
Home >Technology peripherals >AI >AI Stefanie Sun's cover became a hit, thanks to this open source project! Guangxi Laobiao took the lead in creating it, and a guide to get started has been released
AI Stefanie Sun's cover became a hit, thanks to this open source project! Guangxi Laobiao took the lead in creating it, and a guide to get started has been released

- 王林forward
- 2023-05-12 14:07:061078browse
AI Stefanie Sun has covered so many songs so quickly, how did she achieve it?
The key lies in an open source project.
Recently, this wave of AI cover trend has become popular. Not only is AI Stefanie Sun singing more and more songs, but the range of AI singers is also It is expanding, and even production tutorials are emerging one after another.
And if you take a stroll through the major tutorials, you will find that the key secret lies in an open source project called so-vits-svc.
It provides a way to replace sounds. The project was released in March this year.
Most of the contributing members should come from China, and the one with the highest contribution is a veteran from Guangxi who plays Arknights.
Now, the project has stopped updating, but the number of stars is still rising, currently reaching 8.4k.
So what technologies has it implemented that can detonate this trend?
Let’s see together.
Thanks to an open source project
This project is calledSoftVC VITS Singing Voice Conversion(singing voice conversion).
It provides a timbre conversion algorithm that uses the SoftVC content encoder to extract the voice features of the source audio, and then directly inputs the vector into VITS without converting it to text in the middle, thus retaining the pitch and intonation.
In addition, the vocoder was changed to NSF HiFiGAN, which can solve the problem of sound interruption.
It is divided into the following steps:
- Pre-training model
- Prepare the data set
- Pre-processing
- Training
- Inference
Among them, the pre-training model step is one of the key, because the project itself does not provide any timbre audio training model, so if you want to be a new AI singer Come out, you need to train the model yourself.
The first step in pre-training the model is to prepare dry voices, which are pure human voices without music.
The tools used by many bloggers are UVR_v5.5.0.
Twitter blogger @Guizang said that it is best to convert the sound format to WAV format before processing, because So-VITS-SVC 4.0 only recognizes this format to facilitate subsequent processing.
If you want a better effect, you need to process the background sound twice, with different settings each time, which can maximize the quality of the dry sound.
After obtaining the processed audio, some preprocessing operations are required.
For example, if the audio is too long, it will easily overflow the video memory, and the audio needs to be sliced. It is recommended that 5-15 seconds or longer is fine.
Then resample to 44100Hz and mono, and automatically divide the data set into a training set and a validation set to generate a configuration file. Regenerate Hubert and f0.
Next you can start training and inference.
For specific steps, you can go to the GitHub project page to view (end of guide) .
It is worth mentioning that this project was launched in March this year and currently has 25 contributors. Judging from the profiles of contributing users, many should be from China.
It is said that when the project was first launched, there were many loopholes and required programming. However, people were updating and patching it almost every day, and now the threshold for use has been lowered a lot.
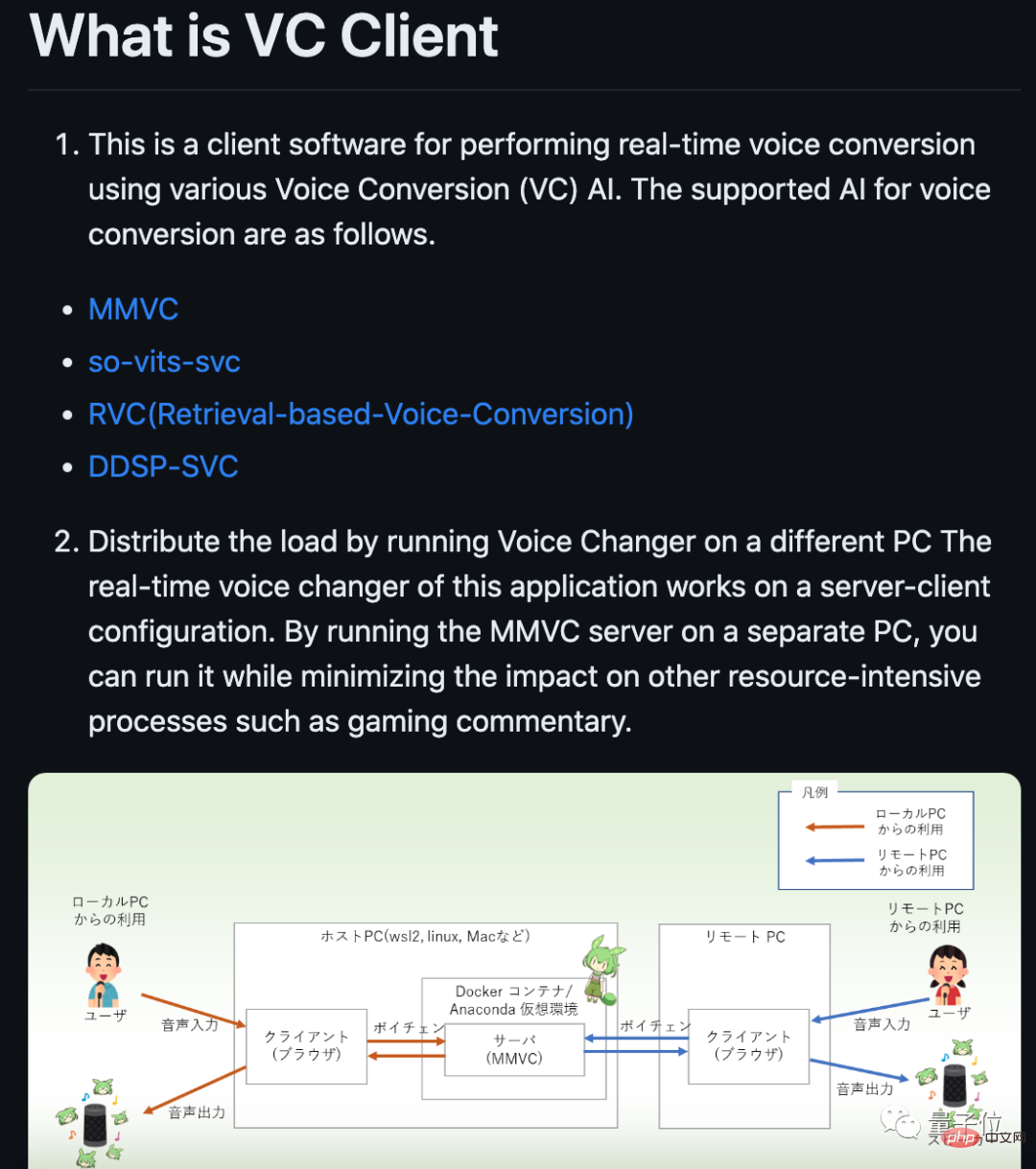
Currently, the project has stopped updating, but some developers have still created new branches. For example, some people have made a client that supports real-time conversion.
The developer who has contributed the most to the project is Miuzarte. Judging from the profile address, he should be from Guangxi.
As more and more people want to get started, many bloggers have launched more detailed eating guides that are easier to get started with. .
The recommended method for Guizang is to use an integrated package for inference (using a model) and training. Jack-Cui from Station B showed a step-by-step guide under Windows (https://www.bilibili .com/read/cv22375562).
It should be noted that model training requires relatively high graphics cards, and various problems may occur if the graphics memory is less than 6G.
Jack-Cui recommended using N card. He used RTX 2060 S. It took about 14 hours to train his model.
Training data is also critical. The more high-quality audio, the better the final effect will be.
Still worried about copyright issues
It is worth mentioning that on the project homepage of so-vits-svc, copyright issues are emphasized.
Warning: Please solve the authorization problem of the data set yourself. You are solely responsible for any problems arising from the use of unauthorized data sets for training and all consequences thereof. The repository, its maintainers, and the svc development team have nothing to do with the generated results!

This is somewhat similar to when AI painting became popular .
Because the initial data for AI-generated content is based on human works, there are endless debates over copyright.
And with the popularity of AI works, some copyright owners have taken action to remove videos from the platform.
It is understood that an AI-synthesized song "Heart on My Sleeve" became popular on Tik Tok. It synthesized the version sung by Drake and Weekend.
But then, Drake and Weekend’s record company, Universal Music, removed the video from the platform and asked potential counterfeiters in a statement, “We stand on the side of artists, fans and human creative expression. On the other side, or on the side of deepfakes, fraud and refusal to pay artist compensation?"
In addition, singer Drake expressed dissatisfaction with AI-synthesized cover songs.
On the other side, some people choose to embrace this technology.
Canadian singer Grimes said that she is willing to let others use her voice to synthesize songs, but she must pay half of the royalties.
GitHub address: https://github.com/svc-develop-team/so-vits-svc
The above is the detailed content of AI Stefanie Sun's cover became a hit, thanks to this open source project! Guangxi Laobiao took the lead in creating it, and a guide to get started has been released. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology