
Home >Database >Mysql Tutorial >How to make spark sql support update operation when writing mysql
How to make spark sql support update operation when writing mysql

- PHPzforward
- 2023-06-02 15:19:211921browse
In addition to supporting: Append, Overwrite, ErrorIfExists, Ignore; it also supports update operations
1. First understand the background
Spark provides an enumeration class to support docking data Source operation mode
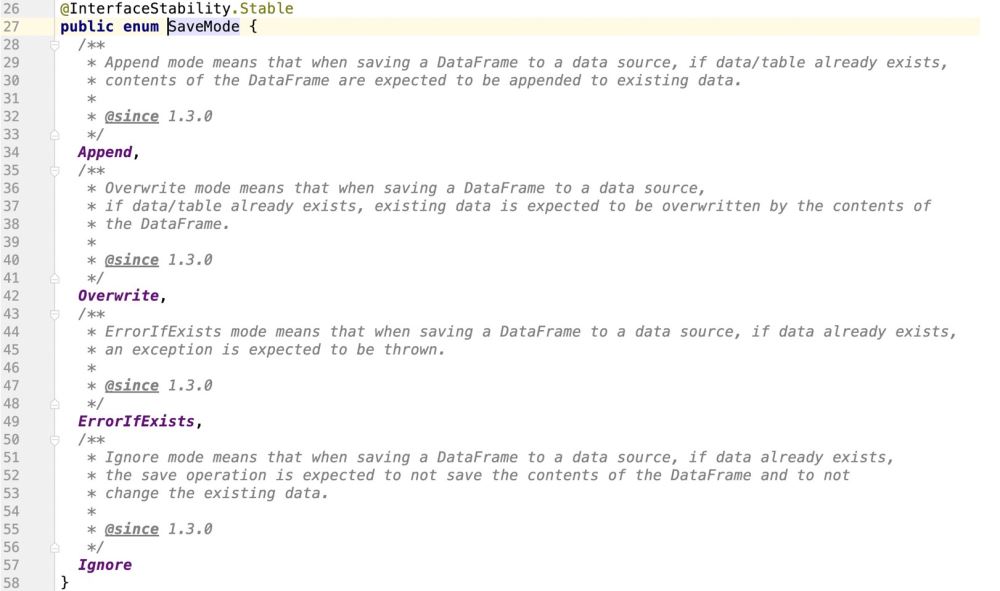
#Viewing the source code, it is obvious that spark does not support update operation
2. How to make sparkSQL support update
The key knowledge point is:
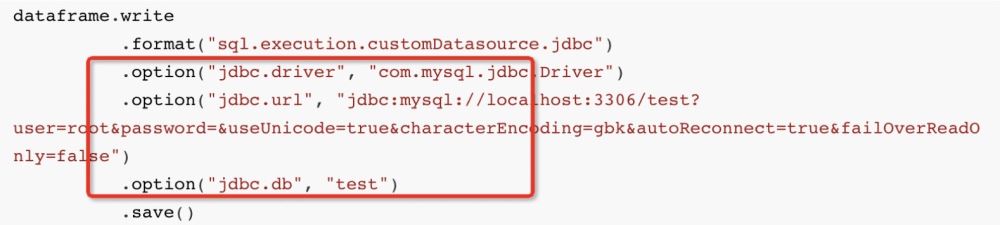
When we normally write data to mysql in sparkSQL:
The approximate API is:
dataframe.write
.format("sql.execution.customDatasource.jdbc")
.option("jdbc.driver", "com.mysql.jdbc.Driver")
.option("jdbc.url", "jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=true&characterEncoding=gbk&autoReconnect=true&failOverReadOnly=false")
.option("jdbc.db", "test")
.save()Then in the bottom layer, spark will Through the JDBC dialect JdbcDialect, the data we want to insert is translated into:
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
Then the sql statement parsed through the dialect is submitted to mysql through PrepareStatement's executeBatch(), and then the data is inserted;
The above sql statement is obvious. It is completely inserting code and does not have the update operation we expect. It is similar to:
UPDATE table_name SET field1=new-value1, field2=new-value2
But mysql exclusively supports such sql statement:
INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
The general meaning is that if the data does not exist, insert it, and if the data exists, perform the update operation;
So, our focus is to enable Spark SQL to generate such SQL statements when internally docking with JdbcDialect
INSERT INTO 表名称 (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
3. Before transforming the source code, you need to understand the overall code design and execution process
First of all:
dataframe.write
The write method is called to return a class: DataFrameWriter
Mainly because DataFrameWriter is the entry carrying class for sparksql to connect to external data sources. The following content is the carrying information registered for DataFrameWriter
Then start the save() operation After that, start writing the data;
Next, look at the save() source code:
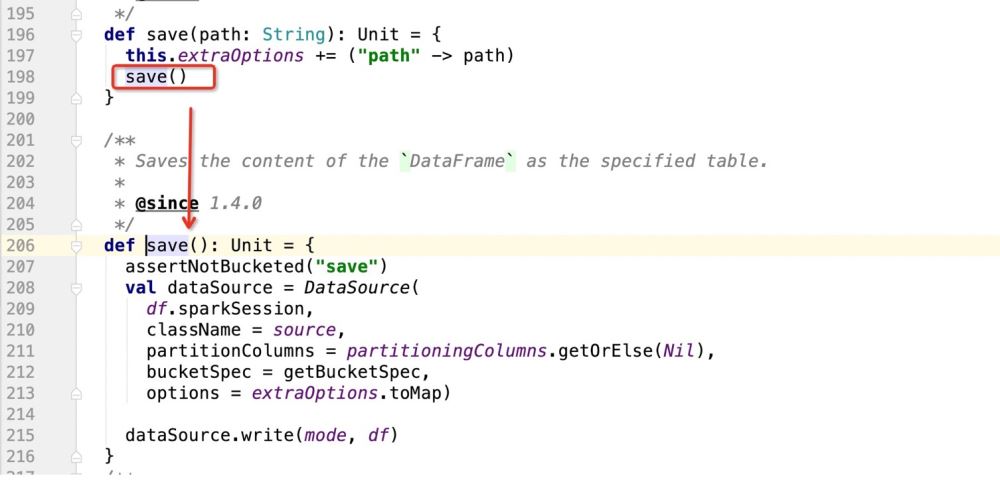
In the above source code, the main thing is to register the DataSource instance, and then Use the write method of DataSource to write data
When instantiating DataSource:
def save(): Unit = {
assertNotBucketed("save")
val dataSource = DataSource(
df.sparkSession,
className = source,//自定义数据源的包路径
partitionColumns = partitioningColumns.getOrElse(Nil),//分区字段
bucketSpec = getBucketSpec,//分桶(用于hive)
options = extraOptions.toMap)//传入的注册信息
//mode:插入数据方式SaveMode , df:要插入的数据
dataSource.write(mode, df)
}Then there are the details of dataSource.write(mode, df). The entire logic is:
Do pattern matching based on providingClass.newInstance(), and then execute the code wherever it matches;
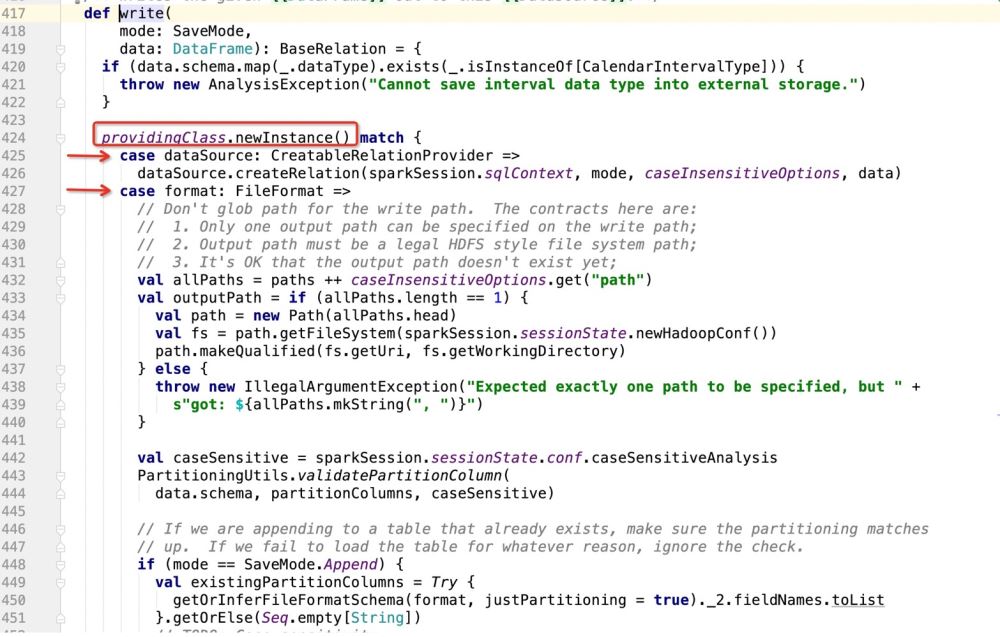
Then look at what providingClass is:
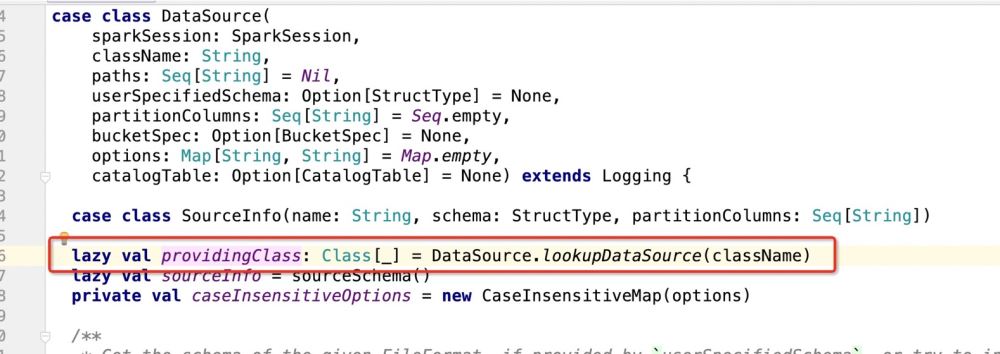
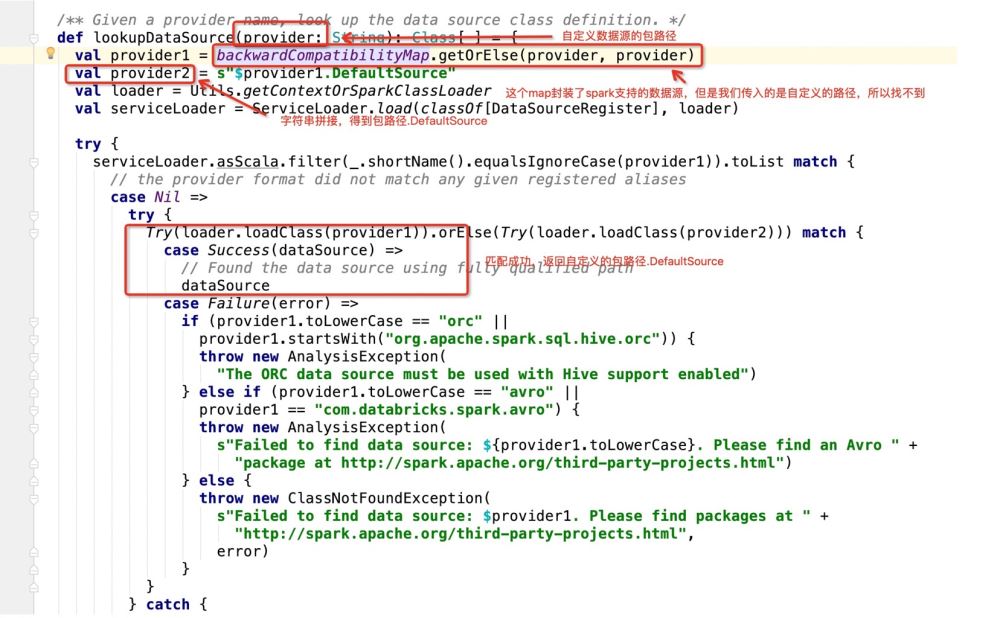
After getting the package path.DefaultSource, the program enters:
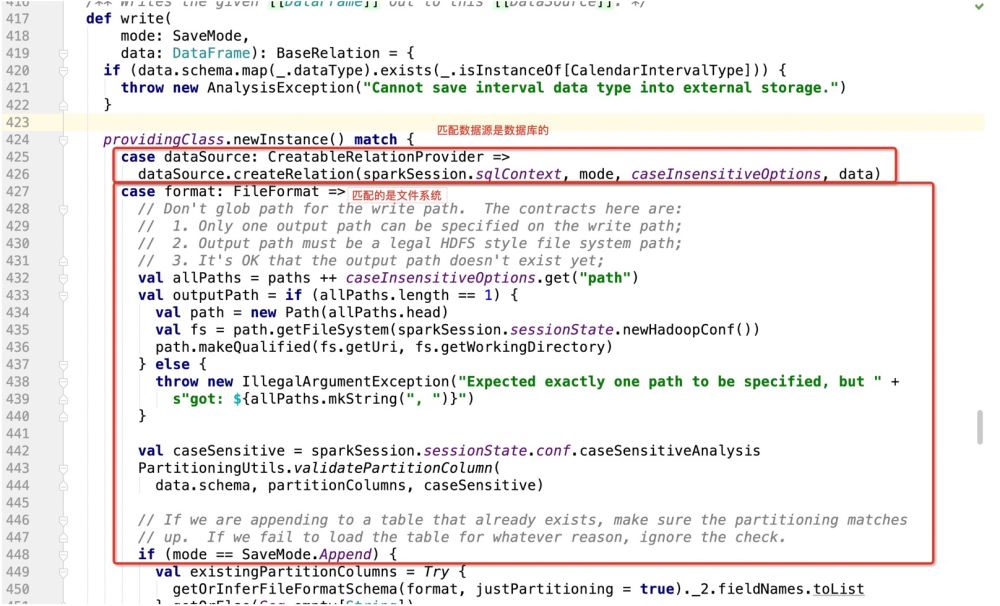
Then if it is If the database is used as the write target, it will go: dataSource.createRelation, and directly follow the source code:
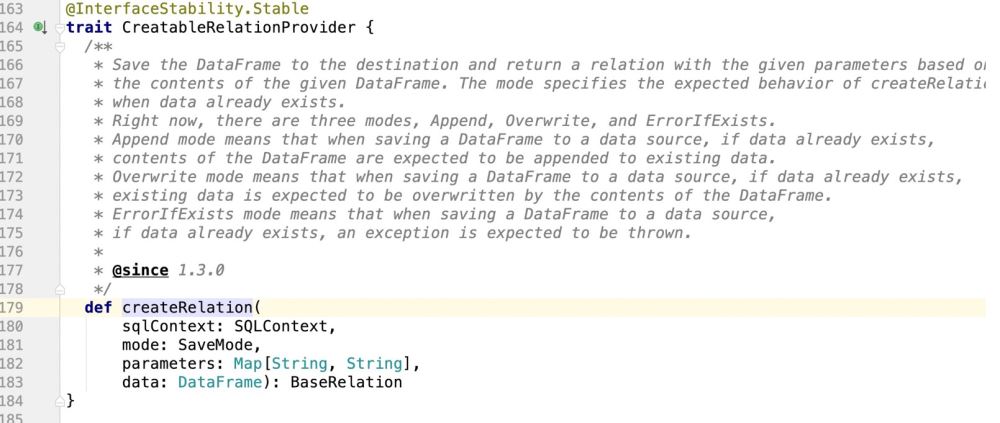
is obviously a trait, so wherever the trait is implemented, the program will go Where is it?
The place to implement this feature is: package path.DefaultSource, and then implement data insertion and update support operations here;
4. Transform the source code
According to the flow of the code, the final operation of sparkSQL writing data to mysql will enter the package path.DefaultSource class;
In other words, this class needs to support the normal operation of Spark at the same time. Insert operation (SaveMode) and update operation
If sparksql supports update operations, the most important thing is to make a judgment, such as:
if(isUpdate){
sql语句:INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
}else{
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
}However, in the source code of spark production sql statement, it is Written like this:
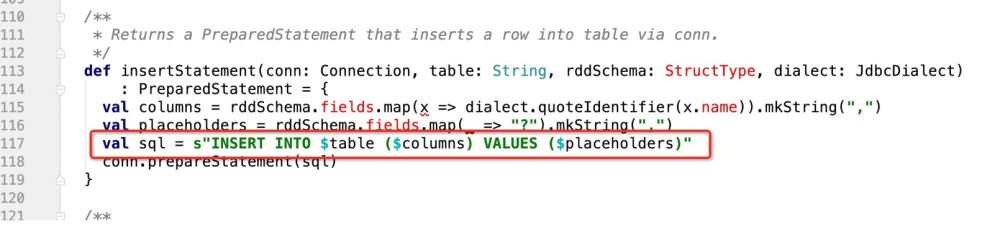
There is no judgment logic, it just generates one in the end:
INSERT INTO TABLE (字段1 , 字段2....) VALUES (? , ? ...)
So the first task is how to make the current code support: ON DUPLICATE KEY UPDATE
You can make a bold design, that is, make the following judgment in the insertStatement method
def insertStatement(conn: Connection, savemode:CustomSaveMode , table: String, rddSchema: StructType, dialect: JdbcDialect)
: PreparedStatement = {
val columns = rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",")
val placeholders = rddSchema.fields.map(_ => "?").mkString(",")
if(savemode == CustomSaveMode.update){
//TODO 如果是update,就组装成ON DUPLICATE KEY UPDATE的模式处理
s"INSERT INTO $table ($columns) VALUES ($placeholders) ON DUPLICATE KEY UPDATE $duplicateSetting"
}esle{
val sql = s"INSERT INTO $table ($columns) VALUES ($placeholders)"
conn.prepareStatement(sql)
}
}In this way, we verify the savemode mode passed in by the user, If it is an update operation, the corresponding SQL statement will be returned!
So according to the above logic, our code is written like this:
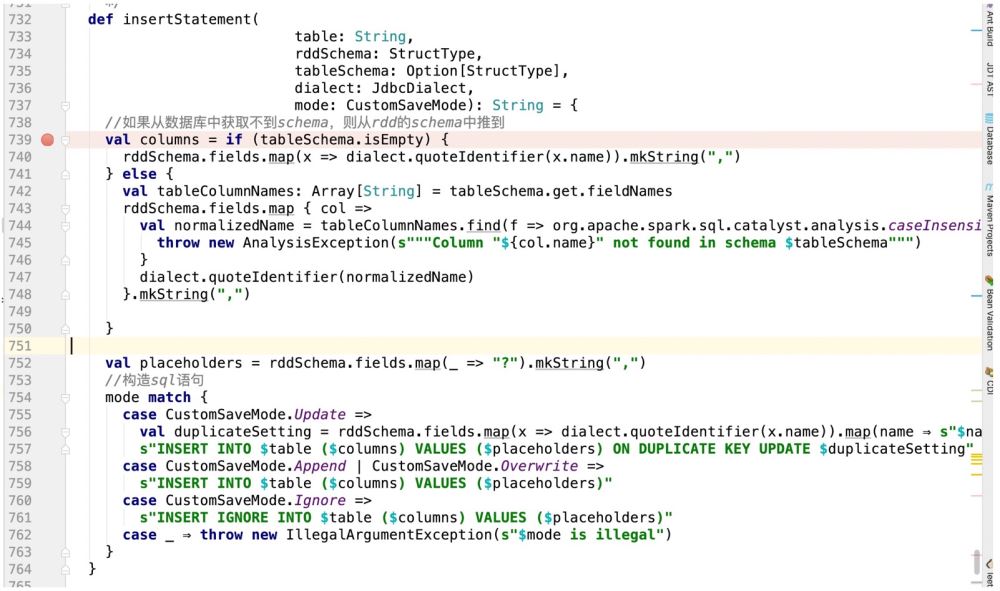
In this way we get the corresponding sql statement;
But only This sql statement still won't work, because the jdbc prepareStatement operation will be executed in spark, which will involve a cursor.
That is, when jdbc traverses this sql, the source code will do this:
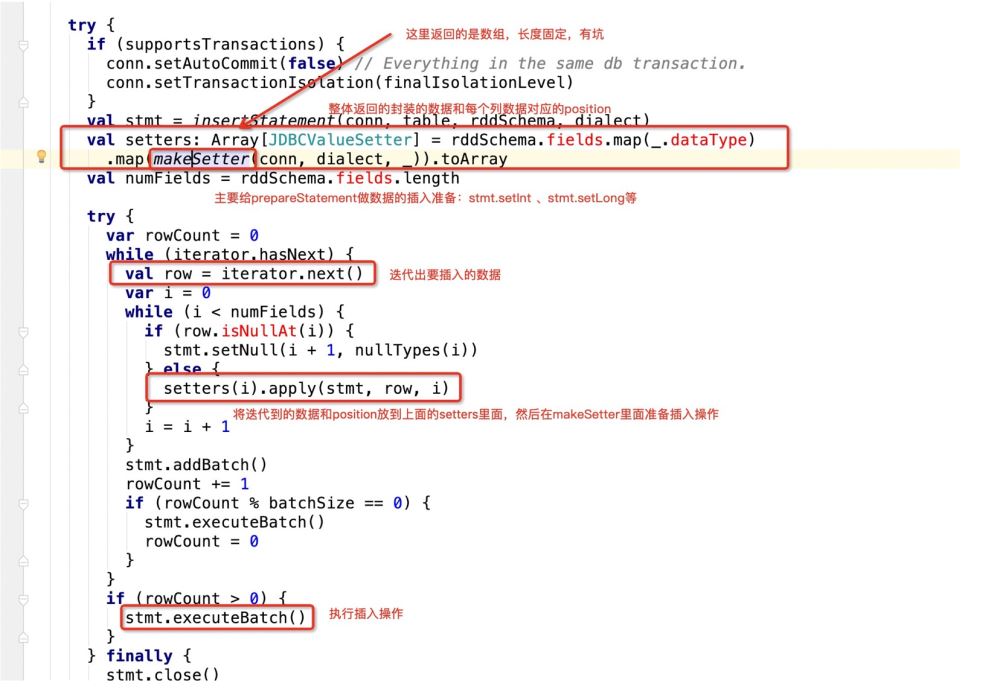
看下makeSetter:

所谓有坑就是:
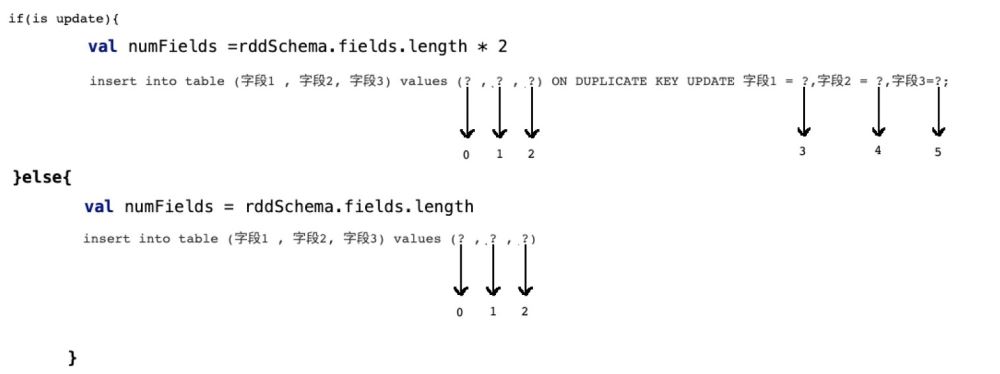
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?)
那么当前在源码中返回的数组长度应该是3:
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray但是如果我们此时支持了update操作,既:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?) ON DUPLICATE KEY UPDATE 字段1 = ?,字段2 = ?,字段3=?;
那么很明显,上面的sql语句提供了6个? , 但在规定字段长度的时候只有3
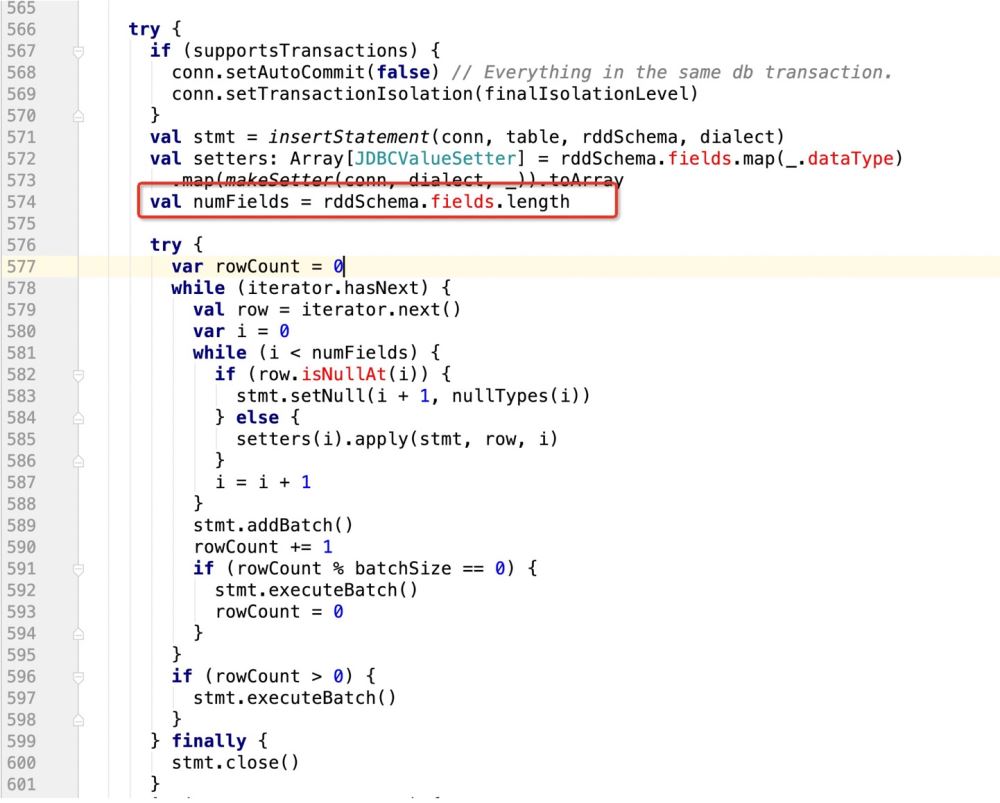
这样的话,后面的update操作就无法执行,程序报错!
所以我们需要有一个 识别机制,既:
if(isupdate){
val numFields = rddSchema.fields.length * 2
}else{
val numFields = rddSchema.fields.length
}
row[1,2,3] setter(0,1) //index of setter , index of row setter(1,2) setter(2,3) setter(3,1) setter(4,2) setter(5,3)
所以在prepareStatment中的占位符应该是row的两倍,而且应该是类似这样的一个逻辑
因此,代码改造前样子:
改造后的样子:
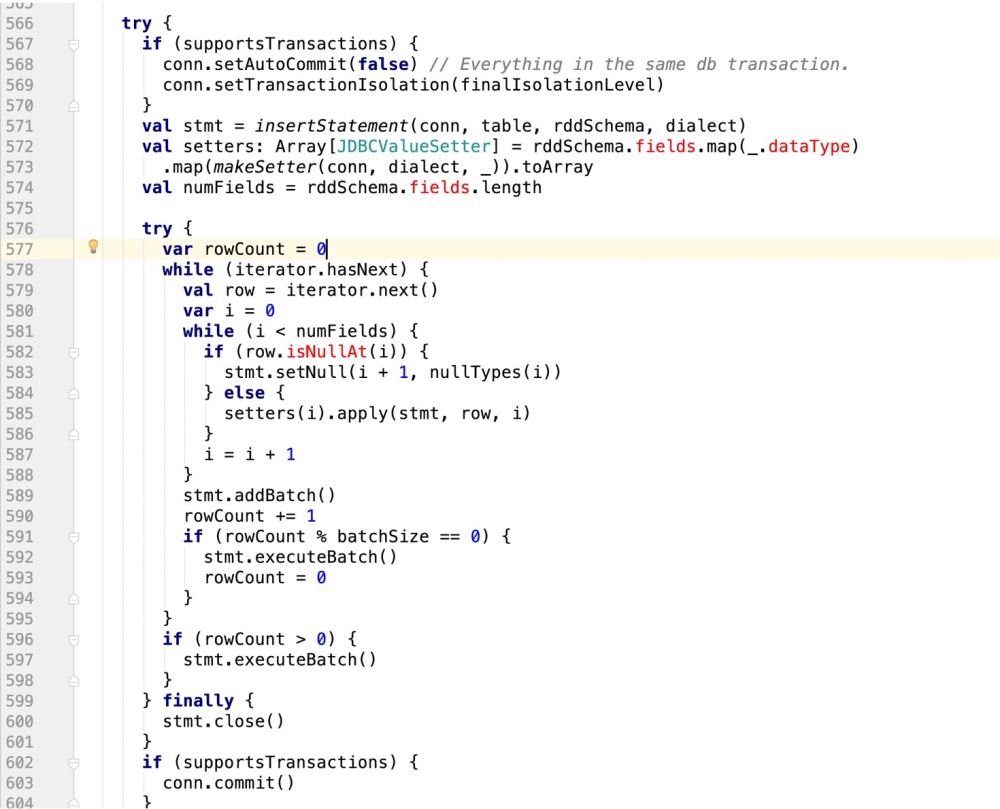
try {
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
// val stmt = insertStatement(conn, table, rddSchema, dialect)
//此处采用最新自己的sql语句,封装成prepareStatement
val stmt = conn.prepareStatement(sqlStmt)
println(sqlStmt)
/**
* 在mysql中有这样的操作:
* INSERT INTO user_admin_t (_id,password) VALUES ('1','第一次插入的密码')
* INSERT INTO user_admin_t (_id,password)VALUES ('1','第一次插入的密码') ON DUPLICATE KEY UPDATE _id = 'UpId',password = 'upPassword';
* 如果是下面的ON DUPLICATE KEY操作,那么在prepareStatement中的游标会扩增一倍
* 并且如果没有update操作,那么他的游标是从0开始计数的
* 如果是update操作,要算上之前的insert操作
* */
//makeSetter也要适配update操作,即游标问题
val isUpdate = saveMode == CustomSaveMode.Update
val setters: Array[JDBCValueSetter] = isUpdate match {
case true =>
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
Array.fill(2)(setters).flatten
case _ =>
rddSchema.fields.map(_.dataType)
val numFieldsLength = rddSchema.fields.length
val numFields = isUpdate match{
case true => numFieldsLength *2
case _ => numFieldsLength
val cursorBegin = numFields / 2
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if(isUpdate){
//需要判断当前游标是否走到了ON DUPLICATE KEY UPDATE
i < cursorBegin match{
//说明还没走到update阶段
case true =>
//row.isNullAt 判空,则设置空值
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
//说明走到了update阶段
case false =>
if (row.isNullAt(i - cursorBegin)) {
//pos - offset
stmt.setNull(i + 1, nullTypes(i - cursorBegin))
setters(i).apply(stmt, row, i, cursorBegin)
}
}else{
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i ,0)
}
//滚动游标
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
if (rowCount > 0) {
stmt.executeBatch()
} finally {
stmt.close()
conn.commit()
committed = true
Iterator.empty
} catch {
case e: SQLException =>
val cause = e.getNextException
if (cause != null && e.getCause != cause) {
if (e.getCause == null) {
e.initCause(cause)
} else {
e.addSuppressed(cause)
throw e
} finally {
if (!committed) {
// The stage must fail. We got here through an exception path, so
// let the exception through unless rollback() or close() want to
// tell the user about another problem.
if (supportsTransactions) {
conn.rollback()
conn.close()
} else {
// The stage must succeed. We cannot propagate any exception close() might throw.
try {
conn.close()
} catch {
case e: Exception => logWarning("Transaction succeeded, but closing failed", e)// A `JDBCValueSetter` is responsible for setting a value from `Row` into a field for
// `PreparedStatement`. The last argument `Int` means the index for the value to be set
// in the SQL statement and also used for the value in `Row`.
//PreparedStatement, Row, position , cursor
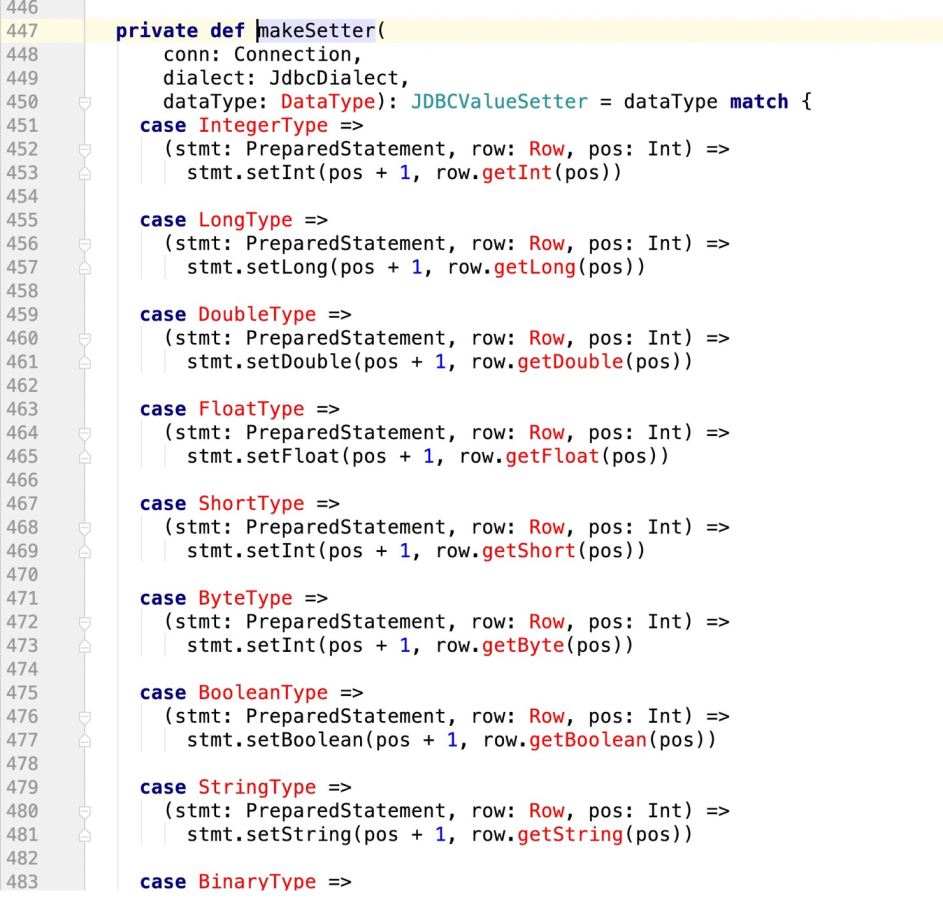
private type JDBCValueSetter = (PreparedStatement, Row, Int , Int) => Unit
private def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int,cursor:Int) =>
stmt.setInt(pos + 1, row.getInt(pos - cursor))
case LongType =>
stmt.setLong(pos + 1, row.getLong(pos - cursor))
case DoubleType =>
stmt.setDouble(pos + 1, row.getDouble(pos - cursor))
case FloatType =>
stmt.setFloat(pos + 1, row.getFloat(pos - cursor))
case ShortType =>
stmt.setInt(pos + 1, row.getShort(pos - cursor))
case ByteType =>
stmt.setInt(pos + 1, row.getByte(pos - cursor))
case BooleanType =>
stmt.setBoolean(pos + 1, row.getBoolean(pos - cursor))
case StringType =>
// println(row.getString(pos))
stmt.setString(pos + 1, row.getString(pos - cursor))
case BinaryType =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - cursor))
case TimestampType =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - cursor))
case DateType =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - cursor))
case t: DecimalType =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos - cursor))
case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase.split("\\(")(0)
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos - cursor).toArray)
stmt.setArray(pos + 1, array)
case _ =>
(_: PreparedStatement, _: Row, pos: Int,cursor:Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}The above is the detailed content of How to make spark sql support update operation when writing mysql. For more information, please follow other related articles on the PHP Chinese website!