undo log is used to store data before it is modified Value, assuming that the row data with id=2 in the tba table is modified and Name='B' is changed to Name = 'B2', then the undo log will be used to store the record of Name='B'. If there is an exception in this modification, You can use undo logs to implement rollback operations and ensure transaction consistency.
The data change operation mainly comes from INSERT UPDATE DELETE, and UNDO LOG is divided into two types, one is INSERT_UNDO (INSERT operation), which records the unique key value inserted; the other is UPDATE_UNDO (including UPDATE and DELETE operations), record modified unique key values and old column records.
| Id |
Name |
| 1 |
A |
| 2 |
B |
##3 | C |
4 |
D
|
1.2 undo parameters
MySQL has these parameter settings related to undo:
mysql> show global variables like '%undo%';
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| innodb_max_undo_log_size | 1073741824 |
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 3 |
+--------------------------+------------+
mysql> show global variables like '%truncate%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| innodb_purge_rseg_truncate_frequency | 128 |
| innodb_undo_log_truncate | OFF |
+--------------------------------------+-------+
Control the size of the maximum undo tablespace file. When innodb_undo_log_truncate is started, truncate will be attempted only when the undo tablespace exceeds the innodb_max_undo_log_size threshold. The default size of this value is 1G, and the default size after truncate is 10M.
Set the number of undo independent table spaces, the range is 0-128, the default is 0, 0 Indicates that the independent undo table space is not enabled and the undo log is stored in the ibdata file. This parameter can only be specified when initializing the MySQL instance. If the instance has been created, this parameter cannot be changed. If the number of innodb_undo_tablespaces specified in the database configuration file.cnf is greater than the number specified when the instance is created, it will The startup failed, indicating that the parameter setting is incorrect.

If this parameter is set to n (n>0), then n undo files (undo001, undo002... undo n), the default size of each file is 10M.
When do you need to set this parameter?
When the DB writing pressure is high, you can set up an independent UNDO table space, separate the UNDO LOG from the ibdata file, and specify the innodb_undo_directory directory for storage. It can be configured on a high-speed disk to speed up the UNDO LOG reading and writing performance.
InnoDB's purge thread is turned on or off according to the innodb_undo_log_truncate setting, the parameter value of innodb_max_undo_log_size, and truncate frequency to perform space reclamation and undo file reinitialization.
The premise for this parameter to take effect is that independent table spaces have been set up and the number of independent table spaces is greater than or equal to 2.
In the process of truncate undo log file, the purge thread needs to check whether there are active transactions on the file. If not, the undo log file needs to be marked as unallocable. At this time, undo log will be recorded to other files, so at least 2 independent table space files are required to perform the truncate operation. After marking it as unallocable, an independent file undo__trunc.log will be created to record that a certain undo log file is currently being truncate. , and then start to initialize the undo log file to 10M. After the operation is completed, delete the undo__trunc.log file representing the truncate action. This file ensures that even if a failure occurs during the truncate process, the database service will be restarted. After restarting, the service will find this file will continue to complete the truncate operation. After deleting the file, the undo log file will be marked as available for allocation.
is used to control the frequency of purge rollback segments, the default is 128. Assuming it is set to n, it means that when the coordination thread of Innodb Purge operation purges transactions 128 times, a History purge will be triggered to check whether the current undo log table space status will trigger truncate.
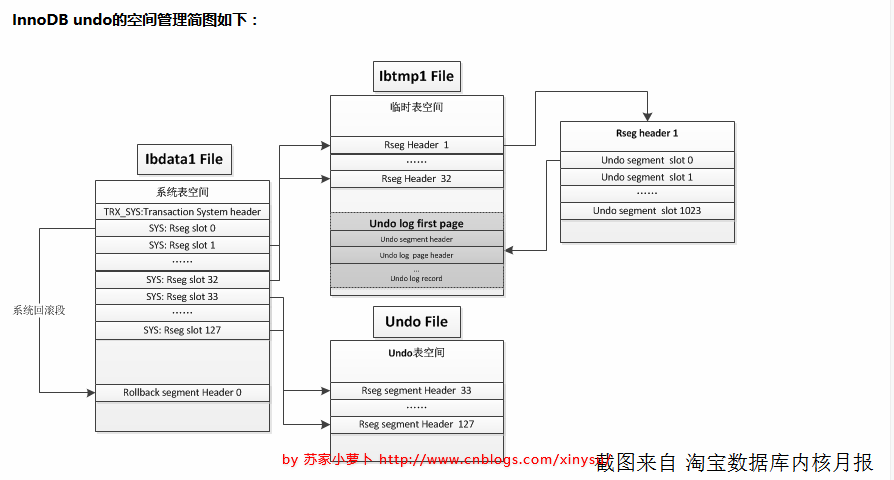
1.3 undo space management
If you need to set up independent table spaces, you need to specify the number of independent table spaces when initializing the database instance.
UNDO is internally composed of multiple rollback segments, that is, Rollback segments, a total of 128, which are stored in the ibdata system table space, from resg slot0 to resg slot127, each resg slot, that is, each The rollback segment is internally composed of 1024 undo segments.
The rollback segment is allocated as follows:
slot 0, reserved for the system table space;
Slot 1-32 is reserved for temporary table space. Every time the database is restarted, the temporary table space will be rebuilt;
slot33-127 is reserved if there is an independent table space. Give UNDO independent table space; if not, reserve it for system table space;
Remove 32 rollback segments for temporary table transactions, and the remaining 128-32= 96 rollback segments can execute 96*1024 concurrent transaction operations. Each transaction occupies one undo segment slot. Note that if there is a temporary table transaction in the transaction, another undo segment slot in the temporary table space will be occupied. segment slot, which occupies 2 undo segment slots. If there is: Cannot find a free slot for an undo log. means that there are too many concurrent transactions, and you need to consider whether to divert the business.
The rollback segment is allocated using polling scheduling. If an independent table space is set, the undo segment in the rollback segment of the system table space will not be used, but an independent table will be used. Space, at the same time, if the lookback segment is in Truncate operation, it is not allocated.
2 redo
2.1 What is redo
When the database modifies the data , the data page needs to be read from the disk into the buffer pool, and then modified in the buffer pool. At this time, the data page in the buffer pool will be inconsistent with the content of the data page on the disk. The data page in the buffer pool is called dirty page. Data, if an abnormal DB service restart occurs at this time, then the data is not yet in the memory and has not been synchronized to the disk file (note that synchronization to the disk file is a random IO), that is, data loss will occur. If this time , when there is a file, when the data page in the buffer pool is changed, the corresponding modification record can be recorded to this file (note that the log recording is sequential IO), then when the DB service crashes and the DB is restored, It can also be re-applied to the disk file based on the recorded content of this file, and the data will remain consistent.
This file is the redo log, which is used to record the modified data in sequence. It can bring these benefits:
When the dirty page in the buffer pool has not been refreshed to the disk, a crash occurs. After starting the service, you can find the page that needs to be refreshed through the redo log. Recording of disk files;
The data in the buffer pool is directly flushed to the disk file, which is a random IO and has poor efficiency. However, recording the data in the buffer pool to the redo log is A sequential IO can improve the speed of transaction submission;
Assume that the row data with id=2 in the tba table is modified and Name='B' is changed to Name = 'B2', then The redo log will be used to store the record with Name='B2'. If an exception occurs when this modification is flushed to the disk file, the redo log can be used to implement the redo operation to ensure the durability of the transaction.
| Id |
Name |
| 1 |
A |
| 2 |
B |
##3 | C |
4 |
D
|
Note here the difference between redo log and binary log. Redo log is generated by the storage engine layer, while binary log is generated by the database layer. Suppose a large transaction inserts 100,000 rows of records into tba. During this process, records are continuously recorded sequentially in the redo log, but the binary log will not record. Only when the transaction is committed will it be written to the binary log file at once. middle. There are three different recording formats available for binary logs, namely row, statement and mixed, and the recording forms among them are different.
2.2 redo Parameters
The number of redo log files, naming method such as: ib_logfile0, iblogfile1... iblogfilen. Default is 2, maximum is 100.
File setting size, the default value is 48M, the maximum value is 512G, pay attention to what the maximum value refers to It is the sum of the entire redo log series files, that is, (innodb_log_files_in_group * innodb_log_file_size) cannot be greater than the maximum value of 512G.
File storage path
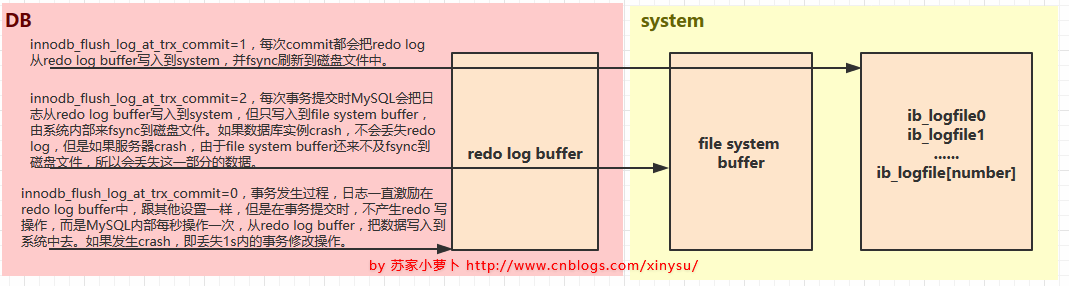
#Redo Log cache area, default 8M, can be set to 1-8M. Delay the transaction log writing to the disk, put the redo log into the buffer, and then flush the log from the buffer to the disk according to the setting of the innodb_flush_log_at_trx_commit parameter.
#innodb_flush_log_at_trx_commit=1, each commit will change the redo log from redo The log buffer is written to the system and flushed to the disk file via fsync.
Note: Due to process scheduling policy issues, this "perform flush (flush to disk) operation once per second" does not guarantee 100% "per second" .
##2.3
redo Space ManagementRedo The log file is named ib_logfile[number]
. Redo log writes files in a sequential manner. When it is full, it goes back to the first file and overwrites it. (But when doing redo checkpoint, the header checkpoint mark of the first log file will also be updated, so strictly speaking it is not counted as sequential writing). In fact, the redo log consists of two parts: the redo log buffer and the redo log file. In the buffer pool, data modifications are recorded to the redo log buffer. If the following occurs, the redo log is flushed to the redo log file:
Insufficient space in the Redo log buffer
-
Transaction submission (depends on innodb_flush_log_at_trx_commit parameter setting)
-
Background thread
-
Do checkpoint
-
Example shutdown
-
binlog switching
-
##3 How to record undo and redo transactions
3.1 Simplified process of Undo Redo transaction
Assume that there are two data A and B, with values 1 and 2 respectively. Start a transaction. The operation content of the transaction is: modify 1 is 3, and 2 is changed to 4, then the actual record is as follows (simplified): A. Transaction starts.
B. Record A=1 to undo log.
C. Modify A=3.
D. Record A=3 to redo log.
E. Record B=2 to undo log.
F. Modify B= 4.
G. Record B=4 to redo log.
H. Write redo log to disk.
I. Transaction submission
3.2 IO impact
The main purpose of designing Undo Redo is to improve input and output performance and increase the processing capacity of the database. It can be seen that B D E G H are all new operations, but B D E G is buffered to the buffer area. Only G adds IO operations. In order to ensure that Redo Log can have better IO performance, the design of InnoDB's Redo Log has the following Features: B. Try to ensure that Redo Log is stored in continuous space. Therefore, the space of the log file will be completely allocated when the system is started for the first time. In order to improve performance, Redo Log will be recorded in a sequential IO manner and completed in a step-by-step manner.
B. Write logs in batches. The log is not written directly to the file, but first written to the redo log buffer. When the log needs to be flushed to the disk (such as transaction submission), many logs are written to the disk together.
C. Concurrent transactions Sharing the storage space of Redo Log, their Redo Logs are recorded together alternately according to the execution order of statements to reduce the space occupied by the log. For example, the record content in Redo Log may be as follows:
Record 1:
Record 2:
Record 3:
Record 4:
Record 5:
D. Because of C, when a transaction writes the Redo Log to the disk, the logs of other uncommitted transactions will also be written to the disk.
E. Only sequential append operations are performed on the Redo Log. When a transaction needs to be rolled back, its Redo Log record will not be deleted from the Redo Log.
3.3 Recovery
As mentioned earlier, uncommitted transactions and rolled-back transactions will also be recorded in the Redo Log, so when recovering, these transactions must be processed specially of processing. There are 2 different recovery strategies:
A. When recovering, only redo the committed transactions.
When performing recovery, all transactions need to be re-executed, including uncommitted and rolled-back transactions. Then roll back those
uncommitted transactions through Undo Log.
The MySQL database InnoDB storage engine uses strategy B. The recovery mechanism in the InnoDB storage engine has several characteristics:
A. When redoing the Redo Log, and Don't care about transactionality. During recovery, there is no BEGIN, COMMIT, or ROLLBACK behavior. It doesn't matter which transaction each log belongs to. Although transaction-related content such as transaction ID will be recorded in the Redo Log, these contents are only regarded as part of the data to be operated.
B. When using strategy B, the Undo Log must be persisted, and the corresponding Undo Log must be written to the disk before writing the Redo Log. This relationship between Undo and Redo Log makes persistence complicated. In order to reduce complexity, InnoDB treats Undo Log as data, so the operation of recording Undo Log will also be recorded in redo log. By caching undo logs in memory, the necessity of writing redo logs to disk before writing them is avoided.
The Redo Log containing the Undo Log operation looks like this:
Record 1: Undo log insert > ;
Record 2:
Record 3: Undo log insert >
Record 4:
Record 5: Undo log insert >
Record 6: < ;trx3, delete …>
C. At this point, there is still an issue that remains unclear. Since Redo is not transactional, wouldn't it re-execute the rolled-back transaction?
Indeed it is. At the same time, Innodb will also record the operations during transaction rollback to the redo log. When a rollback operation is performed, the modifications to the data are recorded in the Redo Log, because the rollback operation essentially also modifies the data.
The Redo Log of a rolled-back transaction looks like this:
Record 1: >
Record 2: insert A…>
Record 3: >
Record 4: < ;trx1, update B…>
Record 5: >
Record 6: delete C…>
Record 7: insert C>
Record 8: update B to old value>
Record 9: delete A>
The recovery operation of a rolled-back transaction is to redo first and then undo, so it will not be destroyed Data consistency.
The above is the detailed content of How to set up mysql log files undo log and redo log. For more information, please follow other related articles on the PHP Chinese website!



 ##2.3
##2.3