
Home >Technology peripherals >AI >Double-killing OpenAI in scale and performance, Meta Voice reaches LLaMA-level milestone! Open source MMS model recognizes 1100+ languages
Double-killing OpenAI in scale and performance, Meta Voice reaches LLaMA-level milestone! Open source MMS model recognizes 1100+ languages

- PHPzforward
- 2023-05-24 16:25:061387browse
In terms of voice, Meta has reached another LLaMA-level milestone.
Today, Meta launches a large-scale multilingual voice project called MMS that will revolutionize voice technology.
MMS supports over 1,000 languages, is trained on the Bible, and has an error rate half that of the Whisper dataset.
With just one model, Meta built a Tower of Babel.
Moreover, Meta has chosen to make all models and codes open source, hoping to contribute to protecting the diversity of world languages.

The previous model could cover about 100 languages, but this time, MMS directly increased this number by 10-40 times!
Specifically, Meta has opened up multilingual speech recognition/synthesis models in more than 1,100 languages, and speech recognition models in more than 4,000 languages.
Compared to OpenAI Whisper, the multilingual ASR model supports 11 times more languages, but the average error rate on 54 languages is less than half of FLEURS.
Moreover, extending ASR to so many languages results in only a very small performance degradation.
Paper address: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Protect disappearing languages, MMS increases speech recognition 40 times
Let the machine have the ability to recognize and generate speech, allowing more people to obtain information.
However, generating high-quality machine learning models for these tasks requires large amounts of labeled data, such as thousands of hours of audio and transcriptions - which for most languages This kind of data simply does not exist.
Existing speech recognition models only cover about 100 languages, which is only a small part of the more than 7,000 known languages on the planet. Worryingly, half of these languages are in danger of disappearing within our lifetimes.
In the Massively Multilingual Speech (MMS) project, researchers overcome some of this by combining wav2vec 2.0 (Meta’s pioneering work in self-supervised learning) with a new dataset challenge.
This dataset provides labeled data in more than 1,100 languages, and unlabeled data in nearly 4,000 languages.

Through cross-language training, wav2vec 2.0 learns phonetic units used in multiple languages
Some of these languages, like Tatuyo, have only a few hundred speakers, and for most of the languages in the dataset, speech technology simply didn’t exist before.
The results show that the performance of the MMS model is better than the existing model, and the number of languages covered is 10 times that of the existing model.
Meta has always focused on multilingual work: on text, Meta’s NLLB project expanded multilingual translation to 200 languages, while the MMS project expanded speech technology to more language.
Bible solves the speech data set problem
Collecting audio data in thousands of languages is not a simple matter, and this is also the first problem faced by Meta researchers a challenge.
You should know that the largest existing speech data set only covers 100 languages at most. To overcome this problem, researchers have turned to religious texts such as the Bible.
Such texts have been translated into many different languages, used in extensive research, and various public recordings have been made.
To this end, Meta researchers have specially created a New Testament reading data set in more than 1,100 languages, providing an average of 32 hours of data per language.
With the addition of untagged recordings of various other religious texts, the researchers increased the number of available languages to more than 4,000.
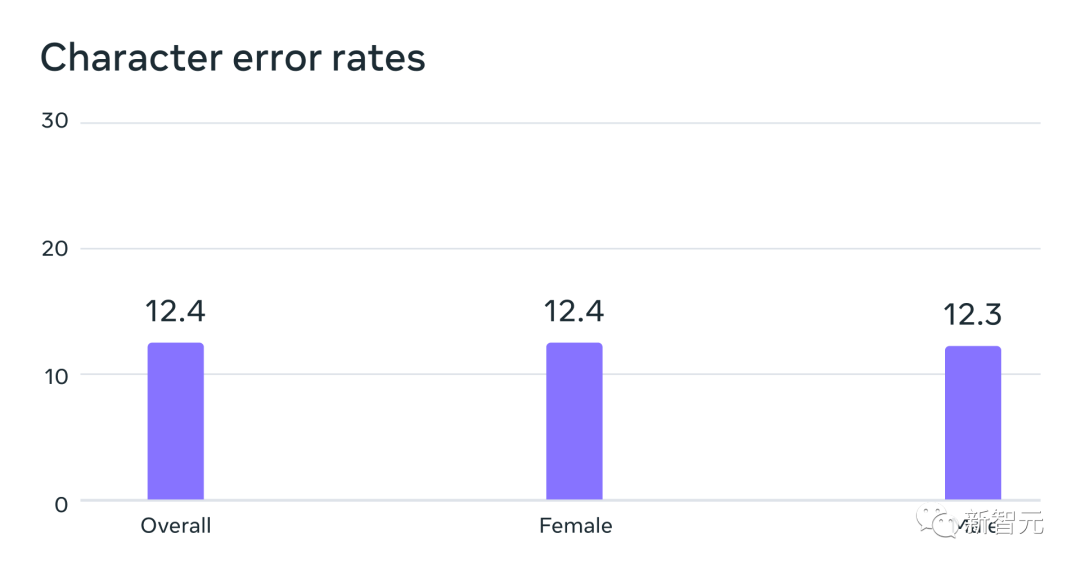
Automatic speech recognition model trained on MMS data has similar performance for male and female speakers on the FLEURS benchmark Error rate
#The data is typically spoken by men, but the model performs equally well on male and female voices.
And, although the content of the recordings was religious, this did not overly bias the model toward producing more religious language.
The researchers believe this is because they used a connectionist temporal classification method, which is less restrictive than large language models or sequence-to-sequence models used for speech recognition. Much larger.
The bigger the model, the better it can fight?
The researchers first preprocessed the data to improve its quality and enable it to be utilized by machine learning algorithms.
To do this, the researchers trained an alignment model on existing data in more than 100 languages and used this model with an efficient forced alignment algorithm, which Can handle recordings of approximately 20 minutes or more.
The researchers repeated this process multiple times and performed a final cross-validation filtering step based on the accuracy of the model to remove potential misaligned data.
To enable other researchers to create new speech datasets, the researchers added the alignment algorithm to PyTorch and released the alignment model.
Currently, there are 32 hours of data for each language, but this is not enough to train traditional supervised speech recognition models.
This is why researchers train models on wav2vec 2.0, which can greatly reduce the amount of annotated data required to train a model.
Specifically, the researchers trained the self-supervised model on approximately 500,000 hours of speech data in more than 1,400 languages—nearly five times more than in the past.
Then researchers can fine-tune the model for specific speech tasks, such as multilingual speech recognition or language recognition.
To better understand the performance of models trained on large-scale multilingual speech data, the researchers evaluated them on existing benchmark datasets.
The researchers used a 1B parameter wav2vec 2.0 model to train a multilingual speech recognition model for more than 1,100 languages.
Performance does decrease as the number of languages increases, but the decrease is mild - from 61 languages to 1107 languages, the character error rate only increases by about 0.4 %, but the language coverage increased by more than 18 times.
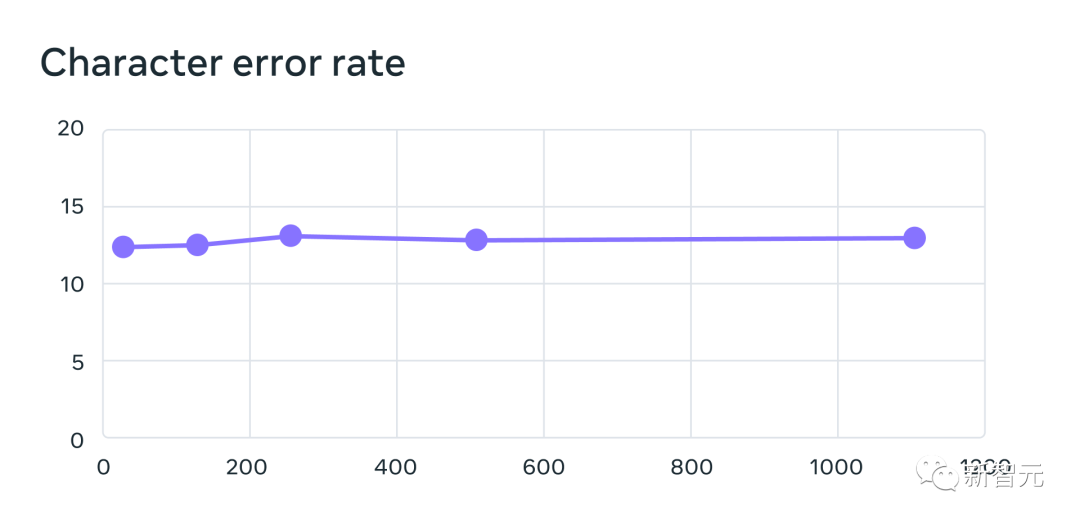
61 of a multi-language recognition system trained using MMS data when increasing the number of languages supported by each system from 61 to 1,107 Error rates for FLEURS languages. Higher error rates indicate lower performance
In an apples-to-apples comparison with OpenAI’s Whisper, the researchers found that nearly half of the models trained on Massively Multilingual Speech data word error rate, but Massively Multilingual Speech covers 11 times more languages than Whisper.
We can see from the data that compared with the current best speech models, Meta’s model performs really well.
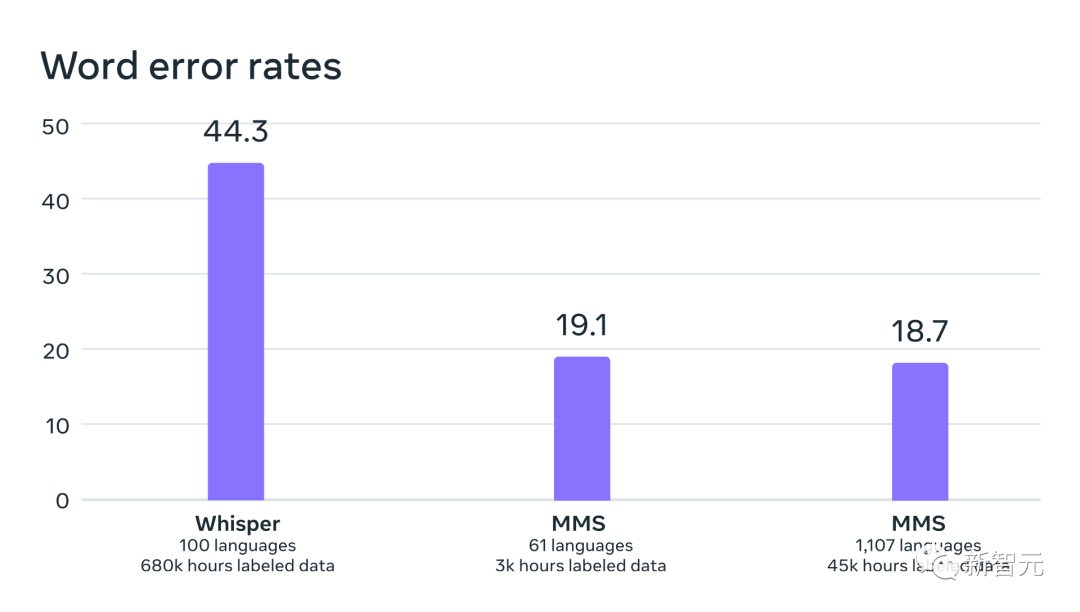
Comparison of word error rates between OpenAI Whisper and Massively Multilingual Speech on 54 FLEURS languages
Next, the researchers trained a language identification (LID) model for over 4,000 languages using their own and existing datasets such as FLEURS and CommonVoice and evaluated it on the FLEURS LID task.
Facts have proved that even if it supports nearly 40 times the number of languages, the performance is still very good.
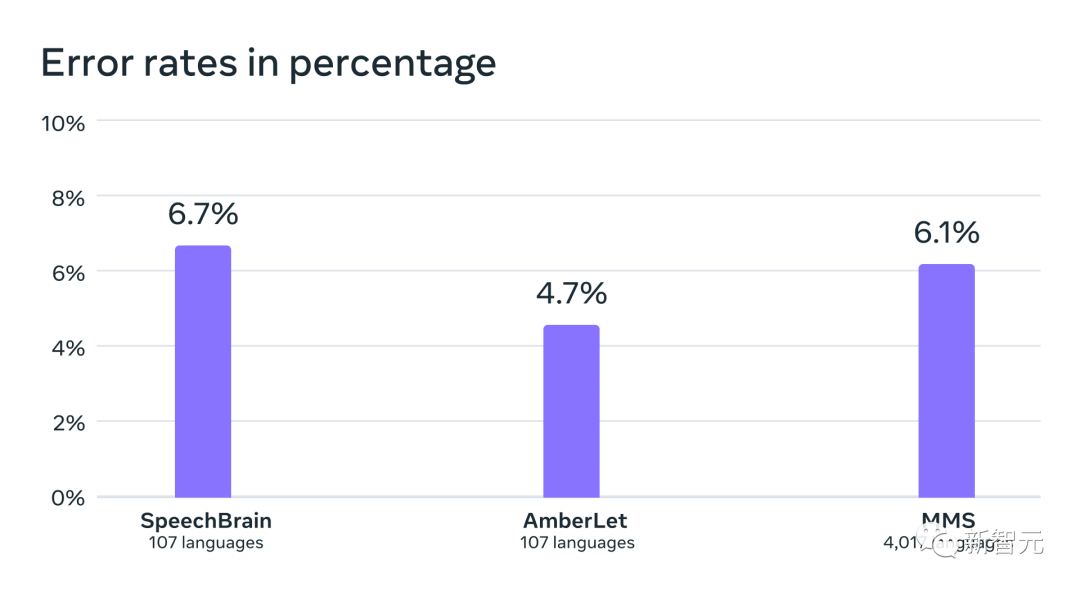
Language recognition accuracy on the VoxLingua-107 benchmark of existing work, supporting just over 100 languages, and MMS It supports more than 4,000 languages.
The researchers have also built text-to-speech systems for more than 1,100 languages.
One limitation of large-scale multilingual speech data is that for many languages it contains a relatively small number of different speakers, often just one speaker.
However, this feature is an advantage for building text-to-speech systems, so researchers have trained similar systems for more than 1,100 languages.
The results show that the speech quality produced by these systems is not bad.
The future belongs to a single model
Meta’s researchers are pleased with the results, but like all emerging AI technologies, Meta’s current model is not perfect. .
For example, a speech-to-text model may mischaracterize selected words or phrases, potentially resulting in offensive or inaccurate output.
At the same time, Meta believes that the cooperation of AI giants is crucial to the development of responsible AI technology.
Many of the world’s languages are in danger of disappearing, and the limitations of current speech recognition and speech generation technology will only accelerate this trend.
Researchers envision a world where technology has the opposite effect, encouraging people to keep their languages alive because they can access information and use technology by speaking their preferred language.
The large-scale multilingual speech project is an important step in this direction.
In the future, researchers hope to further increase language coverage, support more languages, and even find ways to handle dialects. You know, dialects are not simple for existing speech technology.
Meta’s ultimate goal is to make it easier for people to access information and use devices in their preferred language.
Finally, Meta researchers also envisioned a future scenario where a single model can solve several speech tasks in all languages.
Although Meta currently trains separate models for speech recognition, speech synthesis and language recognition, the researchers believe that in the future, only one model will be able to complete all these tasks, even more than.
The above is the detailed content of Double-killing OpenAI in scale and performance, Meta Voice reaches LLaMA-level milestone! Open source MMS model recognizes 1100+ languages. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology