
Home >Database >Mysql Tutorial >Why is it not recommended to use SELECT * in MySQL?
Why is it not recommended to use SELECT * in MySQL?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-31 23:10:482256browse
"Don't use SELECT *" has almost become a golden rule for MySQL. Even the "Alibaba Java Development Manual" clearly states that * is not allowed to be used as the field list of the query. , which gives this rule the blessing of authority.

However, I often use SELECT * directly during the development process for two reasons:
-
Because it is simple, the development efficiency is very high, and if fields are frequently added or modified later, the SQL statement does not need to be changed;
I think premature optimization is a bad habit. Unless you can determine at the beginning what fields you actually need and create appropriate indexes for them; otherwise, I choose to optimize SQL when I encounter trouble, of course provided that the trouble is not fatal.
But we always have to know why it is not recommended to use SELECT * directly. This article gives reasons from 4 aspects.
1. Unnecessary disk I/O
We know that MySQL essentially stores user records on the disk, so the query operation is a behavior of performing disk IO (provided that The queried records are not cached in memory).
The more fields you query, the more content you need to read, which will increase disk IO overhead. Especially when some fields are of type TEXT, MEDIUMTEXT or BLOB, the effect is particularly obvious.
Will using SELECT * cause MySQL to take up more memory?
Theoretically not, because for the Server layer, the complete result set is not stored in the memory and then passed to the client all at once, but every time a row is obtained from the storage engine, it is Write to a memory space called net_buffer. The size of this memory is controlled by the system variable net_buffer_length. The default is 16KB; when net_buffer is full, then write to The data written in the memory space of the local network stack socket send buffer is sent to the client. After the sending is successful (the client read is completed), it is cleared net_buffer, and then continues to read the next line and write enter.
In other words, by default, the maximum memory space occupied by the result set is only net_buffer_length. It will not occupy additional memory space just because of a few more fields.
2. Increase the network delay
Following the previous point, although the data in socket send buffer is sent to the client every time, the data can be seen in a single time The amount is not large, but I can’t stand it. Someone actually used it to find out fields of type TEXT, MEDIUMTEXT or BLOB. The total amount of data is huge. This is This directly leads to an increase in the number of network transmissions.
If MySQL and the application are not on the same machine, this overhead is very obvious. Even if the MySQL server and client are on the same machine, communication between them still needs to use the TCP protocol, which also adds additional transmission time.
3. Covering index cannot be used
In order to illustrate this problem, we need to create a table
CREATE TABLE `user_innodb` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `gender` tinyint(1) DEFAULT NULL, `phone` varchar(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `IDX_NAME_PHONE` (`name`,`phone`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
We created a table with the storage engine InnoDBuser_innodb, and set id as the primary key, and created a joint index for name and phone, and finally randomly initialized 500W pieces of data into the table.
InnoDB will automatically create a B-tree called the primary key index (also called a clustered index) for the primary key id. The most important feature of this B-tree is that the leaf nodes contain complete The user record looks like this.
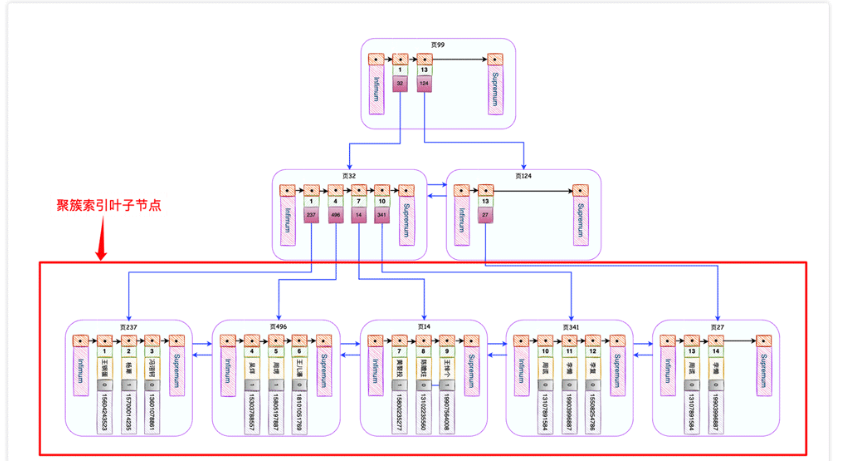
If we execute this statement
SELECT * FROM user_innodb WHERE name = '蝉沐风';
Use EXPLAIN to view the execution plan of the statement:

It is found that this SQL statement will use the IDX_NAME_PHONE index, which is a secondary index. The leaf node of the secondary index looks like this:
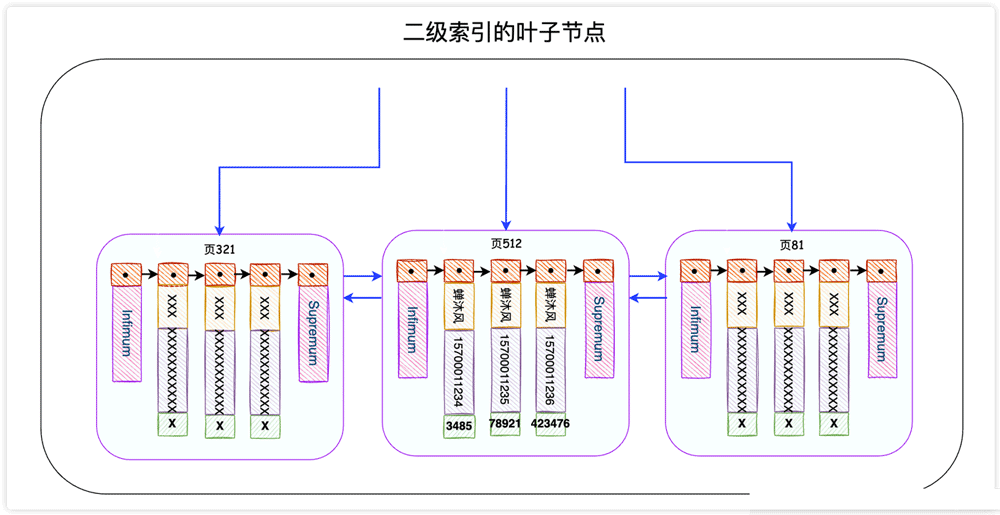
The InnoDB storage engine will find name in the leaf node of the secondary index based on the search conditions. The record of ChanMufeng, but only the name, phone and primary key id fields are recorded in the secondary index (who asked us to use is SELECT *), so InnoDB needs to take the primary key id to search for this complete record in the primary key index. This process is called returning to the table.
Think about it, if the leaf nodes of the secondary index have all the data we want, is there no need to return the table? Yes, that's covering index.
For example, we just want to search for name, phone and the primary key field.
SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";
使用EXPLAIN查看一下语句的执行计划:

可以看到Extra一列显示Using index,表示我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是使用了覆盖索引,能够直接摒弃回表操作,大幅度提高查询效率。
4. 可能拖慢JOIN连接查询
我们创建两张表t1,t2进行连接操作来说明接下来的问题,并向t1表中插入了100条数据,向t2中插入了1000条数据。
CREATE TABLE `t1` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT; CREATE TABLE `t2` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT;
如果我们执行下面这条语句
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.m = t2.m;
这里我使用了STRAIGHT_JOIN强制令
t1表作为驱动表,t2表作为被驱动表
对于连接查询而言,驱动表只会被访问一遍,而被驱动表却要被访问好多遍,具体的访问次数取决于驱动表中符合查询记录的记录条数。现在,我们来讲一下两个表连接的本质,因为驱动表和被驱动表已经被强制确定
t1作为驱动表,针对驱动表的过滤条件,执行对t1表的查询。因为没有过滤条件,也就是获取t1表的所有数据;对上一步中获取到的结果集中的每一条记录,都分别到被驱动表中,根据连接过滤条件查找匹配记录
用伪代码表示的话整个过程是这样的:
// t1Res是针对驱动表t1过滤之后的结果集
for (t1Row : t1Res){
// t2是完整的被驱动表
for(t2Row : t2){
if (满足join条件 && 满足t2的过滤条件){
发送给客户端
}
}
}这种方法最简单,但同时性能也是最差,这种方式叫做嵌套循环连接(Nested-LoopJoin,NLJ)。怎么加快连接速度呢?
其中一个办法就是创建索引,最好是在被驱动表(t2)连接条件涉及到的字段上创建索引,毕竟被驱动表需要被查询好多次,而且对被驱动表的访问本质上就是个单表查询而已(因为t1结果集定了,每次连接t2的查询条件也就定死了)。
既然使用了索引,为了避免重蹈无法使用覆盖索引的覆辙,我们也应该尽量不要直接SELECT *,而是将真正用到的字段作为查询列,并为其建立适当的索引。
但是如果我们不使用索引,MySQL就真的按照嵌套循环查询的方式进行连接查询吗?当然不是,毕竟这种嵌套循环查询实在是太慢了!
在MySQL8.0之前,MySQL提供了基于块的嵌套循环连接(Block Nested-Loop Join,BLJ)方法,MySQL8.0又推出了hash join方法,这两种方法都是为了解决一个问题而提出的,那就是尽量减少被驱动表的访问次数。
这两种方法都用到了一个叫做join buffer的固定大小的内存区域,其中存储着若干条驱动表结果集中的记录(这两种方法的区别就是存储的形式不同而已),如此一来,把被驱动表的记录加载到内存的时候,一次性和join buffer中多条驱动表中的记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价,大大减少了重复从磁盘上加载被驱动表的代价。使用join buffer的过程如下图所示:
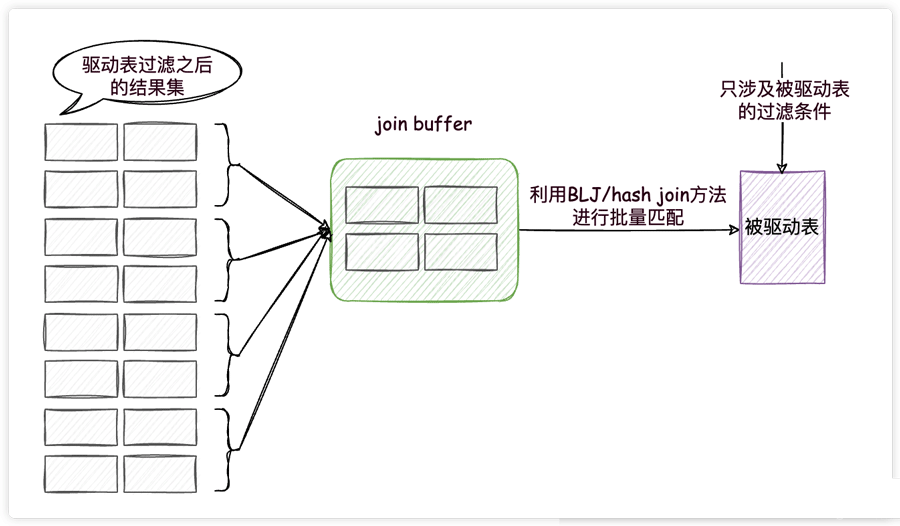
我们看一下上面的连接查询的执行计划,发现确实使用到了hash join(前提是没有为t2表的连接查询字段创建索引,否则就会使用索引,不会使用join buffer)。

最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。我们可以使用join_buffer_size这个系统变量进行配置,默认大小为256KB。如果还装不下,就得分批把驱动表的结果集放到join buffer中了,在内存中对比完成之后,清空join buffer再装入下一批结果集,直到连接完成为止。
重点来了!并不是驱动表记录的所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录,减少分批的次数,也就自然减少了对被驱动表的访问次数
The above is the detailed content of Why is it not recommended to use SELECT * in MySQL?. For more information, please follow other related articles on the PHP Chinese website!