
Home >Database >Mysql Tutorial >Example analysis of classification ranking and grouping TOP N in MySQL
Example analysis of classification ranking and grouping TOP N in MySQL

- WBOYforward
- 2023-05-28 23:10:041834browse
Table structure
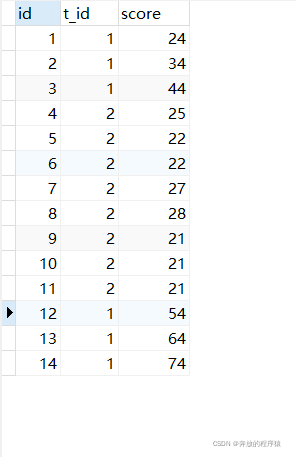
The student table is as follows:
CREATE TABLE `t_student` ( `id` int NOT NULL AUTO_INCREMENT, `t_id` int DEFAULT NULL COMMENT '学科id', `score` int DEFAULT NULL COMMENT '分数', PRIMARY KEY (`id`) );
The data is as follows:
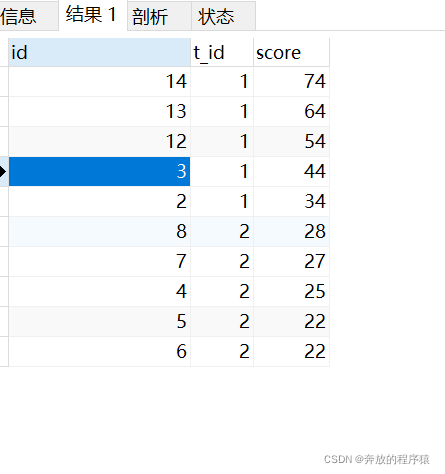
Question 1: Obtain the ranking of the top five scores in each subject (tieing is allowed)
Allowing tie situations may exist, such as a tie between 4th and 5th place, which will result in 5 pieces of data being obtained from the top 4. The top 5 are also 5 pieces of data.
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score GROUP BY s1.id HAVING COUNT( s2.id ) < 5 ORDER BY s1.t_id, s1.score DESC
ps: When taking the top 4 places
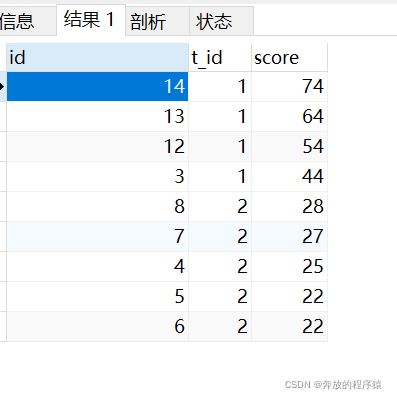
Analysis:
1. Own left Outer join gets all the sets whose left value is less than the right value. Taking t_id=1 as an example, 24 has 5 scores greater than him (74, 64, 54, 44, 34), ranking 6th, 34 has only 4 scores greater than him, ranking 5th... .74 There is no one bigger than him and he is the first.
SELECT * FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score
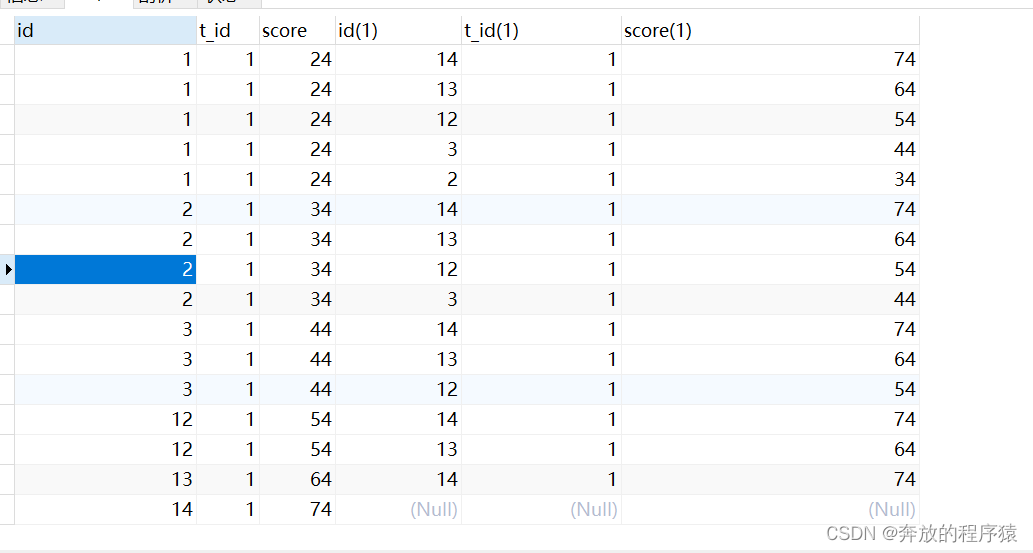
2. Convert the summarized rules into SQL and express it, which is group by the id (s1.id) of each student. Having statistics on how many students there are under this id A value larger than him (s2.id)
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score GROUP BY s1.id HAVING COUNT( s2.id ) < 5
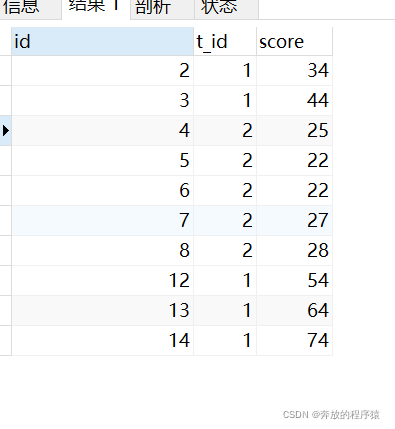
3. Finally, classify according to t_id and sort by score in reverse order.
Question 2: Get the average score of the last two students in each subject
Get the last two scores
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score GROUP BY s1.id HAVING COUNT( s1.id )< 2 ORDER BY s1.t_id, s1.score
The existence of juxtaposition may lead to the same filtered out The number of results under t_id is greater than 2, but the question requirement is to take the average of the last two results. After averaging multiple results, it is still the same, so there is no need to process it anymore, which can meet the question requirements.
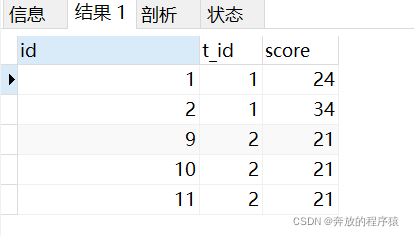
Group average:
SELECT t_id,AVG(score) FROM ( SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score GROUP BY s1.id HAVING COUNT( s1.id )< 2 ORDER BY s1.t_id, s1.score ) tt GROUP BY t_id
Result:
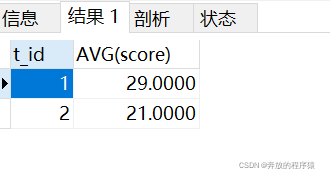
Analysis:
1. Query all the records of t1.score>t2.score
SELECT s1.*,s2.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score
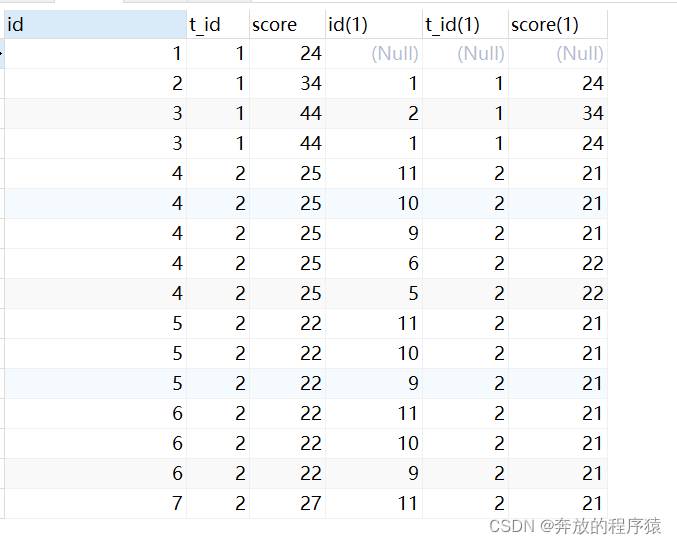
2. Group by s.id to remove duplicates, and have 2 records
3. group by t_id Take the results of each subject and then take the average of avg
Question 3: Get the top five score rankings for each subject (timing is not allowed)
SELECT * FROM ( SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it GROUP BY s1.id ORDER BY s1.t_id, s1.score DESC ) tt GROUP BY t_id, score, rownum HAVING COUNT( rownum )< 5
Analysis:
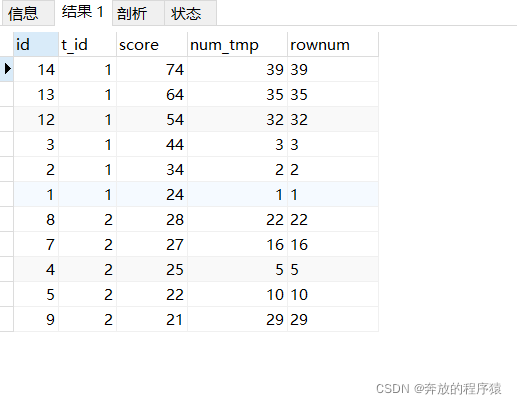
1. Introduce auxiliary parameters
SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it
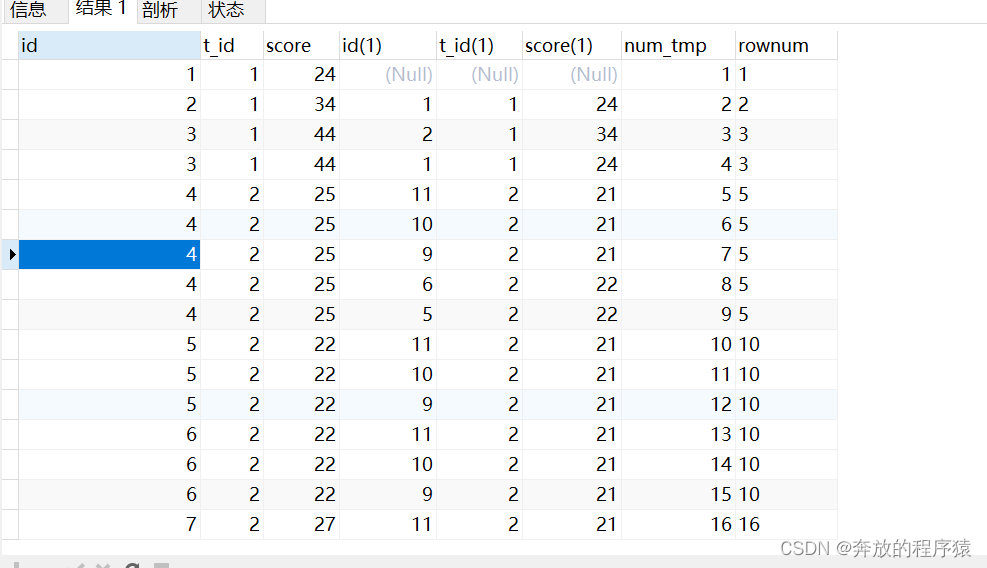
2. Remove duplicate s1.id, group sorting
SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it GROUP BY s1.id ORDER BY s1.t_id, s1.score DESC
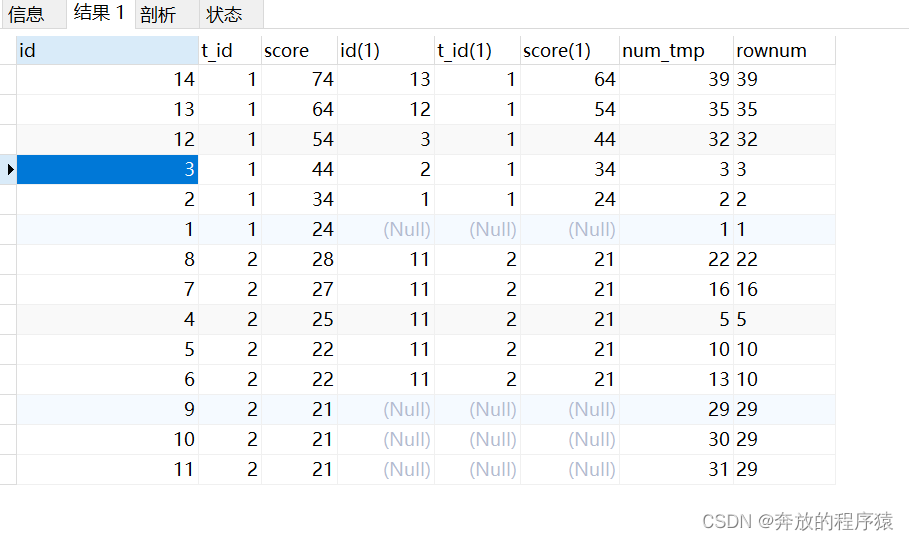
3.GROUP BY t_id, score, rownum Then HAVING takes the first 5 unique items
The above is the detailed content of Example analysis of classification ranking and grouping TOP N in MySQL. For more information, please follow other related articles on the PHP Chinese website!