also include 3D size and orientation. The orientation here is represented by the combination of angle (0-pi) and heading.
##SMOKE[20] A similar idea was also proposed to directly predict 2D and 3D information from images through a CenterNet-like structure. The 2D information includes the projection position of the object's key points (center point and corner point) on the image, and the 3D information includes the depth, size and orientation of the center point. Through the image position and depth of the center point, the 3D position of the object can be recovered. The 3D position of each corner point can then be restored through the 3D size and orientation.
The idea of the single-stage networks introduced above is to directly return 3D information from the image, without the need for complex pre-processing (such as image inverse transformation) and post-processing (such as 3D model matching), nor Precise geometric constraints (for example, at least one corner point of the 3D object frame can be found on each edge of the 2D object frame). These methods only use a small amount of prior knowledge, such as the average actual size of various types of objects, and the resulting correspondence between the size and depth of 2D objects. These prior knowledge define the initial values of the 3D parameters of the object, and the neural network only needs to regress the deviation from the actual value, which greatly reduces the search space and therefore reduces the difficulty of network learning.
Depth Estimation
The previous section introduced the representative method of monocular 3D object detection. The idea is based on the early image transformation , 3D model matching and 2D/3D geometric constraints, to the recent prediction of 3D information directly from images. This change in thinking largely stems from the progress of convolutional neural networks in depth estimation. Most of the single-stage 3D object detection networks introduced before include a depth estimation branch. The depth estimation here is only at the sparse target level rather than the dense pixel level, but it is sufficient for object detection.
In addition to object detection, autonomous driving perception also has another important task, which is semantic segmentation. The most direct way to extend semantic segmentation from 2D to 3D is to use a dense depth map, so that the semantic and depth information of each pixel is available.
Based on the above two points, monocular depth estimation plays a very important role in 3D perception tasks. By analogy from the introduction of 3D object detection methods in the previous section, fully convolutional neural networks can also be used for dense depth estimation. Below we will introduce the current development status of this direction.
The input of monocular depth estimation is an image, and the output is also an image (generally the same size as the input), and each pixel value on it corresponds to the scene depth of the input image. This task is somewhat similar to image semantic segmentation, except that semantic segmentation outputs the semantic classification of each pixel. Of course, the input can also be a video sequence, using additional information brought by camera or object motion to improve the accuracy of depth estimation (corresponding to video semantic segmentation).
As mentioned earlier, predicting 3D information from 2D images is an ill-posed problem, so traditional methods will use geometric information, motion information and other clues to predict pixels through manually designed features depth. Similar to semantic segmentation, two methods, superpixel (SuperPixel) and conditional random field (CRF), are often used to improve the accuracy of estimation. In recent years, deep neural networks have made breakthrough progress in various image perception tasks, and depth estimation is certainly no exception. A large amount of work has shown that deep neural networks can learn superior features through training data than hand-designed features. This section mainly introduces this method based on supervised learning. Some other unsupervised learning ideas, such as using binocular disparity information, monocular dual pixel (Dual Pixel) difference information, video motion information, etc., will be introduced later.
An early representative work in this direction is the method based on global and local clue fusion proposed by Eigen et al.[21]. The ambiguity of monocular depth estimation mainly comes from the global scale. For example, the article mentioned that a real room and a toy room may appear to be very different in image, but the actual depth of field is very different. Although this is an extreme example, variations in room and furniture dimensions still exist in real datasets. Therefore, this method proposes to perform multi-layer convolution and downsampling on the image to obtain the descriptive features of the entire scene, and use this to predict the global depth. Then, another local branch (relatively higher resolution) is used to predict the depth of the local image. Here the global depth will be used as an input to the local branch to assist in the prediction of local depth.
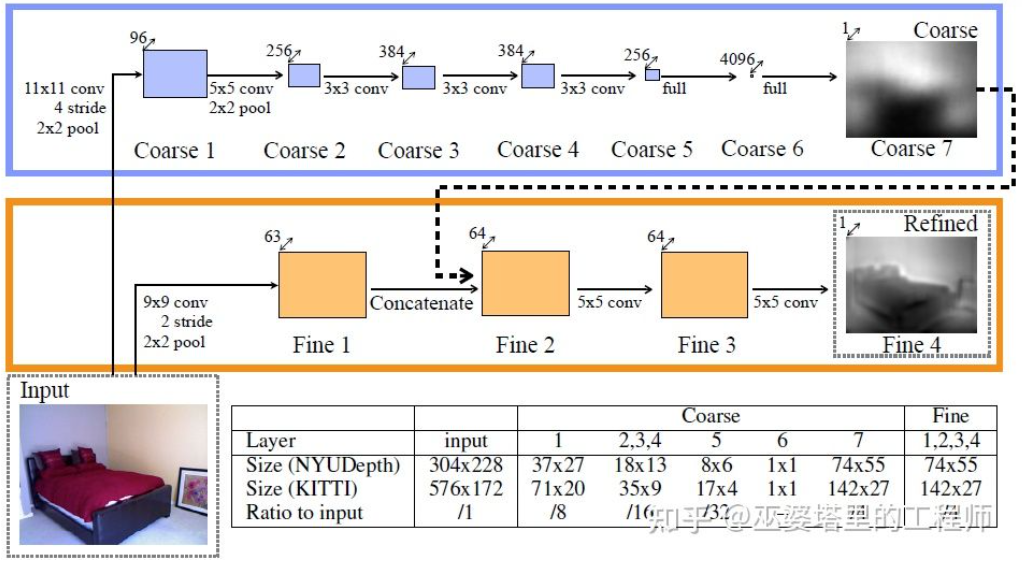
##Global and local information fusion [21]
Literature [22] further proposes to use multi-scale feature maps output by convolutional neural networks to predict depth maps of different resolutions (there are only two resolutions in [21]). These feature maps of different resolutions are fused through continuous MRF to obtain a depth map corresponding to the input image.
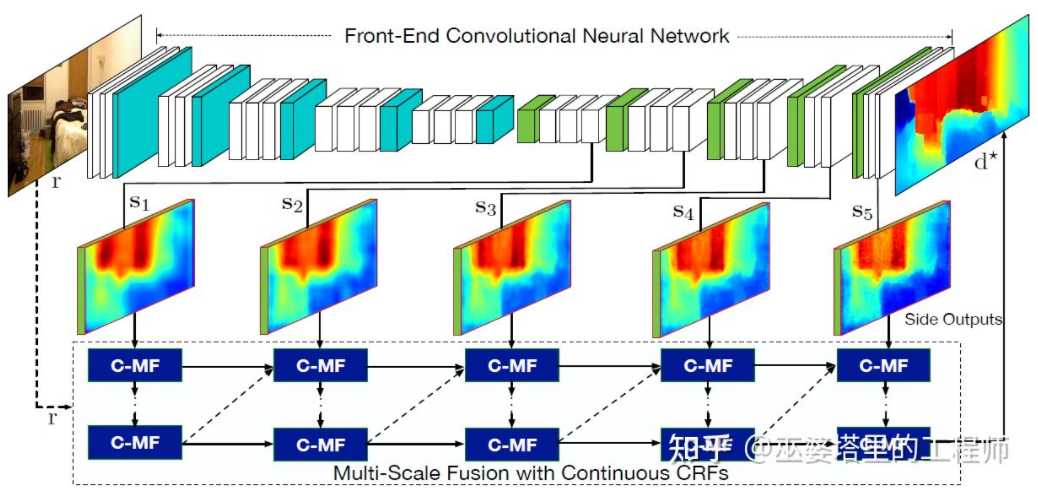
Multi-scale information fusion[22]
The above two articles They all use convolutional neural networks to return depth maps. Another idea is to convert the regression problem into a classification problem, that is, to divide the continuous depth values into discrete intervals, and each interval is regarded as a category. The representative work in this direction is DORN [23]. The neural network in the DORN framework is also a coding and decoding structure, but there are some differences in details, such as using fully connected layer decoding, dilated convolution for feature extraction, etc.
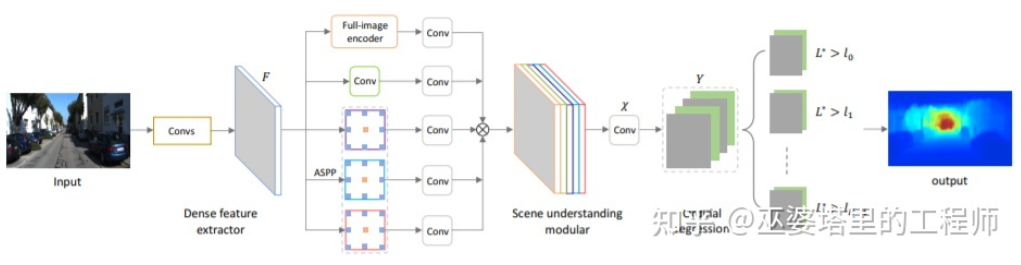
DORN Deep Classification
mentioned earlier Note that depth estimation has similarities with semantic segmentation tasks, so the size of the receptive field is also very important for depth estimation. In addition to the pyramid knots and dilated convolutions mentioned above, the recently popular Transformer structure has a global receptive field and is therefore very suitable for such tasks. In the literature [24], it is proposed to use Transformer and multi-scale structure to simultaneously ensure the local accuracy and global consistency of prediction.
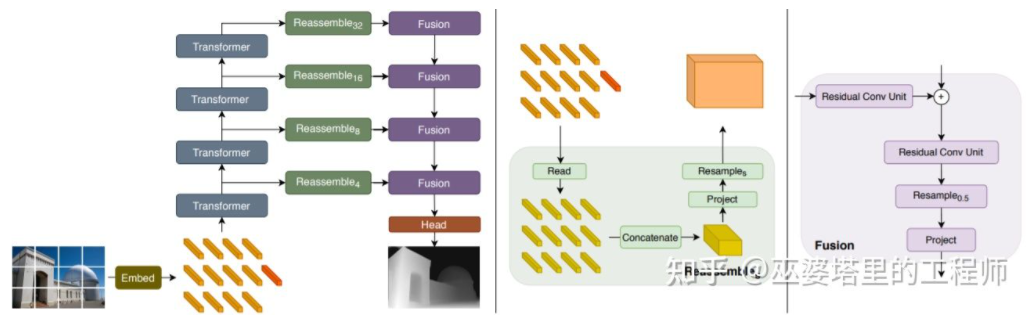
##Transformer for Dense Prediction
02Binocular 3D Perception
Although prior knowledge and contextual information in images can be utilized, the accuracy based on monocular 3D perception is not completely satisfactory. Especially when using deep learning strategies, the accuracy of the algorithm is very dependent on the size and quality of the data set. For scenes that have not appeared in the data set, the algorithm will have large deviations in depth estimation and object detection.
Binocular vision can resolve the ambiguity caused by perspective transformation, so in theory it can improve the accuracy of 3D perception. However, the binocular system has relatively high requirements in terms of hardware and software. In terms of hardware, two accurately registered cameras are required, and the accuracy of the registration must be ensured during vehicle operation. In terms of software, the algorithm needs to process data from two cameras at the same time. The calculation complexity is high, and it is even more difficult to ensure the real-time performance of the algorithm.
Generally speaking, compared with monocular visual perception, there are relatively few works on binocular visual perception. Several typical articles will be selected for introduction below. In addition, there are some works based on multi-purpose, but biased towards the system application level, such as the 360° perception system demonstrated by Tesla at AI Day.
Object detection
3DOP[25] first uses images from dual cameras to generate depth maps, and then converts the depth maps into point clouds. Quantize it into a mesh data structure and use this as input to generate 3D object candidates. Some intuition and prior knowledge are used when generating candidates. For example, the density of the point cloud in the candidate box is large enough, the height is consistent with the actual object and the height difference from the point cloud outside the box is large enough, and the overlap between the candidate box and Free Space is sufficient. Small. Through these conditions, approximately 2K 3D object candidates are finally sampled in 3D space. These candidates are mapped to 2D images, and feature extraction is performed through ROI Pooling to predict the object category and refine the object frame. The image input here can be an RGB image from a camera, or a depth map.
In general, this is a two-stage detection method. The first stage uses depth information (point cloud) to generate object candidates, and the second stage uses image information (or depth) for further refinement. Theoretically, the first stage of point cloud generation can also be replaced by LiDAR, so the author conducted experimental comparisons. The advantage of LiDAR is that the distance measurement is accurate, so it works better for small objects, partially obscured objects and distant objects. The advantage of binocular vision is that the point cloud density is high, so it works better when there is less obstruction at close range and the object is relatively large. Of course, without considering cost and computational complexity, the best results will be obtained by integrating the two.
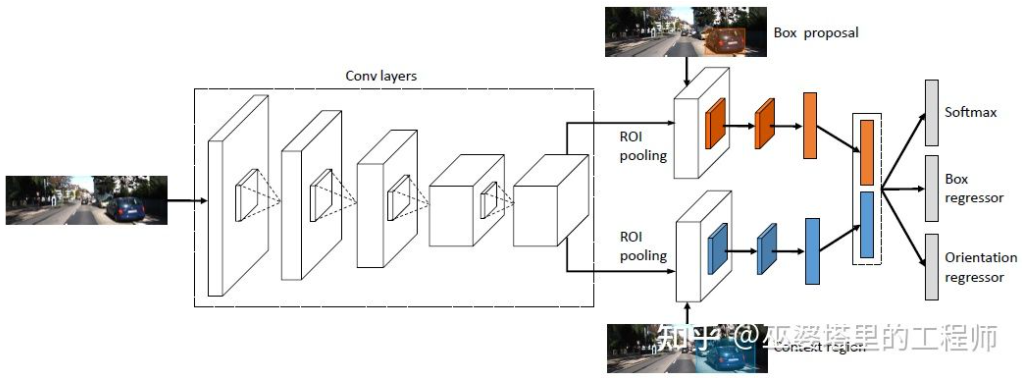
##3DOP
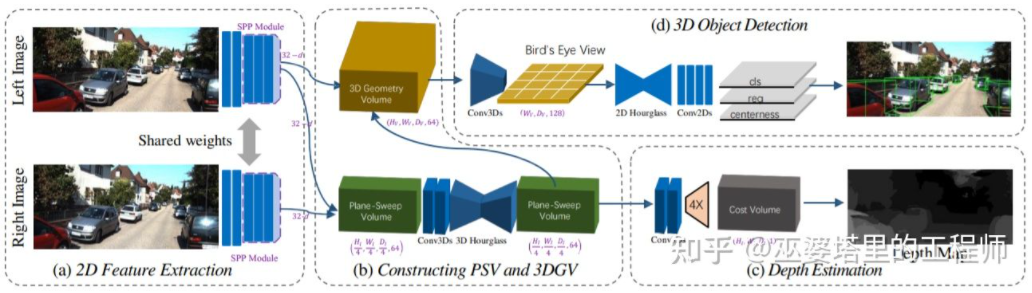
##3DOP is the same as the Pseudo- introduced in the previous section LiDAR [3] has a similar idea, converting dense depth maps (from monocular, binocular or even low-line-count LiDAR) into point clouds, and then applying algorithms in the field of point cloud object detection.Estimate the depth map from the image, then generate the point cloud from the depth map, and finally apply the point cloud object detection algorithm. Each step of this process is performed separately and cannot be carried out end-to-end. train. DSGN [26] proposed a single-stage algorithm, starting from the left and right images, using an intermediate representation such as Plane-Sweep Volume to generate a 3D representation in the BEV view, and simultaneously perform depth estimation and object detection. All steps of this process are differentiable and therefore can be trained end-to-end.
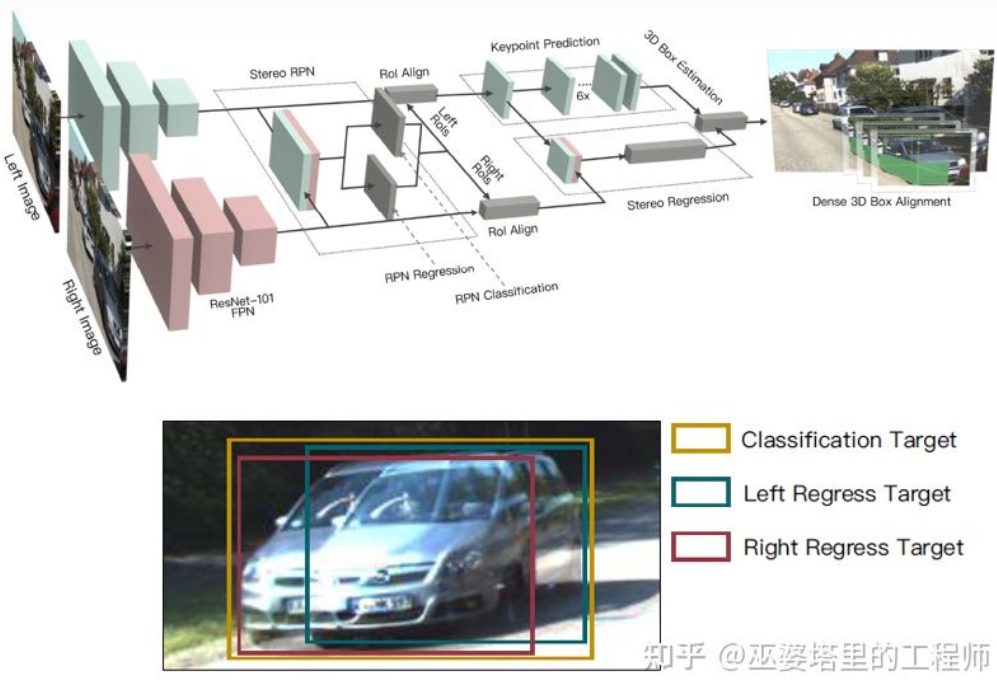
The depth map is a A dense representation, in fact, for object learning, it is not necessary to obtain depth information at all positions of the scene, but only needs to estimate the position of the object of interest. Similar ideas were mentioned before when introducing the monocular algorithm. Stereo R-CNN [27] does not estimate the depth map, but stacks the feature maps from two cameras together under the framework of RPN to generate object candidates. The key here to associate the information from the left and right cameras together is the change in the annotation data. As shown in the figure below, in addition to the left and right label boxes, a Union of the left and right label boxes is also added. An Anchor whose IoU exceeds 0.7 with either left or right box is used as a Positive sample, and an Anchor whose IoU is less than 0.3 with the Union box is used as a Negative sample. Positive's Anchor will return the position and size of the left and right label boxes at the same time. In addition to the object frame, this method also uses corner points as an aid. With all this information the 3D object frame can be restored.
Yes Dense depth estimation of the entire scene can even have a bad impact on object detection. For example, due to the overlap of the object edge with the background, the depth estimation deviation is large, and the large depth range of the entire scene will also affect the speed of the algorithm. Therefore, similar to Stereo RCNN, it is also proposed in [28] to estimate the depth only at the object of interest and only generate point clouds on the object. These object-centered point clouds are finally used to predict the 3D information of the object.
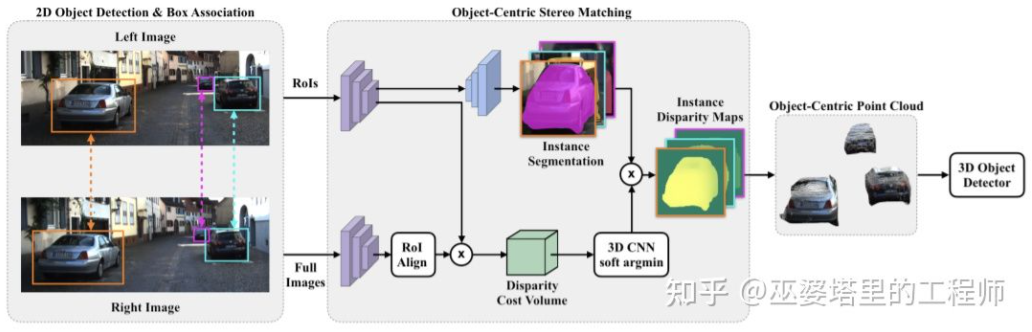 ##Object-Centric Stereo Matching
##Object-Centric Stereo Matching
Depth estimation
Similar to the monocular perception algorithm, depth estimation is also a key step in binocular perception. Judging from the introduction to binocular object detection in the previous section, many algorithms use depth estimation, including scene-level depth estimation and object-level depth estimation. The following is a brief review of the basic principles of binocular depth estimation and several representative works.
The principle of binocular depth estimation is actually very simple. It is based on the distance d between the same 3D point on the left and right images (assuming that the two cameras maintain the same height, so only Consider the distance in the horizontal direction), the focal length f of the camera, and the distance B (baseline length) between the two cameras to estimate the depth of the 3D point.
In the binocular system, f and B are fixed, so only the distance d, which is the parallax, needs to be estimated. For each pixel, all you need to do is find the matching point in the other image. The range of distance d is limited, so the matching search range is also limited. For each possible d, the matching error at each pixel can be calculated, so a three-dimensional error data is obtained, called the Cost Volume. When calculating the matching error, the local area near the pixel is generally considered. One of the simplest methods is to sum the differences of all corresponding pixel values in the local area:
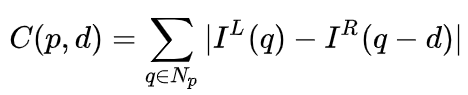

MC-CNN [29] formalizes the matching process as calculating the similarity of two image patches, and Features of image patches are learned through neural networks. By labeling the data, a training set can be constructed. At each pixel, a positive sample and a negative sample are generated, each sample being a pair of image patches. The positive samples are two image blocks from the same 3D point (same depth), and the negative samples are image blocks from different 3D points (different depths). There are many choices for negative samples. In order to maintain a balance between positive and negative samples, only one is randomly sampled. With positive and negative samples, a neural network can be trained to predict similarity. The core idea here is to use supervision signals to guide the neural network to learn image features suitable for matching tasks.
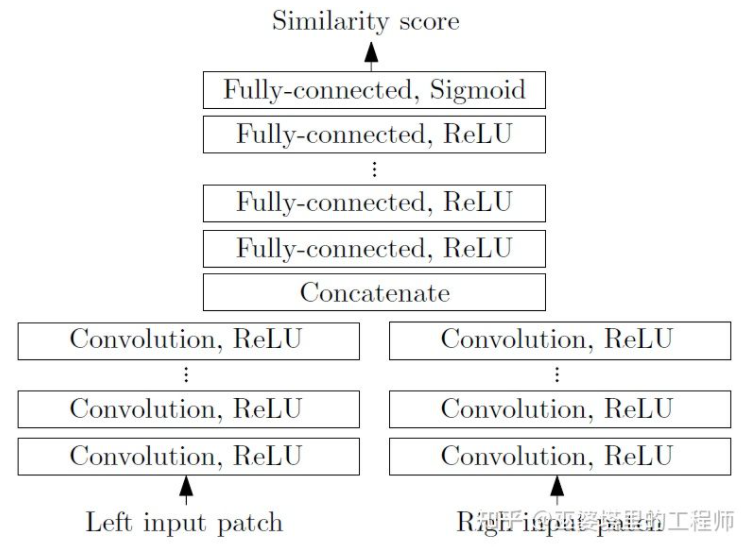
##MC-CNN
MC- Net has two main shortcomings: 1) The calculation of Cost Volume relies on local image blocks, which will cause larger errors in some areas with less texture or repeated patterns; 2) The post-processing steps rely on manual design. It takes a lot of time and is difficult to guarantee optimality. GC-Net[30] has improved on these two points. First, multi-layer convolution and downsampling operations are performed on the left and right images to better extract semantic features. For each disparity level (in pixels), the left and right feature maps are aligned (pixel offset) and then spliced to obtain the feature map of that disparity level. The feature maps of all disparity levels are merged together to obtain the 4D Cost Volume (height, width, disparity, features). Cost Volume only contains information from a single image, and there is no interaction between images. Therefore, the next step is to use 3D convolution to process the Cost Volume, so that the relevant information between the left and right images and the information between different disparity levels can be extracted simultaneously. The output of this step is the 3D Cost Volume (height, width, parallax). Finally, we need to find Argmin in the disparity dimension to obtain the optimal disparity value, but the standard Argmin cannot be derived. Soft Argmin is used in GC-Net to solve the derivation problem, so that the entire network can be trained end-to-end.
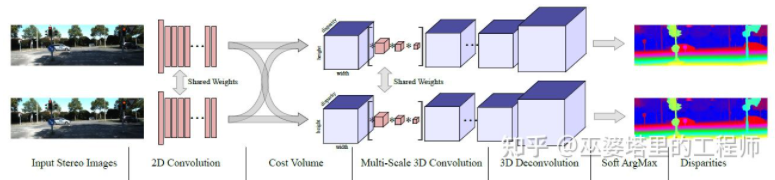
##GC-Net
PSMNet[ 31] is very similar to the structure of GC-Net, but has been improved in two aspects: 1) using a pyramid structure and atrous convolution to extract multi-resolution information and expand the receptive field. Thanks to the fusion of global and local features, the estimation of Cost Volume is also more accurate. 2) Use multiple superimposed Hour-Glass structures to enhance 3D convolution. The utilization of global information is further enhanced. In general, PSMNet has made improvements in the utilization of global information, making disparity estimation more dependent on context information at different scales rather than pixel-level local information.
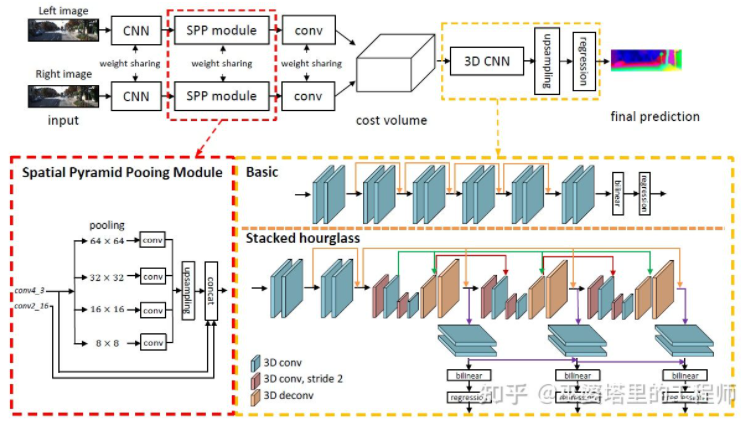
PSMNet In Cost Volume, the disparity level is discrete (in pixels). What the neural network learns is the Cost distribution at these discrete points, and the extreme points of the distribution correspond to the current position. Parallax value. However, the parallax (depth) value should actually be continuous, and using discrete points to estimate it will bring errors. The concept of continuous estimation is proposed in CDN [32]. In addition to the distribution of discrete points, the offset at each point is also estimated. The discrete points and offsets together form a continuous disparity estimate. 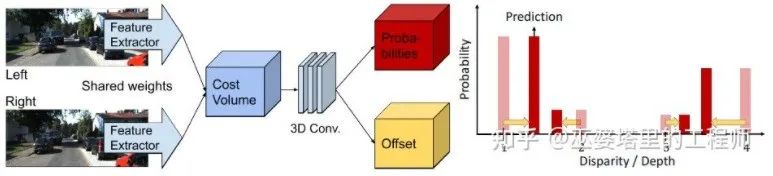
CDN
The above is the detailed content of An in-depth interpretation of the 3D visual perception algorithm for autonomous driving. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology