
Home >Technology peripherals >AI >Choosing the best GPU for deep learning
Choosing the best GPU for deep learning

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-20 17:04:061906browse
When working on machine learning projects, especially when dealing with deep learning and neural networks, it is better to work with a GPU rather than a CPU because even a very basic GPU will outperform a CPU when it comes to neural networks.

But which GPU should you buy? This article will summarize the relevant factors to consider so that you can make an informed choice based on your budget and specific modeling requirements.
Why is GPU better for machine learning than CPU?
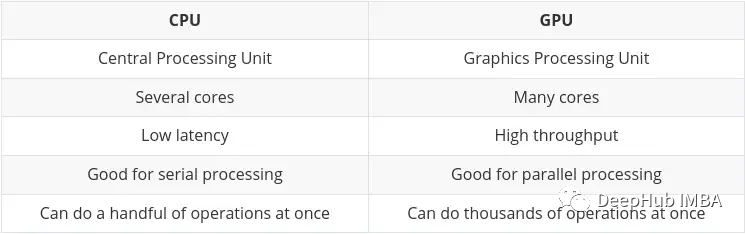
CPU (Central Processing Unit) is the main work of the computer. It is very flexible. It not only needs to process instructions from various programs and hardware, but also has certain processing speed requirements. To perform well in this multitasking environment, a CPU has a small number of flexible and fast processing units (also called cores).
GPU (Graphics Processing Unit) GPU is not as flexible when it comes to multitasking. But it can perform large amounts of complex mathematical calculations in parallel. This is achieved by having a larger number of simple cores (thousands to tens of thousands) that can handle many simple calculations simultaneously.
The requirement to perform multiple calculations in parallel is ideal for:
- Graphics rendering - moving graphics objects need to constantly calculate their trajectories, which requires a lot of parallel mathematics that is constantly repeated calculate.
- Machine and deep learning - a large number of matrix/tensor calculations, GPU can process in parallel.
- Any type of mathematical calculation can be split to run in parallel.
The main differences between CPU and GPU have been summarized on Nvidia's own blog:
Tensor Processing Unit (TPU)
With the development of artificial intelligence and machine/deep learning, there are now more specialized processing cores called tensor cores. They are faster and more efficient when performing tensor/matrix calculations. Because the data type we deal with in machine/deep learning is tensors.
Although there are dedicated TPUs, some of the latest GPUs also include many tensor cores, which we will summarize later.
Nvidia vs AMD
This will be a fairly short section as the answer to this question is definitely Nvidia
While it is possible to use AMD's GPUs for machine/deep learning, But at the time of writing this article, Nvidia's GPUs are more compatible and generally better integrated into tools such as TensorFlow and PyTorch (for example, PyTorch's support for AMD GPUs is currently only available on Linux).
Using AMD GPU requires the use of additional tools (ROCm), which will require some additional work, and the version may not be updated quickly. This situation may improve in the future, but for now, it's better to stick with Nvidia.
Main Attributes of GPU Selection
Selecting a GPU that is adequate for your machine learning tasks and fits your budget basically comes down to a balance of four main factors:
- How much memory does the GPU have?
- How many CUDA and/or tensor cores does the GPU have?
- What chip architecture does the card use?
- What are the power requirements, if any? ?
Let’s explore each of these aspects one by one, hoping to give you a better understanding of what is important to you.
GPU Memory
The answer is, the more the better!
It really depends on your task, and how big those models are. For example, if you are processing images, video, or audio, then by definition you will be processing a fairly large amount of data, and GPU RAM will be a very important consideration.
There are always ways to solve the problem of insufficient memory (such as reducing the batch size). But this will waste training time, so the needs need to be balanced well.
Based on experience, my suggestions are as follows:
- 4GB: I think this is the absolute minimum, as long as you are not dealing with overly complex models, or large images, videos Or audio, which works in most cases, but isn't adequate for daily use. If you're just starting out and want to try it out without going all in, you can start with
- 8GB: It's a great start for daily learning and can complete most tasks without exceeding the RAM limit, But problems can arise when working with more complex image, video or audio models.
- 12GB: I think this is the most basic requirement for scientific research. Can handle most larger models, even those working with images, video or audio.
- 12GB: The more the better, you will be able to handle larger data sets and larger batch sizes. Above 12GB is where prices really start to rise.
Generally speaking, if the cost is the same, it is better to choose a "slower" card with more memory. Keep in mind that the advantage of GPUs is high throughput, which relies heavily on available RAM to transfer data through the GPU.
CUDA core and Tensor core
This is actually very simple, the more the better.
Consider RAM first, then CUDA. For machine/deep learning, Tensor cores are better (faster, more efficient) than CUDA cores. This is because they are precisely designed for the computations required in the machine/deep learning field.
But this doesn't matter because the CUDA kernel is already fast enough. If you can get a card that includes Tensor cores, that's a great plus, just don't get too hung up on it.
You'll see "CUDA" mentioned many times later, so let's summarize it first:
CUDA Cores - These are the physical processors on the graphics card, and there are usually thousands of them , 4090 is already 16,000.
CUDA 11 - Numbers may change, but this refers to the software/drivers installed to allow the graphics card to function properly. NV releases new versions regularly, and it can be installed and updated like any other software.
CUDA Generation (or Compute Power) - This describes the code number of the graphics card in it's update iteration. This is fixed on the hardware, so can only be changed by upgrading to a new card. It is distinguished by numbers and a code name. Example: 3. x[Kepler],5. x[Maxwell], 6. x [Pascal], 7. x[Turing] and 8. x(Ampere).
Chip Architecture
This is actually more important than you think. We are not discussing AMD here, I only have "old yellow" in my eyes.
As we have said above, the 30 series cards are Ampere architecture, and the latest 40 series cards are Ada Lovelace. Usually Huang will name the architecture after a famous scientist and mathematician. This time he chose Ada Lovelace, the daughter of the famous British poet Byron, the female mathematician and founder of computer programs who established the concepts of loops and subroutines.
To understand the computing power of the card, we need to understand two aspects:
- Significant functional improvements
- An important function here is, mixed precision training :
There are many benefits to using a number format with less precision than 32-bit floating point. First they require less memory, allowing for the training and deployment of larger neural networks. Secondly they require less memory bandwidth, thus speeding up data transfer operations. Third math operations run faster with reduced precision, especially on GPUs with Tensor Cores. Mixed-precision training achieves all of these benefits while ensuring no loss of task-specific accuracy compared to full-precision training. It does this by identifying steps that require full precision and using 32-bit floating point only for those steps and 16-bit floating point everywhere else.
Here is the official Nvidia document. If you are interested, you can read it:
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
Mixed precision training is only possible if your GPU has a 7.x (Turing) or higher architecture. That means RTX 20 series or higher on the desktop, or "T" or "A" series on the server.
The main reason why mixed precision training has such advantages is that it reduces RAM usage. Tensor Core’s GPU will accelerate mixed precision training. If not, using FP16 will also save video memory and can train larger batch sizes. , indirectly improving the training speed.
Will it be abandoned
If you have particularly high requirements for RAM but don’t have enough money to buy a high-end card, then you may choose an older GPU on the second-hand market. There's a pretty big downside to this...the card's life is over.
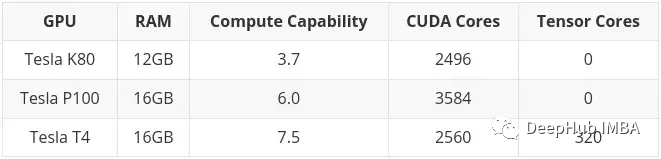
A typical example is the Tesla K80, which has 4992 CUDA cores and 24GB of RAM. In 2014, it retailed for about $7,000. The current price ranges from 150 to 170 US dollars! (The price of salted fish is around 600-700) You must be very excited to have such a large memory at such a small price.
But there is a very big problem. The computing architecture of K80 is 3.7 (Kepler), which is no longer supported starting from CUDA 11 (the current CUDA version is 11.7). This means that the card has expired, which is why it is sold so cheaply.
So when choosing a second-hand card, be sure to check whether it supports the latest version of the driver and CUDA. This is the most important thing.
High-end gaming cards VS workstation/server cards
Lao Huang basically divided the card into two parts. Consumer graphics cards and workstation/server graphics cards (i.e. professional graphics cards).
There is a clear difference between the two parts, for the same specs (RAM, CUDA cores, architecture) consumer graphics cards will generally be cheaper. But professional cards usually have better quality and lower energy consumption (in fact, the turbine noise is quite loud, which is fine when placed in a computer room, but a bit noisy when placed at home or in a laboratory).
High-end (very expensive) professional cards, you may notice that they have a lot of RAM (e.g. RTX A6000 has 48GB, A100 has 80GB!). This is because they typically target the 3D modeling, rendering, and machine/deep learning professional markets, which require high levels of RAM. Again, if you have money, just buy A100! (H100 is a new version of A100 and cannot be evaluated at present)
But I personally think that we should choose consumer high-end game cards, because if you don’t If you don’t have enough money, you won’t read this article, right
Select Suggestions
So at the end I make some suggestions based on budget and needs. I divided it into three parts:
- Low budget
- Medium budget
- High budget
High budget does not consider any Beyond high-end consumer graphics cards. Again, if you have money: buy A100 or H100.
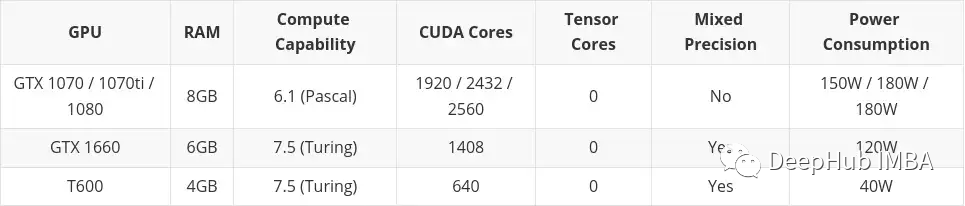
This article will include cards bought on the second-hand market. This is mainly because I think second hand is something to consider if you are on a low budget. The Professional Desktop Series cards (T600, A2000, and A4000) are also included here because some of its configurations are slightly worse than similar consumer graphics cards, but the power consumption is significantly better.
Low budget
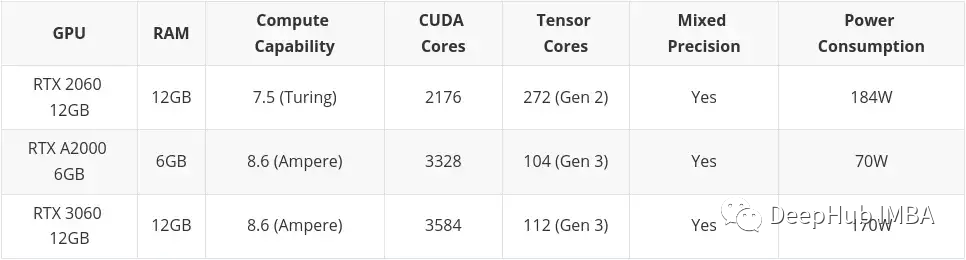
Medium budget
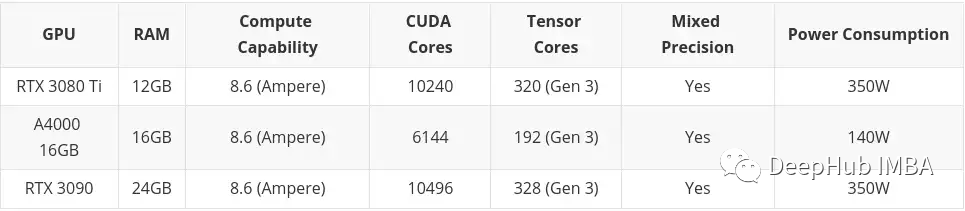
If you don’t buy it, I won’t buy it, and tomorrow it will be reduced by two hundred
The above is the detailed content of Choosing the best GPU for deep learning. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology