
Home >Database >Mysql Tutorial >MySQL detailed index failure case analysis
MySQL detailed index failure case analysis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-28 13:17:431478browse
Storage structure of the index
First of all, let’s understand the storage structure of the index. Only by knowing the storage structure of the index can we better understand the problem of index failure.
The storage structure of the index is related to the MySQL storage engine. Different storage engines use different structures.
MySQL's default storage engine InnoDB uses B Tree as the index data structure. When creating a table, InnoDB will create a primary key index by default, which is a clustered index, and other indexes are secondary indexes.
When the MyISAM storage engine creates a table, it uses a B-tree index by default.
Although they both support B-tree indexes like InnoDB, they store data in different ways;
InnoDB is a clustered index (the leaf nodes of the B-tree index save the data itself)
MyISAM is a non-clustered index (the physical address where the leaf nodes of the B tree store data)
As shown in the figure below:
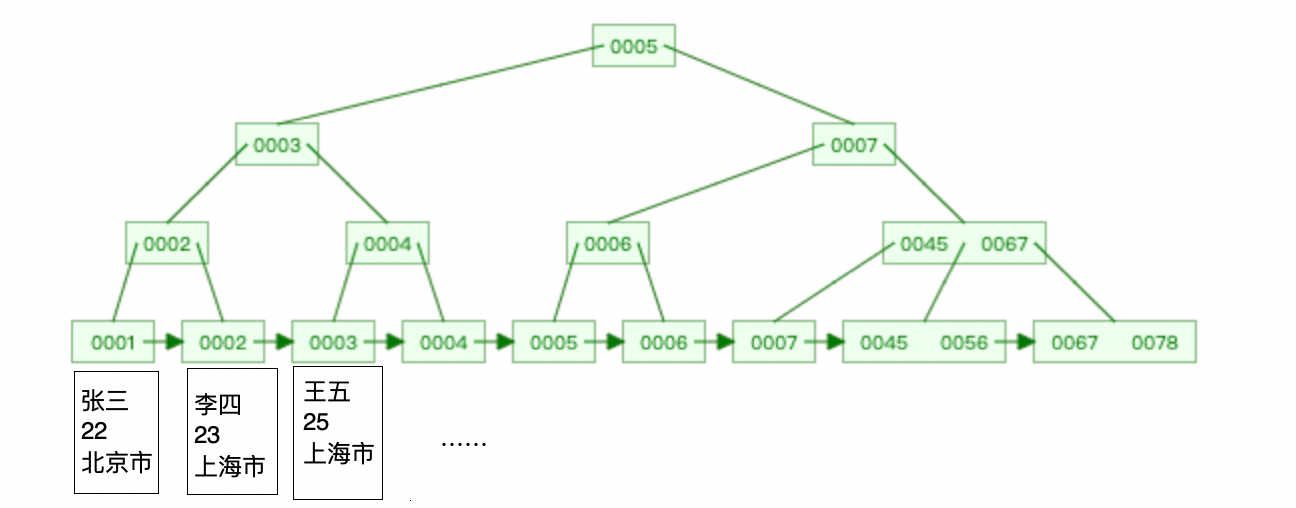
InnoDB storage engine can be divided into [clustered index] and [secondary index]. The difference between them is that the leaf nodes of the clustered index store actual data, and all complete data are stored in the clustered index. The leaf node of the secondary index stores the primary key value.
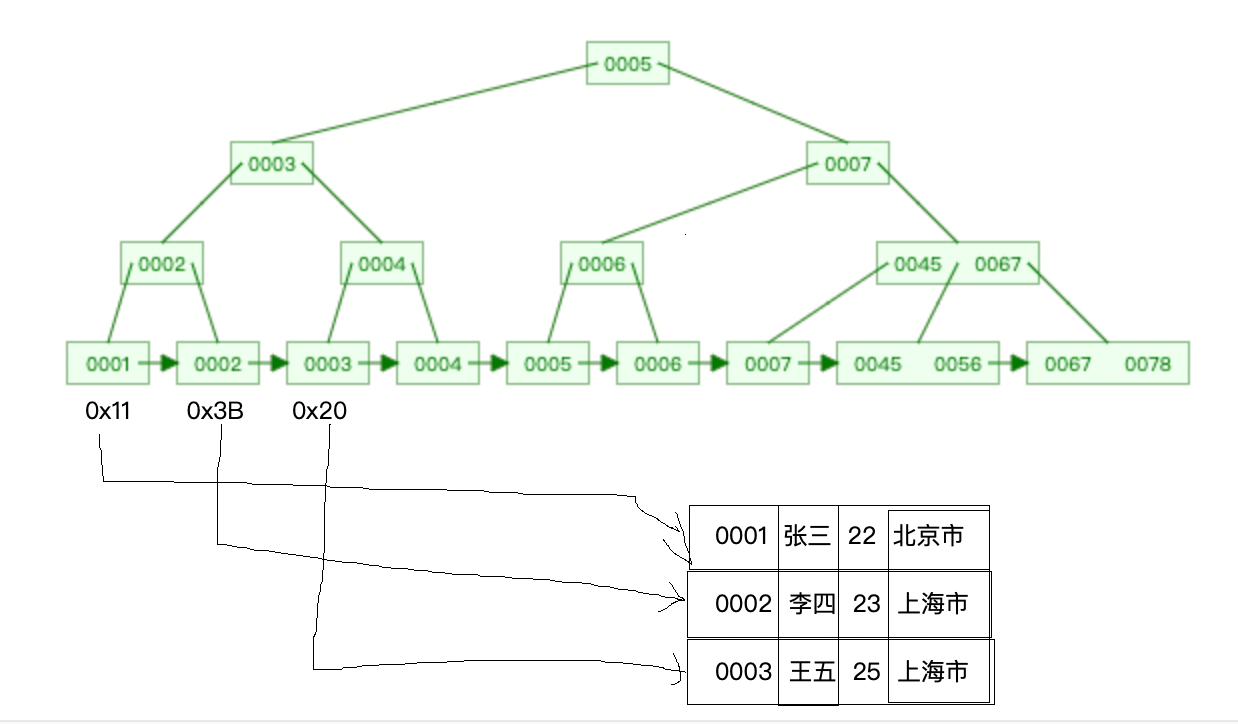
When using the secondary index field as the query condition and querying the data on the clustered index,
will first find the corresponding leaf node on the secondary index according to the conditions to obtain the primary key. value,
then find the corresponding leaf node on the clustered index based on the primary key value and then query the corresponding data.
This process is called back to the table
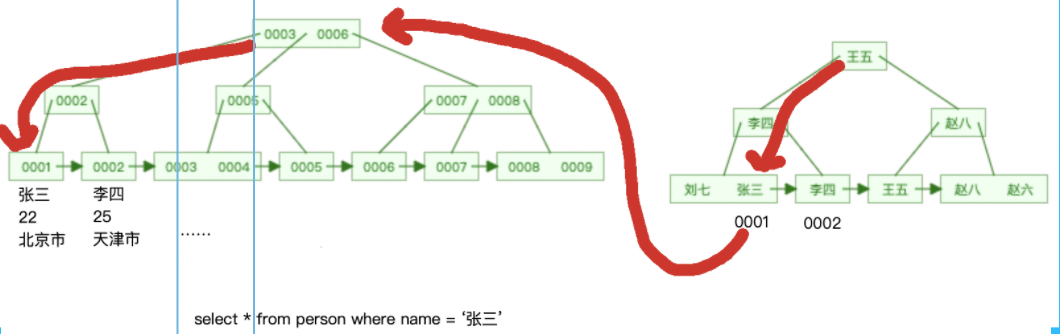
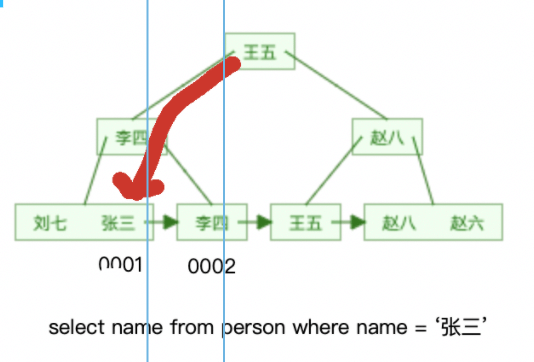
Use the secondary index as the query condition. When the queried data is on the leaf node of the secondary index, you only need to find the leaf node corresponding to the B-tree of the secondary index and read the data. This process is called covering index
The above query conditions all use index columns, but it does not mean that the index will definitely take effect if the index column is used. Let’s take a look at the index again. Failure situation
Unreasonable fuzzy query conditions
When using left or left fuzzy query, that is, like "% Zhang" or like "% Zhang%"These two fuzzy query methods will cause index failure
Because the B-tree is arranged according to the index value, when the prefix is uncertain, it may be, "Xiao Zhang", "Two Zhang" In all cases like this, the query can only be queried through a full table scan
Use the function for the index
For example: SELECT * FROM sys_user WHERE LENGTH(user_id) = 3 ;

#Because the index saves the original value of the index field, rather than the value calculated by the function, the index will not be used when using the function.
However, starting from MySQL 8.0, the index feature adds a function index, which means creating an index for the value calculated by the function, so that the data can be queried by scanning the index;
alter table t_user add key idx_name_length ((length(name)));
Perform expression calculation on the index
For example: select * from sys_user where user_id 1 =3;

But if it isSELECT * FROM sys_user WHERE user_id = 1 1 ;If you do not perform calculations on the index field, the index will be used again

The reason is related to the use of the index The functions are similar. The index saves the original value of the index field, not the calculated value, so the index cannot be used.
Use implicit conversion for the index
HerephoneThe field is a secondary index and is of type varchar


When using integers as query parameters, the type in the execution plan is ALL, that is, queried through a full table scan, but if it is a string type, it is still queried by index
Let’s look at another example
Hereuser_id is bigint type, but using strings as query parameters still removes the index


为什么第一个例子导致了索引失效,而第二个不会呢?
这里就要了解一下MySQL的字符转换规则了,看是数字转字符串,还是字符串转数字
我们可以用select "10">9来测试一下
如果是数字转字符串,那么就相当于select "10">"9"结果应该是0
如果是字符串转数字,那么就相当于select 10>9,结果是1
在MySQL中的执行结果如下:

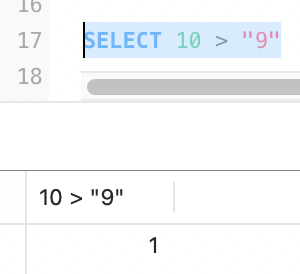
这就说明,MySQL在遇到数字与字符串的比较的时候,会自动把字符串转换为数字,然后进行比较
也就是说,在第一个例子中
SELECT * FROM sys_user WHERE phone = 18200000000 ;
相当于
SELECT * FROM sys_user WHERE CAST(phone AS UNSIGNED) = 18200000000 ;
这就在索引字段上使用了函数,所以导致索引失效
而在第二个例子中
SELECT * FROM sys_user WHERE user_id = "1" ;
相当于
SELECT * FROM sys_user WHERE user_id = CAST("1" AS UNSIGNED) ;函数式作用在查询参数上的,并没有作用在索引字段上,所以还是走索引的
联合索引非最左匹配
多个普通字段组合在一起创建的索引叫做联合索引(组合索引)
在使用联合索引的时候,一定要注意顺序问题,联合索引的使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引匹配。
例如,创建了一个(a,b,c)联合索引,那么如果查询条件是一下几种,就可以匹配上联合索引
where a = 1
where a = 1 and b = 2
where a = 1 and b = 2 and c = 3
需要注意的是,因为有查询优化器,所以a字段在where子句中的顺序不重要
若缺少a字段,则以下几种情况由于不符合最左匹配原则将无法匹配联合索引,导致该联合索引失效
where b = 2
where c = 3
where b = 2 and c = 3
还有一个比较特殊的查询条件:where a = 1 and c = 3
在MySQL5.5的话,前面的a 会走索引,在联合索引找到主键值,然后回表,到主键索引读取数据行,然后在比对c字段的值
在MySQL5.6之后,有一个索引下推的功能,
下推就是将部分上层(服务层)负责的事情,交给了下层(引擎层)处理
存储引擎直接在联合索引里按照c=3过滤,按照过滤后的数据在进行回表扫描,减少了回表的次数,从而提升了性能
在执行计划中Extra = Using index condition就表示使用了索引下推

联合索引不遵循最左匹配原则的原因:在联合索引中,数据按照第一列索引进行排序,第一列数据相同时,才会按照第二列进行排序,以此类推,所以直接使用第二列进行查询的时候,联合索引就会失效
where子句中的or
where子句中or的条件列有不是索引列会导致索引失效
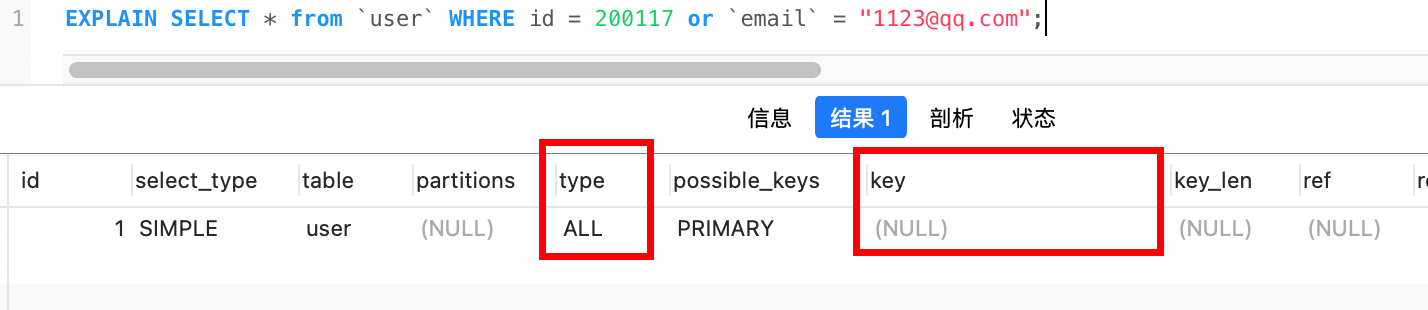
例如:下图中id是索引列,email不是索引列,从执行计划来看,进行了全文扫描并没有使用到索引
因为or关键字只满足一个条件就可以,因此只要有一个列不是索引列,其他索引列也就没有意义了,就会进行全表扫描
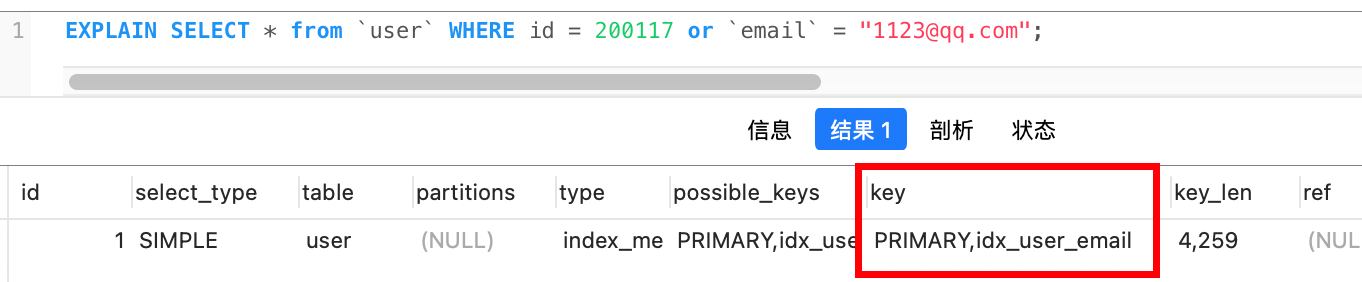
在email列上建立索引之后,可以看到执行计划中使用到了两个索引
type = index_merge表示对id 和email都进行了扫描,然后进行了合并
The above is the detailed content of MySQL detailed index failure case analysis. For more information, please follow other related articles on the PHP Chinese website!