
Home >Technology peripherals >AI >ChatGPT programming accuracy dropped by 13%! UIUC & NTU's new benchmark makes AI code appear in its true form
ChatGPT programming accuracy dropped by 13%! UIUC & NTU's new benchmark makes AI code appear in its true form

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-17 14:58:131658browse

Writing code using ChatGPT has become a routine operation for many programmers.
△"At least 3~5 times faster"
But have you ever thought about whether the code generated by ChatGPT has any Doesn't it just "look accurate"?
A new study from the University of Illinois at Urbana-Champaign and Nanjing University shows that:
ChatGPT and GPT-4 generate code that is at least more accurate than previously assessed Reduced by 13%!

Some netizens lamented that too many ML papers are using some problematic or limited benchmarks to evaluate models. reached "SOTA" completely, and the original shape was revealed after changing the evaluation method.

# Some netizens said that this also shows that the code generated by large models still requires manual supervision. “The prime time for AI code writing has not yet arrived. ".

So, what kind of new evaluation method does the paper propose?
Make AI code test questions more difficult
This new method is called EvalPlus and is an automated code evaluation framework.
Specifically, it will make these evaluation benchmarks more rigorous by improving the input diversity and problem description accuracy of existing evaluation datasets.
On the one hand, it is input diversity. EvalPlus will first use ChatGPT to generate some seed input samples based on the standard answers (although the programming ability of ChatGPT needs to be tested, it does not seem inconsistent to use it to generate seed input)
Then, use EvalPlus to improve these seed inputs , making them harder, more complex, and more tricky.
The other aspect is the accuracy of problem description. EvalPlus will change the description of code requirements to be more precise. While constraining input conditions, it will supplement natural language problem descriptions to improve the accuracy requirements for model output.
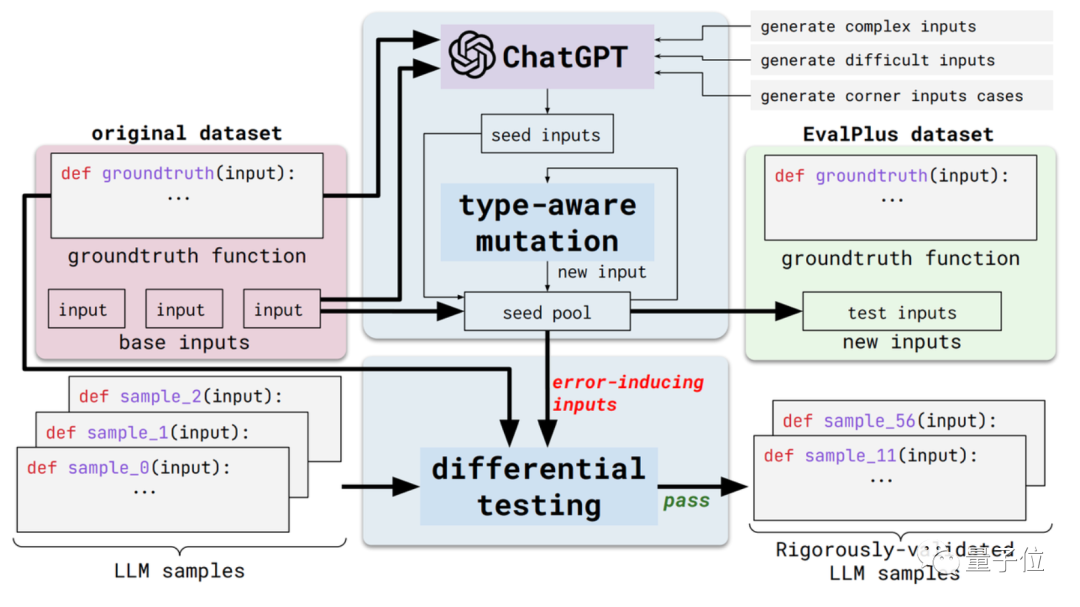
Here, the paper chooses the HUMANEVAL data set as a demonstration.
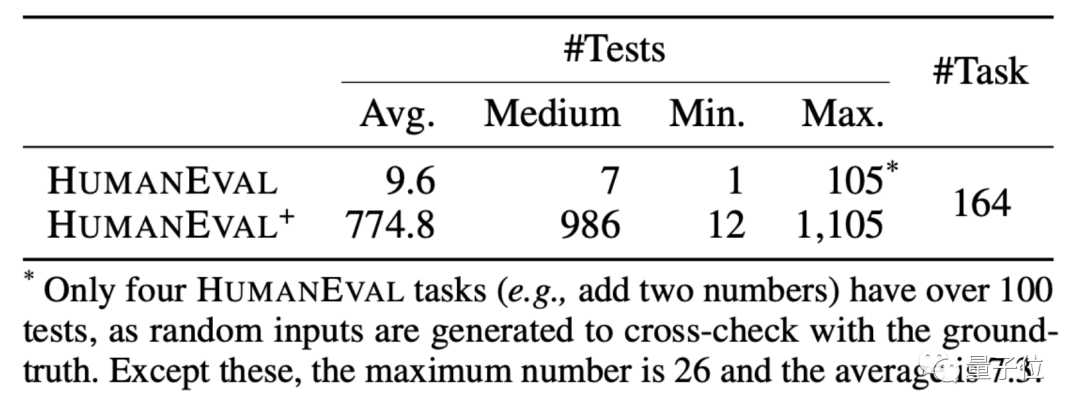
HUMANEVAL is a code data set produced by OpenAI and Anthropic AI. It contains 164 original programming questions, involving several types of questions in language understanding, algorithms, mathematics and software interviews.
EvalPlus will make programming problems look clearer by improving the input types and function descriptions of such data sets, while making the inputs used for testing more "tricky" or difficult.
Take one of the union set programming questions as an example. The AI is required to write a code to find the common elements in the two data lists and sort these elements.
EvalPlus uses it to test the accuracy of the code written by ChatGPT.
After conducting a simple input test, we found that ChatGPT can output accurate answers. But if you change the input, you will find the bug in the ChatGPT version of the code:

It is true that the test questions are more difficult for the AI.

Based on this method, EvalPlus also made an improved version of the HUMANEVAL data set. While adding input, it corrected some of the answers in HUMANEVAL. Problem programming questions.
So, under this "new set of test questions", how much will the accuracy of the large language models actually be discounted?
LLM code accuracy is reduced by 15% on average
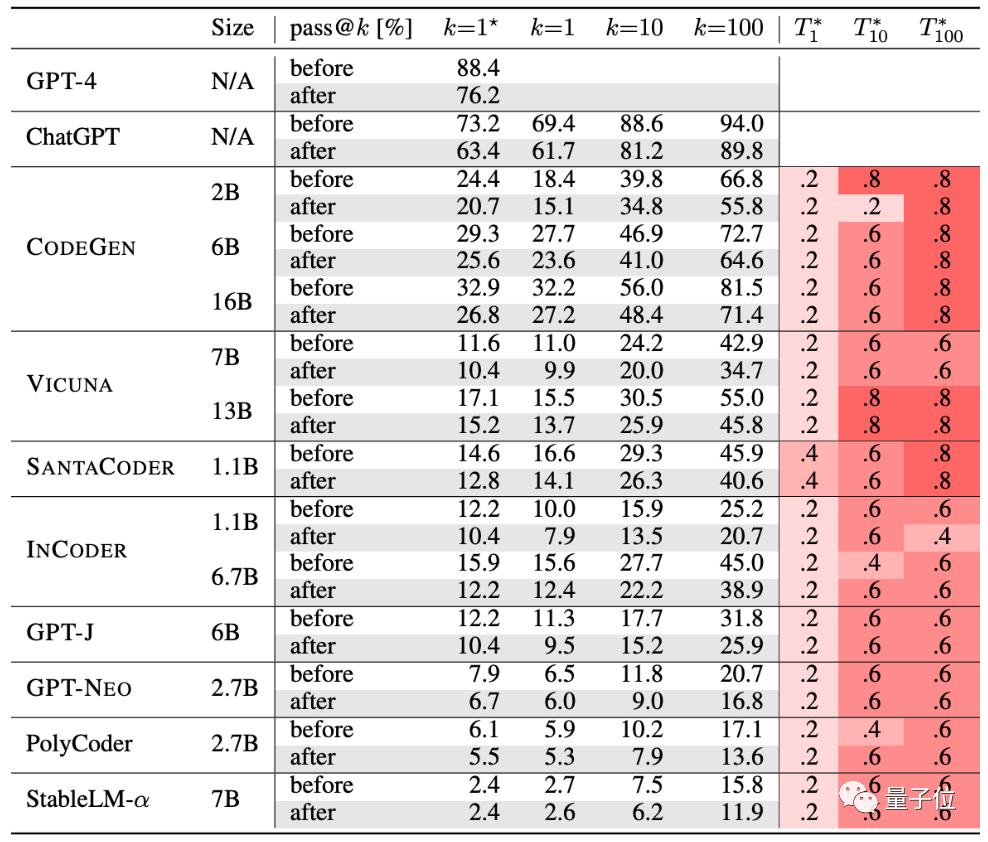
The authors tested 10 currently popular code generation AIs.
GPT-4, ChatGPT, CODEGEN, VICUNA, SANTACODER, INCODER, GPT-J, GPT-NEO, PolyCoder, StableLM-α.
Judging from the table, after rigorous testing, the generation accuracy of this group of AIs has declined:
The accuracy will be evaluated here through a method called pass@k, where k is the number of programs that allow a large model to be generated for the problem, n is the number of inputs used for testing, and c is the number of correct inputs:
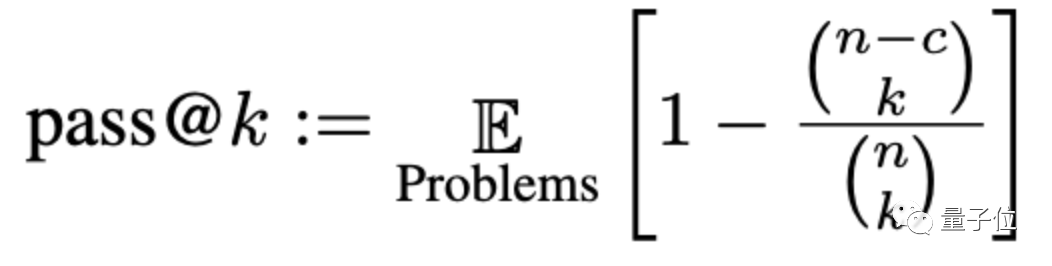
#According to the new set of evaluation standards, the accuracy of large models dropped by 15% on average, and the more widely studied CODEGEN-16B dropped even more. more than 18%.
As for the performance of ChatGPT and GPT-4 generated code, it has also dropped by at least 13%.
However, some netizens said that it is a "well-known fact" that the code generated by large models is not that good, and what needs to be studied is "why the code written by large models cannot be used."
The above is the detailed content of ChatGPT programming accuracy dropped by 13%! UIUC & NTU's new benchmark makes AI code appear in its true form. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology