
Home >Technology peripherals >AI >Cache optimization practice for large-scale deep learning training
Cache optimization practice for large-scale deep learning training

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-27 20:49:041427browse

1. Project background and caching strategy
First, let’s share the relevant background.
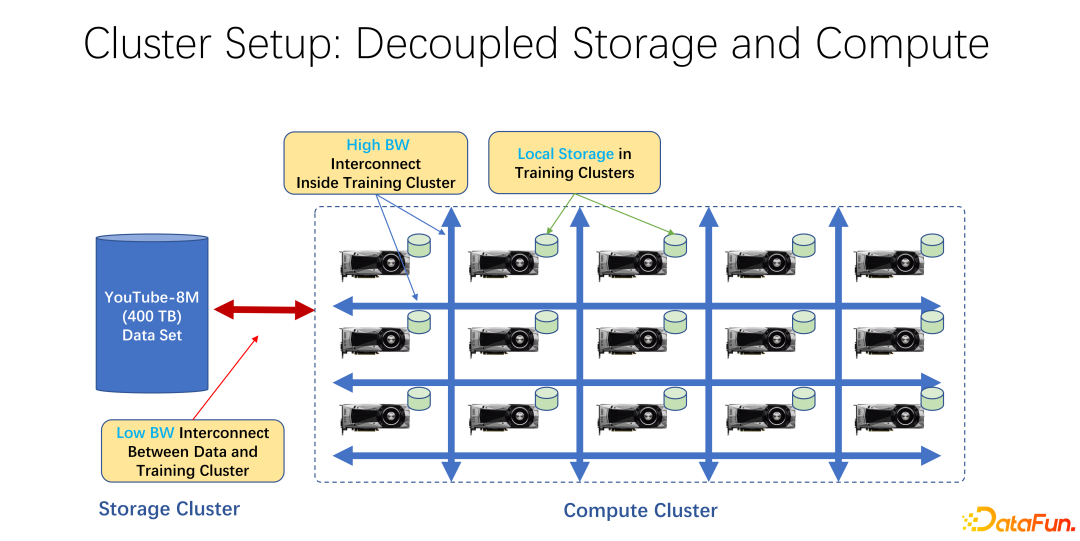
In recent years, AI training has become more and more widely used. From an infrastructure perspective, whether it is big data or AI training clusters, most of them use an architecture that separates storage and computing. For example, many GPU arrays are placed in a large computing cluster, and the other cluster is storage. It may also be using some cloud storage, such as Microsoft's Azure or Amazon's S3.
The characteristics of such an infrastructure are that, first of all, there are many very expensive GPUs in the computing cluster, and each GPU often has a certain amount of local storage, such as SSD. Such tens of terabytes of storage. In such an array of machines, a high-speed network is often used to connect to the remote end. For example, very large-scale training data such as Coco, image net, and YouTube 8M are connected through the network.
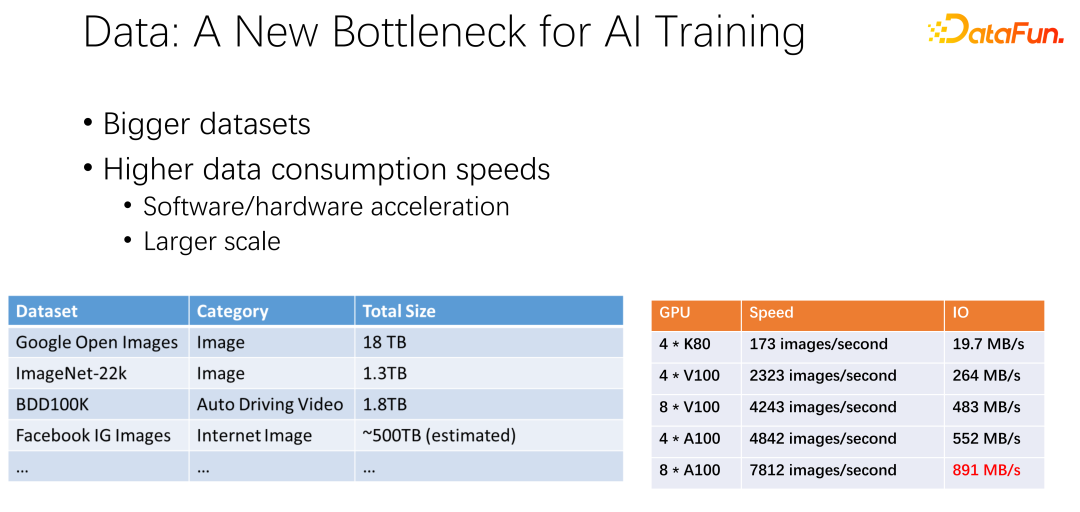
As shown in the figure above, data may become the bottleneck of the next AI training. We have observed that data sets are getting larger and larger, and as AI is more widely used, more training data is being accumulated. At the same time the GPU track is very volumetric. For example, manufacturers such as AMD and TPU have spent a lot of energy optimizing hardware and software to make accelerators, such as GPUs and TPUs, faster and faster. As accelerators are widely used within the company, cluster deployments are becoming larger and larger. The two tables here present some variation across datasets and GPU speeds. From the previous K80 to V100, P100, and A100, the speed is very fast. However, as they get faster, GPUs become more and more expensive. Whether our data, such as IO speed, can keep up with the speed of the GPU is a big challenge.

As shown in the figure above, in the applications of many large companies, we have observed such a phenomenon: when reading When accessing remote data, the GPU is idle. Because the GPU is waiting for remote data to be read, this means that IO becomes a bottleneck, causing expensive GPU to be wasted. There is a lot of optimization work being done to alleviate this bottleneck, and caching is one of the most important optimization directions. Here are two ways.

The first type is that in many application scenarios, especially in basic AI training architectures such as K8s plus Docker, a lot of local disks are used . As mentioned earlier, the GPU machine has certain local storage. You can use the local disk to do some caching and cache the data first.
After starting a GPU Docker, instead of starting the GPU AI training immediately, download the data first, download the data from the remote end to Docker, or mount it etc. Start training after downloading it to Docker. In this way, the subsequent training data reading can be turned into local data reading as much as possible. The performance of local IO is currently sufficient to support GPU training. On VLDB 2020, there is a paper, CoorDL, which is based on DALI for data caching.
This method also brings many problems. First of all, the local space is limited, which means that the cached data is also limited. When the data set becomes larger and larger, it is difficult to cache all the data. In addition, a big difference between AI scenarios and big data scenarios is that the data sets in AI scenarios are relatively limited. Unlike big data scenarios where there are many tables and various businesses, the content gap between the data tables of each business is very large. In AI scenarios, the size and number of data sets are much smaller than in big data scenarios. Therefore, it is often found that many tasks submitted in the company read the same data. If everyone downloads the data to their own local machine, it cannot be shared, and many copies of the data will be repeatedly stored on the local machine. This approach obviously has many problems and is not efficient enough.
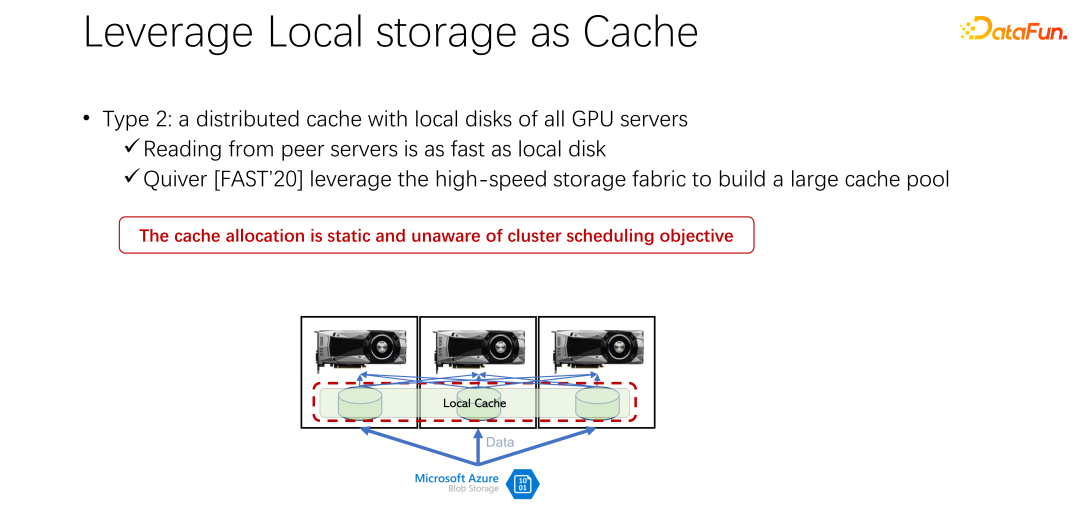
The second method is introduced next. Since local storage is not very good, can we use a distributed cache like Alluxio to alleviate the problem just now? The distributed cache has a very large capacity to load data. In addition, Alluxio, as a distributed cache, is easy to share. The data is downloaded to Alluxio, and other clients can also read this data from the cache. It seems that using Alluxio can easily solve the problems mentioned above and greatly improve AI training performance. A paper titled Quiver published by Microsoft India Research at FAST2020 mentioned this solution. However, our analysis found that such a seemingly perfect allocation plan is still relatively static and not efficient. At the same time, what kind of cache elimination algorithm should be used is also a question worthy of discussion.
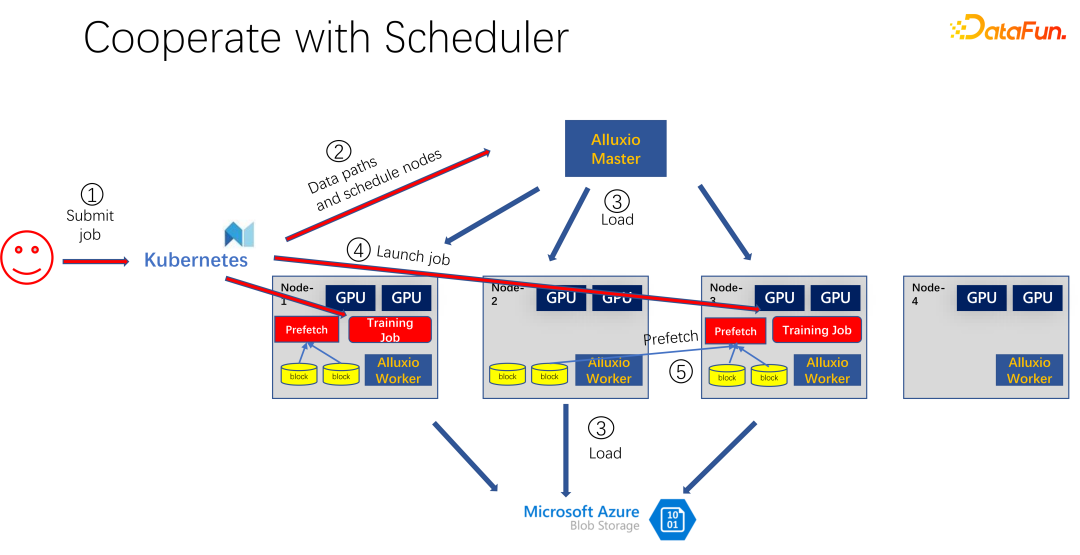
As shown in the figure above, it is an application that uses Alluxio as a cache for AI training. Use K8s to schedule the entire cluster task and manage resources such as GPU, CPU, and memory. When a user submits a task to K8s, K8s will first make a plug-in and notify the Alluxio master to download this part of the data. That is to say, do some warm-up first and try to cache some tasks that may be required for the job. Of course, it doesn’t have to be cached completely, because Alluxio uses as much data as it has. The rest, if it has not yet been cached, is read from the remote end. In addition, after Alluxio master gets such a command, it can ask its worker to go to the remote end. It may be cloud storage, or it may be a Hadoop cluster downloading the data. At this time, K8s will also schedule the job to the GPU cluster. For example, in the figure above, in such a cluster, it selects the first node and the third node to start the training task. After starting the training task, data needs to be read. In the current mainstream frameworks such as PyTorch and Tensorflow, Prefetch is also built-in, which means pre-reading of data. It reads the cached data in Alluxio that has been cached in advance to provide support for training data IO. Of course, if it is found that there is some data that has not been read, Alluxio can also read it remotely. Alluxio is great as a unified interface. At the same time, it can also share data across jobs.
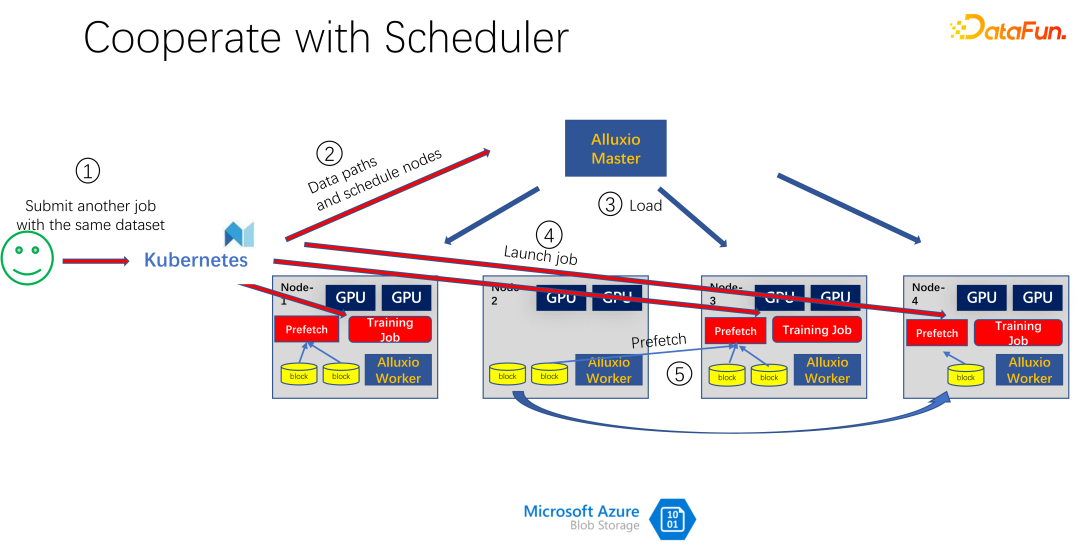
As shown in the picture above, for example, another person submitted another job with the same data, consuming the same Data set, at this time, when submitting the job to K8s, Alluxio will know that this part of the data already exists. If Alluxio wants to do better, it can even know which machine the data will be scheduled to. For example, it is scheduled to node 1, node 3 and node 4 at this time. You can even make some copies of node 4 data. In this way, all data, even within Alluxio, does not need to be read across machines, but is read locally. So it seems that Alluxio has greatly alleviated and optimized the IO problems in AI training. But if you look closely, you will find two problems.

The first problem is that the cache elimination algorithm is very inefficient, because in AI scenarios, the mode of accessing data is very different from the past. The second problem is that cache, as a resource, has an antagonistic relationship with bandwidth (that is, the read speed of remote storage). If the cache is large, then there is less chance of reading data from the remote end. If the cache is small, a lot of data has to be read from the remote end. How to schedule and allocate these resources well is also an issue that needs to be considered.
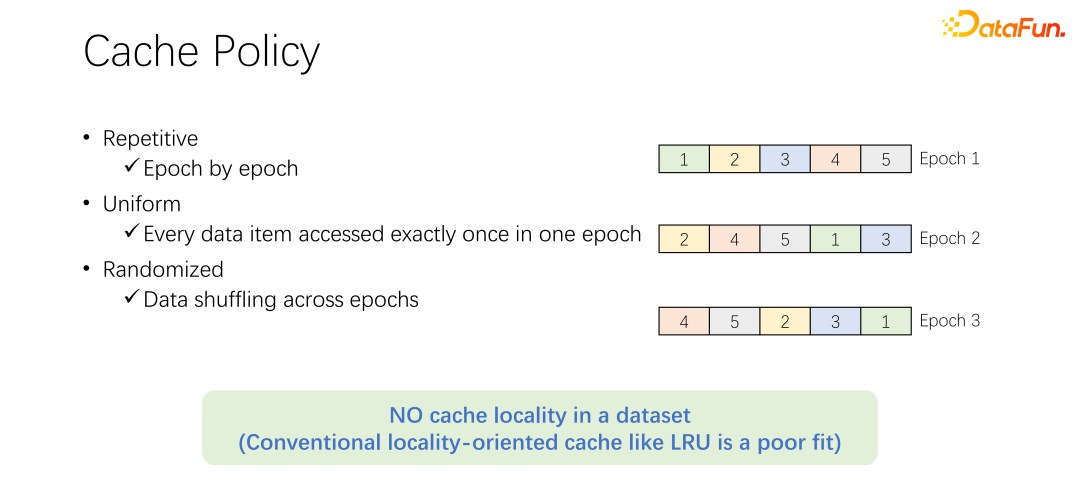 Before discussing the cache elimination algorithm, let’s first take a look at the process of data access in AI training. In AI training, it will be divided into many epochs and trained iteratively. In each training epoch, each piece of data will be read and only read once. In order to prevent over-fitting of training, after each epoch ends, in the next epoch, the reading order will change and a shuffle will be performed. That is to say, all data will be read once every epoch, but the order is different.
Before discussing the cache elimination algorithm, let’s first take a look at the process of data access in AI training. In AI training, it will be divided into many epochs and trained iteratively. In each training epoch, each piece of data will be read and only read once. In order to prevent over-fitting of training, after each epoch ends, in the next epoch, the reading order will change and a shuffle will be performed. That is to say, all data will be read once every epoch, but the order is different.
The default LRU elimination algorithm in Alluxio obviously cannot be well applied to AI training scenarios. Because LRU takes advantage of cache locality. Locality is divided into two aspects. The first is time locality, that is, the data accessed now may be accessed soon. This does not exist in AI training. Because the data accessed now will only be accessed in the next round, and will be accessed in the next round. There is no particular probability that data is more accessible than other data. On the other side is data locality, and also spatial locality. In other words, why Alluxio uses relatively large blocks to cache data is because when a certain piece of data is read, surrounding data may also be read. For example, in big data scenarios, OLA
P applications often scan tables, which means that surrounding data will be accessed immediately. But it cannot be applied in AI training scenarios. Because it is shuffled every time, the order of reading is different every time. Therefore, the LRU elimination algorithm is not suitable for AI training scenarios.

Not only LRU, but also mainstream elimination algorithms such as LFU have such a problem . Because the entire AI training has very equal access to data. Therefore, you can use the simplest caching algorithm, which only needs to cache a part of the data and never needs to touch it. After a job comes, only a part of the data is always cached. Never eliminate it. No elimination algorithm is required. This is probably the best elimination mechanism out there.
#As shown in the example above. Above is the LRU algorithm and below is the equalization method. Only two pieces of data can be cached at the beginning. Let's simplify the problem. It has only two pieces of capacity, cache D and B, and the middle is the access sequence. For example, the first accessed one is B. If it is LRU, B is hit in the cache. The next access is C. C is not in the cache of D and B. Therefore, based on the LRU policy, D will be replaced and C will be retained. That is, the caches are C and B at this time. The next one visited is A, which is also not in C and B. So B will be eliminated and replaced with C and A. The next one is D, and D is not in the cache, so it is replaced by D and A. By analogy, you will find that all subsequent accesses will not hit the cache. The reason is that when LRU caching is performed, it is replaced, but in fact it has been accessed once in an epoch, and it will never be accessed again in this epoch. LRU caches it instead. Not only does LRU not help, it actually makes it worse. It is better to use uniform, such as the following method.
#The following uniform method always caches D and B in the cache and never makes any replacement. In this case, you will find at least a 50% hit rate. So you can see that the caching algorithm does not need to be complicated. Just use uniform. Do not use algorithms such as LRU and LFU.
Regarding the second question, which is about the relationship between cache and remote bandwidth. Data read-ahead is now built into all mainstream AI frameworks to prevent the GPU from waiting for data. So when the GPU is training, it actually triggers the CPU to pre-prepare data that may be used in the next round. This can make full use of the computing power of the GPU. But when the IO of remote storage becomes a bottleneck, it means that the GPU has to wait for the CPU. Therefore, the GPU will have a lot of idle time, resulting in a waste of resources. I hope there can be a better scheduling management method to alleviate IO problems.

Cache and remote IO have a great impact on the throughput of the entire job. So in addition to GPU, CPU and memory, cache and network also need to be scheduled. In the past development process of big data, such as Hadoop, yarn, my source, K8s, etc., mainly scheduled CPU, memory, and GPU. The control over the network, especially the cache, is not very good. Therefore, we believe that in AI scenarios, they need to be well scheduled and allocated to achieve the optimization of the entire cluster.
2. SiloD Framework

Published this at EuroSys 2023 article, it is a unified framework to schedule computing resources and storage resources.
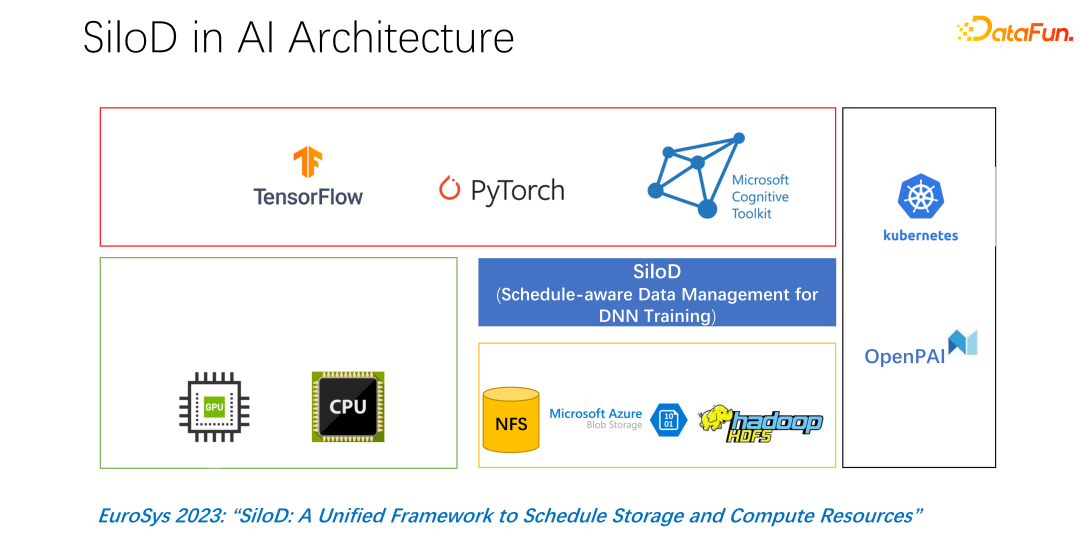
The overall architecture is shown in the figure above. The lower left corner is the CPU and GPU hardware computing resources in the cluster, as well as storage resources, such as NFS, cloud storage HDFS, etc. At the upper level, there are some AI training frameworks such as TensorFlow, PyTorch, etc. We believe that we need to add a plug-in that uniformly manages and allocates computing and storage resources, which is what we proposed SiloD.
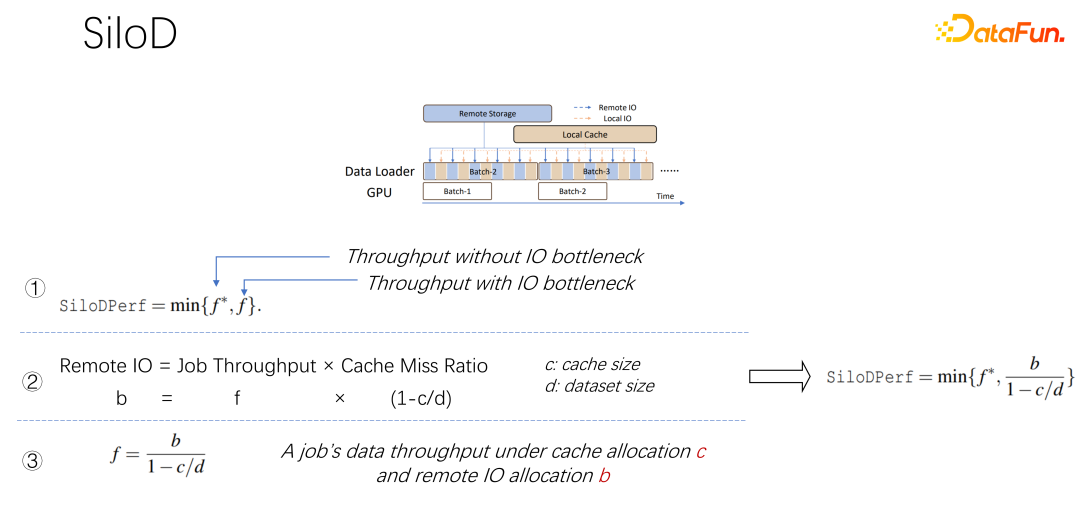
As shown in the figure above, what kind of throughput and performance a job can achieve is determined by the minimum GPU and IO value determined. How many remote IOs are used, how much remote networking is used. The access speed can be calculated through such a formula. The job speed is multiplied by the cache miss rate, which is (1-c/d). Where c is the size of the cache and d is the data set. This means that when data only considers IO and may become a bottleneck, the approximate throughput is equal to (b/(1-c/d)), where b is the remote bandwidth. Combining the above three formulas, we can deduce the formula on the right, which is what kind of performance a job ultimately wants to achieve. You can use the formula to calculate the performance when there is no IO bottleneck and the performance when there is an IO bottleneck. Take the one between the two. minimum value.
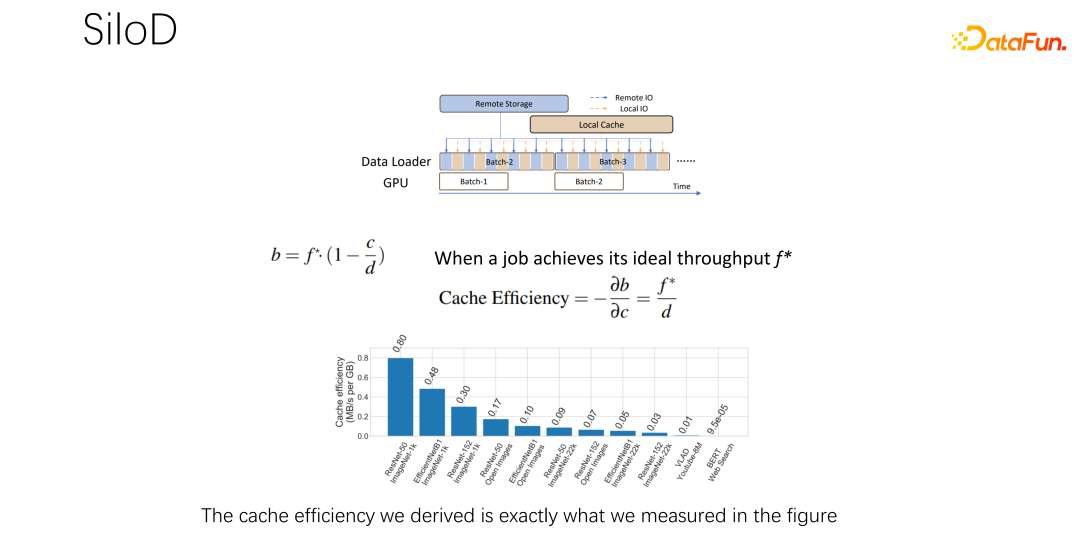
After getting the above formula, differentiate it to get the effective cache value performance, or cache efficiency. That is, although there are many jobs, they cannot be treated equally when allocating cache. Each job, based on different data sets and speeds, is very particular about how much cache is allocated. Here is an example, taking this formula as an example. If you find a job that is very fast and trains very quickly, and the data set is small, this means allocating a larger cache and the benefits will be greater.
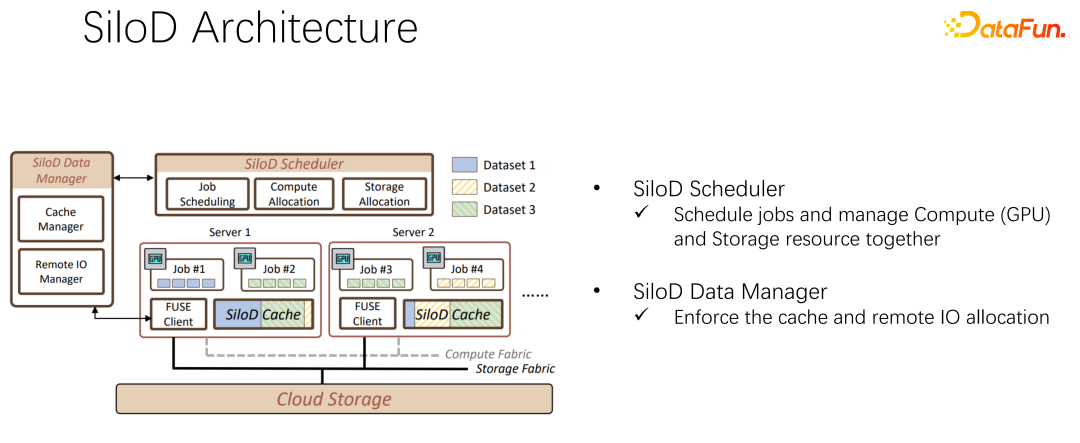
Based on the above observations, SiloD can be used for cache and network allocation. Moreover, the size of the cache is allocated based on the speed of each job and the entire size of the data set. The same goes for the web. So the whole architecture is like this: in addition to mainstream job scheduling like K8s, there is also data management. On the left side of the figure, for example, cache management requires statistics or monitoring of the cache size allocated to the entire cluster, the cache size of each job, and the size of remote IO used by each job. The following operations are very similar to the Alluxio method, and both can use APIs for data training. Use cache on each worker to provide caching support for local jobs. Of course, it can also span nodes in a cluster and can also be shared.
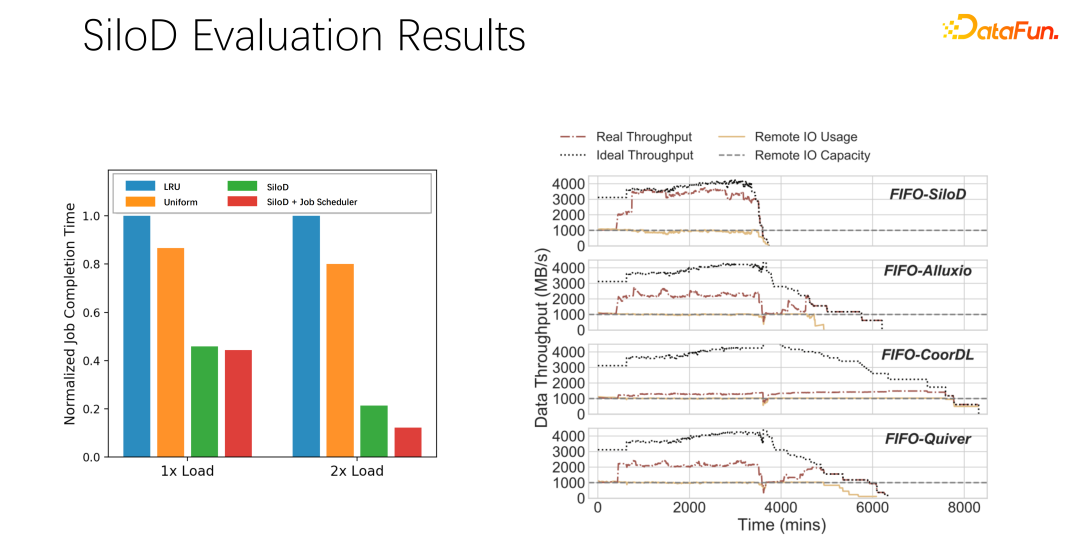
After preliminary testing and experiments, it was found that such an allocation method can improve the utilization and throughput of the entire cluster. A very obvious improvement, which can reach up to 8 times of performance improvement. It can obviously alleviate the status of job waiting and GPU idleness.

## Let’s summarize the above introduction:
First, In AI or deep learning training scenarios, traditional caching strategies such as LRU and LFU are not suitable. It is better to use uniform directly.
Second, #Cache and remote bandwidth are a pair of partners, which play a great role in overall performance role.
Third, Major scheduling frameworks such as K8s and yarn can be easily inherited from SiloD.
Finally, We did some experiments in the paper. Different scheduling strategies can bring The throughput is obviously improved.
3. Distributed cache strategy and copy management
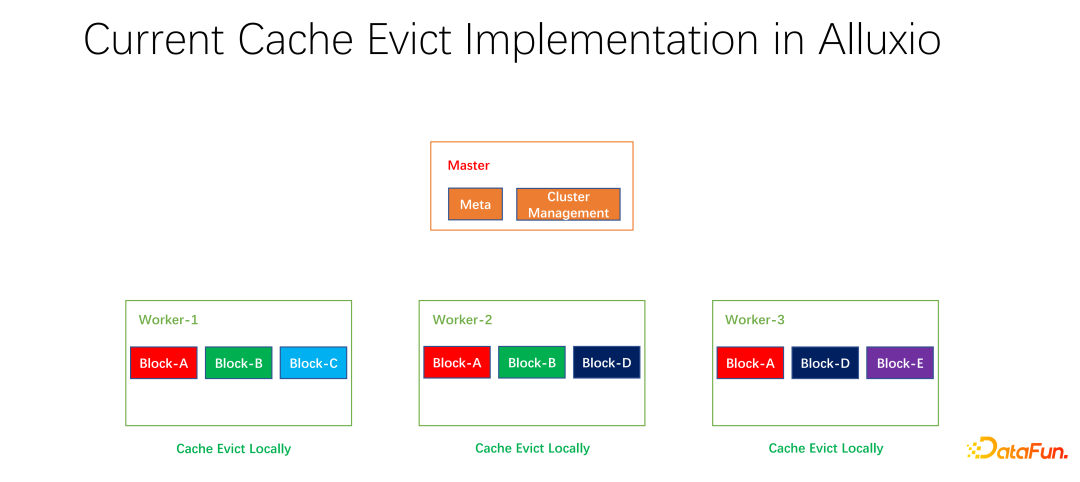
We have also done some open source work. This work on distributed caching strategy and replica management has been submitted to the community and is now in the PR stage. Alluxio master is mainly responsible for the management of Meta and the management of the entire worker cluster. It is the worker that actually caches the data. There are many blocks in units of blocks to cache data. One problem is that the current caching strategies are for a single worker. When calculating whether to eliminate each data within the worker, it only needs to be calculated on one worker and is localized.
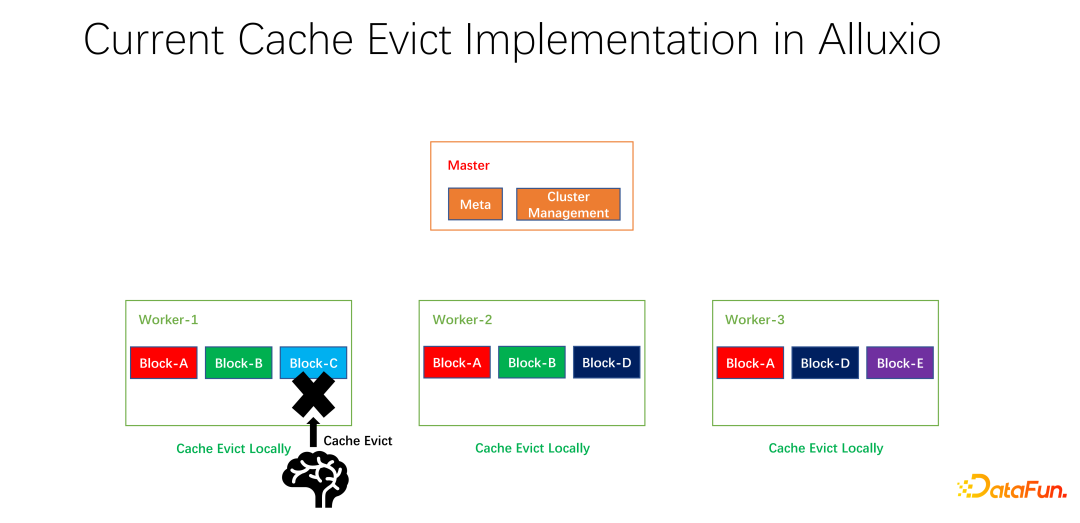
As shown in the example above, if there is block A on worker 1, block B And block C, based on LRU calculation, block C will be eliminated if it has not been used for the longest time. If you look at the overall situation, you will find that this is not good. Because block C has only one copy in the entire cluster. After it is eliminated, if someone else wants to access block C, they can only pull data from the remote end, which will cause performance and cost losses. We propose a global elimination strategy. In this case, block C should not be eliminated, but the one with more copies should be eliminated. In this example, block A should be eliminated because it still has two copies on other nodes, which is better in terms of cost and performance.
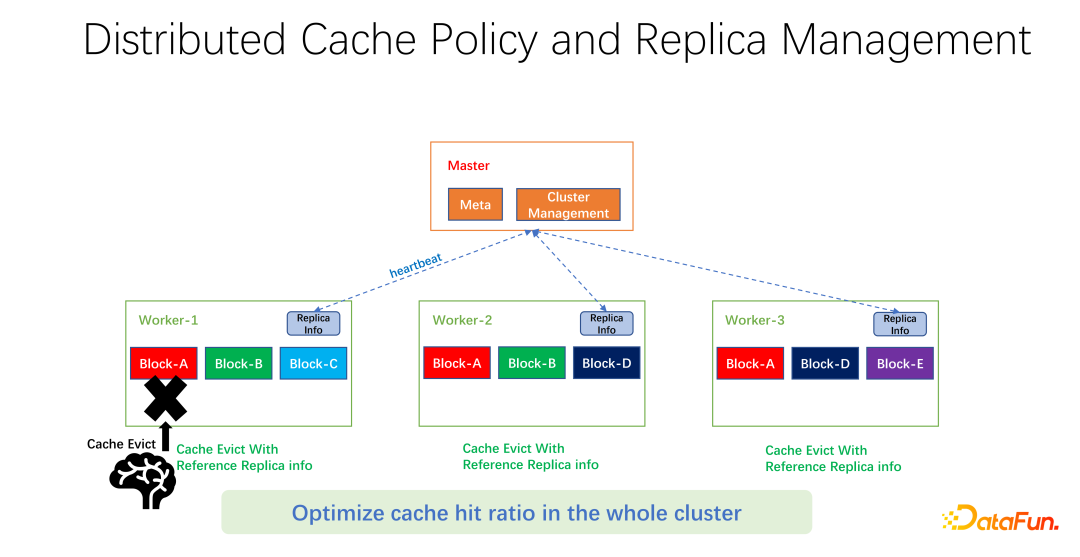
As shown in the figure above, what we do is to maintain replica information on each worker. When a worker, for example, adds a copy or removes a copy, it will first report to the master, and the master will use this information as a heartbeat return value and return it to other related workers. Other workers can know the real-time changes of the entire global copy. At the same time, the copy information is updated. Therefore, when eliminating internal workers, you can know how many copies each worker has in the entire world, and you can design some weights. For example, LRU is still used, but the weight of the number of replicas is added to comprehensively consider which data to eliminate and replace.
#After our preliminary testing, it can bring great improvements in many fields, whether it is big data or AI training. So it's not just about optimizing cache hits for one worker on one machine. Our goal is to improve the cache hit rate of the entire cluster.

##Finally, let’s summarize the full text. First of all, in AI training scenarios, the uniform cache elimination algorithm is better than the traditional LRU and LFU. Second, cache and remote networking are also resources that need to be allocated and scheduled. Third, when optimizing cache, don’t just limit it to one job or one worker. You should take into account the entire end-to-end global parameters, so that the efficiency and performance of the entire cluster can be better improved.
The above is the detailed content of Cache optimization practice for large-scale deep learning training. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology