
Home >Technology peripherals >AI >Research on the possibility of building a visual language model from a set of words
Research on the possibility of building a visual language model from a set of words

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-21 23:22:041478browse
Translator | Zhu Xianzhong
Reviewer| Chonglou
##Currently, Multi-modal artificial intelligencehas become a hot topic discussed in the streets. With the recent release of GPT-4, we are seeing countless possible new applications and future technologies that were unimaginable just six months ago. In fact, visual language models are generally useful for many different tasks. For example, you can use CLIP (Contrastive Language-Image Pre-training, that is "Contrastive Language-Image Pre-training", link: https://www.php.cn/link/b02d46e8a3d8d9fd6028f3f2c2495864Zero-shot image classification on unseen data sets;Usually In this case, excellent performance can be obtained without any training.
At the same time, the visual language model is not perfect. In this article In , wewillexplore the limitations of these models, highlighting where and why they may fail.In fact, This article is a short/high-level description of our recent to be published paper Plan will be presented in the form of ICLR 2023 Oral Published. If you want to view this article about the complete source code, just click the link https://www.php.cn/link/afb992000fcf79ef7a53fffde9c8e044.
IntroductionWhat is a visual language model?Visual language models exploit the connection between visual and language data Synergy to perform various tasks has revolutionized the field. Although many visual language models have been introduced in the existing literature, CLIP (Compare Language-Image Pre-training) is still the best-known and most widely used model. By embedding images and captions in the same vector space, the CLIP model allows cross-modal reasoning, enabling users to perform tasks such as zero-shot images with good accuracy Tasks such as classification and text-to-image retrieval. Moreover, the CLIP model uses contrastive learning methods to learn image and title embeddings.
Introduction to Contrastive Learning Contrastive learning allows CLIP models to learn to associate images with their corresponding captions
by minimizing the distance between images in a shared vector space. CLIP models and others The impressive results achieved by the contrast-based model prove that this approach is very effective.
Contrast loss is used in comparison batches of image and title pairs, and optimize the model to maximize the similarity between embeddings of matching image-text pairs and reduce the similarity between other image-text pairs in the batch Similarity.
The figure belowshowsan example of possible batch processing and training steps
, Where:
- The purple square contains the embeds for all titles, and the green square contains the embeds for all images.
- The square of the matrix contains the dot product of all image embeddings and all text embeddings in the batch (read as "cosine similarity" because the embeddings are normalized ).
- The blue squares contain the dot products between image-text pairs for which the model must maximize the similarity, the other white squares are the similarities we wish to minimize (because each of these squares contains similarities in unmatched image-text pairs, such as an image of a cat and the description "my vintage chair" ).
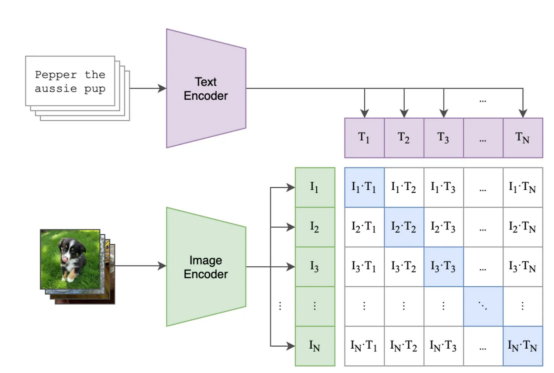
(Among them, The blue squares are the image-text pairs for which we want to optimize similarity )
After training, you should be able to generate a A meaningful vector space that encodes images andtitles. Once you have embedded content for each image and each text, you can do a number of tasks, such as see which images are more match the title (e.g. find "dogs on the beach" in the 2017 summer vacation photo album), Or find which text label is more like a given image (e.g. you have a bunch of images of your dog and cat and you want to be able to identify which is which). Visual language models such as CLIP have become powerful tools for solving complex artificial intelligence tasks by integrating visual and linguistic information. Their ability to embed both types of data into a shared vector space has led to unprecedented success in a wide range of applications Accuracy and superior performance.
Can visual language models understand language?What we
’s workis exactly trying to take some measures to answer this question. Regarding the question of whether or to what extent deep models can understand language, There are still significant debates. Here, our goal is to study visual language models and their synthesis capabilities.We first propose a new dataset to test ingredient understanding; this new benchmark is called ARO (Attribution,
Relations,and Order: Attributes, relationships and orders). Next, we explore why contrast loss may be limited in this case. Finally , we propose a simple but promising solution to this problem.New benchmark: ARO (Attributes, Relations, and Order) How well do models like CLIP (and Salesforce's recent BLIP) do at understanding language
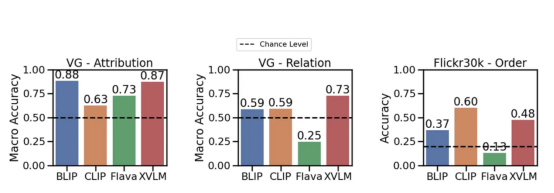
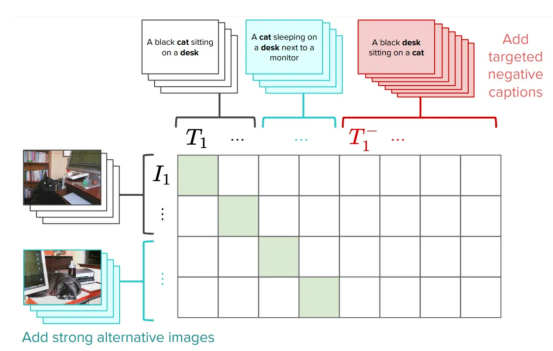
? We have collected a set of attribute-based compositions titles (e.g. "the red door and the standing man"(red door and standing person)) and a set of relationship-based composition title( For example "the horse is eating the grass" (马在吃草)) and matching images. Then, we generate a fake title instead of , such as "the grass is eating the horse" ( The grass is eating the horse). Can the models find the right title? We also explored the effect of shuffling words: Does the model prefer unshuffled Title to shuffled Title? Attributes, Relationships and Orders (ARO) #The four datasets created are shown below (please note that the sequence part contains two datasets): include Relation, Attribution and Order. For each dataset, we show an image example and a different title. Among them, only one title is correct, and the model must identify this correct title. Well, maybe it’s the BLIP model, because it can’t understand the difference between “the horse is eating grass” and “the grass is eating grass”: The BLIP model does not understand the difference between "the grass is eating grass" and "the horse is eating grass"(where Contains elements from the Visual Genome dataset, Image provided by the author) Now,let’s seeexperimentresult: Few models can go beyond the possibility of understanding relationships to a large extent (e.g., eating——Have a meal). However, CLIPModel is in Attributes and Relationships The edge aspect is slightly higher than this possibility. This actually shows that the visual language modelstillhas a problem. Different models have different attributes in attributes, relationships and order (Flick30k ) performance on benchmarks. used CLIP, BLIP and other SoTA models One of the main results of this work is that we may need more than the standard contrastive loss to learn language. This is why? titles, which TitleRequires understanding of composition (for example, "the orange cat is on the red table": The orange cat is on the red table). So, if the title is complex, why can’t the model learn composition understanding? ]Searching on these datasets does not necessarily require an understanding of composition. "books the looking at people are"? If the answer is yes;that means,no instruction information is needed to find the correct image. The task of our test model is to retrieve using scrambled titles. Even if we scramble the captions, the model can correctly find the corresponding image (and vice versa). This suggests that the retrieval task may be too simple,Image provided by the author. We tested different shuffle processes and the results were positive: even with different Out-of-order technology, the retrieval performance will basically not be affected. Let us say it again: the visual language model achieves high-performance retrieval on these datasets, even when the instruction information is inaccessible. These models might behave like astack of words, where the order doesn't matter: if the model doesn't need to understand word order in order to performs well in retrieval, so what are we actually measuring in retrieval? Now that we know there is a problem, we might want to look for a solution. The simplest way is: let CLIPmodel understand that "the cat is on the table" and "the table is on the cat" are different. In fact, one of the ways we suggested is to improve CLIPtraining by adding a hard negative made specifically to solve this problem. This is a very simple and efficient solution: it requires very small edits to the original CLIP loss without affecting the overall performance (you can read some caveats in the paper). We call this version of CLIP NegCLIP. Introducing a hard negative into the CLIP model (We added image and text hard negative, Picture provided by the author) Basically, we ask NegCLIPmodelto place an image of a black cat on "a black cat sitting on a desk" (黑猫 sitting on the desk)near this sentence, but far away from the sentence" a black desk sitting on a cat. Note that the latter is automatically generated by using POS tags. The effect of this fix is that it actually improves the performance of the ARO benchmark without harming retrieval performance or the performance of downstream tasks such as retrieval and classification . See the figure below for results on different benchmarks (see this papercorresponding paper for details). NegCLIPmodel and CLIPmodel on different benchmarks. Among them, the blue benchmark is the benchmark we introduced, and the green benchmark comes from the networkliterature( Image provided by the author) You can see that there is a huge improvement here compared to the ARO baseline, There are also edge improvements or similar performance on other downstream tasks. Mert(The lead author of the paper) has done a great job creating a small library to test visual language models. You can use his code to replicate our results or experiment with new models. All it takes to download the dataset and start running is a few a few linesPython language : NegCLIP model (It is actually an updated copy of OpenCLIP), and its complete code download address is https://github.com/vinid/neg_clip. Conclusion Visual language modelCurrently You can already do a lot of things. Next,We can’t wait to see what future models like GPT4 can do! Translator introduction
Original title: ##Your Vision-Language Model Might Be a Bag of Words , Author: Federico Bianchi The different data sets we created
The different data sets we created

Retrieval and contrastive loss evaluation
What to do?
Programming implementation
import clip
from dataset_zoo import VG_Relation, VG_Attribution
model, image_preprocess = clip.load("ViT-B/32", device="cuda")
root_dir="/path/to/aro/datasets"
#把 download设置为True将把数据集下载到路径`root_dir`——如果不存在的话
#对于VG-R和VG-A,这将是1GB大小的压缩zip文件——它是GQA的一个子集
vgr_dataset = VG_Relation(image_preprocess=preprocess,
download=True, root_dir=root_dir)
vga_dataset = VG_Attribution(image_preprocess=preprocess,
download=True, root_dir=root_dir)
#可以对数据集作任何处理。数据集中的每一项具有类似如下的形式:
# item = {"image_options": [image], "caption_options": [false_caption, true_caption]}
The above is the detailed content of Research on the possibility of building a visual language model from a set of words. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology